Problem Solving Vs. Planning
Problem Solving vs. Planning : A simple planning agent is very similar to problem-solving agents in that it constructs plans that achieve its goals, and then executes them. The limitations of the problem-solving approach motivates the design of planning systems.
To solve a planning problem using a state-space search approach we would let the:
- initial state = initial situation
- goal-test predicate = goal state description
- successor function computed from the set of operators
- once a goal is found, solution plan is the sequence of operators in the path from the start node to the goal node
In searches, operators are used simply to generate successor states and we can not look "inside" an operator to see how it’s defined. The goal-test predicate also is used as a "black box" to test if a state is a goal or not. The search cannot use properties of how a goal is defined in order to reason about finding path to that goal. Hence this approach is all algorithm and representation weak.
Planning is considered different from problem solving because of the difference in the way they represent states, goals, actions, and the differences in the way they construct action sequences.
Remember the search-based problem solver had four basic elements:
- Representations of actions: programs that develop successor state descriptions which represent actions.
- Representation of state: every state description is complete. This is because a complete description of the initial state is given, and actions are represented by a program that creates complete state descriptions.
- Representation of goals: a problem solving agent has only information about it's goal, which is in terms of a goal test and the heuristic function.
- Representation of plans: in problem solving, the solution is a sequence of actions.
In a simple problem: "Get a quart of milk and a bunch of bananas and a variable speed cordless drill" for a problem solving exercise we need to specify: Initial State: the agent is at home without any objects that he is wanting.
Operator Set: everything the agent can do.
Heuristic function: the # of things that have not yet been acquired.
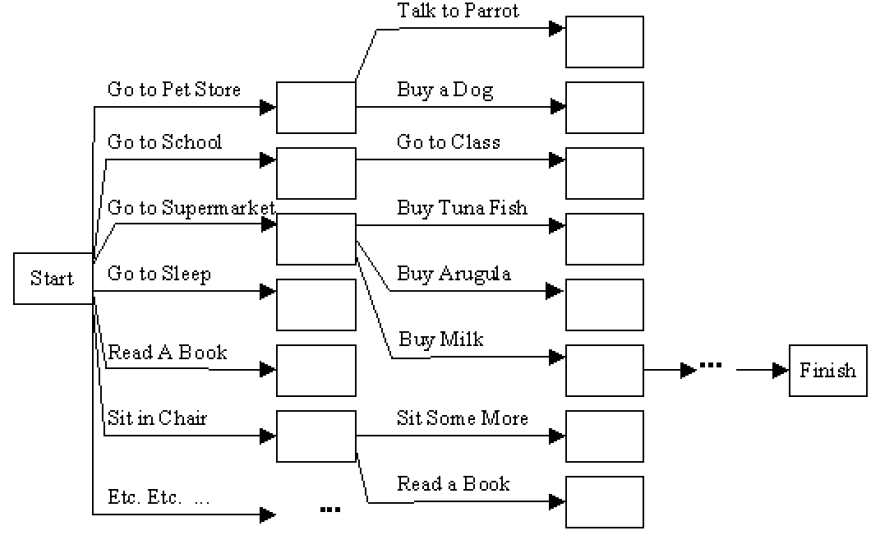
Problems with Problem solving agent:
- It is evident from the above figure that the actual branching factor would be in the thousands or millions. The heuristic evaluation function can only choose states to determine which one is closer to the goal. It cannot eliminate actions from consideration. The agent makes guesses by considering actions and the evaluation function ranks those guesses. The agent picks the best guess, but then has no idea what to try next and therefore starts guessing again.
- It considers sequences of actions beginning from the initial state. The agent is forced to decide what to do in the initial state first, where possible choices are to go to any of the next places. Until the agent decides how to acquire the objects, it can't decide where to go.
Planning emphasizes what is in operator and goal representations. There are three key ideas behind planning:
- to "open up" the representations of state, goals, and operators so that a reasoner can more intelligently select actions when they are needed
- the planner is free to add actions to the plan wherever they are needed, rather than in an incremental sequence starting at the initial state.
- most parts of the world are independent of most other parts which makes it feasible to take a conjunctive goal and solve it with a divide-and-conquer strategy.

Problem-Solving Agents In Artificial Intelligence

In artificial intelligence, a problem-solving agent refers to a type of intelligent agent designed to address and solve complex problems or tasks in its environment. These agents are a fundamental concept in AI and are used in various applications, from game-playing algorithms to robotics and decision-making systems. Here are some key characteristics and components of a problem-solving agent:
- Perception : Problem-solving agents typically have the ability to perceive or sense their environment. They can gather information about the current state of the world, often through sensors, cameras, or other data sources.
- Knowledge Base : These agents often possess some form of knowledge or representation of the problem domain. This knowledge can be encoded in various ways, such as rules, facts, or models, depending on the specific problem.
- Reasoning : Problem-solving agents employ reasoning mechanisms to make decisions and select actions based on their perception and knowledge. This involves processing information, making inferences, and selecting the best course of action.
- Planning : For many complex problems, problem-solving agents engage in planning. They consider different sequences of actions to achieve their goals and decide on the most suitable action plan.
- Actuation : After determining the best course of action, problem-solving agents take actions to interact with their environment. This can involve physical actions in the case of robotics or making decisions in more abstract problem-solving domains.
- Feedback : Problem-solving agents often receive feedback from their environment, which they use to adjust their actions and refine their problem-solving strategies. This feedback loop helps them adapt to changing conditions and improve their performance.
- Learning : Some problem-solving agents incorporate machine learning techniques to improve their performance over time. They can learn from experience, adapt their strategies, and become more efficient at solving similar problems in the future.
Problem-solving agents can vary greatly in complexity, from simple algorithms that solve straightforward puzzles to highly sophisticated AI systems that tackle complex, real-world problems. The design and implementation of problem-solving agents depend on the specific problem domain and the goals of the AI application.

Hello, I’m Hridhya Manoj. I’m passionate about technology and its ever-evolving landscape. With a deep love for writing and a curious mind, I enjoy translating complex concepts into understandable, engaging content. Let’s explore the world of tech together
Which Of The Following Is A Privilege In SQL Standard
Implicit Return Type Int In C
Leave a Comment Cancel reply
Save my name, email, and website in this browser for the next time I comment.
Reach Out to Us for Any Query
SkillVertex is an edtech organization that aims to provide upskilling and training to students as well as working professionals by delivering a diverse range of programs in accordance with their needs and future aspirations.
© 2024 Skill Vertex
Planning Agents
Cite this chapter.

- John L. Pollock 5
Part of the book series: Applied Logic Series ((APLS,volume 14))
406 Accesses
3 Citations
Agents are entities that act upon the world. Rational agents are those that do so in an intelligent fashion. What is essential to such an agent is the ability to select and perform actions. Actions are selected by planning, and performing such actions is a matter of plan execution. So the essence of a rational agent is the ability to make and execute plans. This constitutes practical cognition . In order to perform its principal function of practical cognition, a rational agent must also be able to acquire the knowledge of the world that is required for making and executing plans. This is done by epistemic cognition . Rational agents embedded in a realistically complicated world (e.g., human beings) may devote more time to epistemic cognition than to practical cognition, but even for such agents, epistemic cognition is in an important sense subservient to practical cognition.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
- Durable hardcover edition
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Unable to display preview. Download preview PDF.
Michael Beetz and Drew McDermott. Local planning of ongoing activities. In Brian Drabble, editor, Proceedings of the Third International Conference on Artificial Intelligence Planning Systems . AAAI Press, 1996.
Google Scholar
M. Bratman, D. Isreal, and M. Pollack. Plans and resource-bounded practical reasoning. Computational Intelligence , 4: 349–355, 1988.
Article Google Scholar
R. E. Fikes and N. J. Nilsson. Strips: a new approach to the application of theorem proving to problem solving. Artificial Intelligence , 2: 189–208, 1971.
Michael Gelfond and Vladimir Lifschitz. Representing action and change by logic programs. Journal of Logic Programming , 17: 301–322, 1993.
Michael Georgeff and Amy Lansky. Reactive reasoning and planning. In Proceedings AMI-87 , pages 677–682, 1987.
C. Green. Application of theorem-proving to problem solving. In Proceedings IJCAI-69 , pages 219–239, 1969.
Steve Hanks and Drew McDermott. Default reasoning, nonmonotonic logics, and the frame problem. AAAI-86 , 1986.
David Lewis. Counterfactuals . Harvard University Press, Cambrdige, Mass, 1973.
Fangzhen Lin and Raymond Reiter. How to progress a database (and why) i. logical foundations. In Proceedings of the Fourth International Conference on Principles of Knowledge Representation (KR94) , pages 425–436, 1994.
Fangzhen Lin and Raymond Reiter. How to progress a database ii: The strips connection. IJCAI-95 , pages 2001–2007, 1995.
David McAllester and David Rosenblitt. Systematic nonlinear planning. In Proceedings ofAAAI91 , pages 634–639, 1991.
John McCarthy. Epistemological problems in artificial intelligence. In Proceedings IJCA-77 , 1977.
J. Scott Penberthy and Daniel Weld. Ucpop: a sound, complete, partial order planner for adl. In Proceedings 3rd International Conference on Principles of Knowledge Representation and Reasoning , pages 103–114, 1992.
John Pollock. The Foundations of Philosophical Semantics . Princeton University Press, 1984.
John Pollock. Contemporary Theories of Knowledge . Rowman and Littlefield, 1987.
John Pollock. Oscar: a general theory of rationality. Journal of Experimental and Theoretical AI , 1: 209–226, 1990.
John Pollock. New foundations for practical reasoning. Minds and Machines , 2: 113–144, 1992.
John Pollock. Cognitive Carpentry . MIT Press, 1995.
John Pollock. Perceiving and reasoning about a changing world. technical report of the oscar project., 1996. This can be downloaded from http://www.u.arizona.edu/~pollock/.
John Pollock. Reason in a changing world. In Dov M. Gabbay and Hans Jürgen Ohlbach, editors, Practical Reasoning: Internaltional Conference on Formal and Applied Practical Reasoning , pages 495–509, 1996.
E. D. Sacerdotti. The non-linear nature of plans. In Proceedings IJCAI-75 , 1975.
E. D. Sacerdotti. A Structure of Plans and Behavior . Elsevier-North Holland, Amsterdam, 1977.
Murray Shanahan. Robotics and the common sense informatic situation. In Proceedings of the 12th European Conference on Artificial Intelligence . John Wiley & Sons, 1996.
Yoav Shoham. Reasoning about Change . MIT Press, 1987.
Manuela Veloso, Jaime Carbonell, Alicia Perez, Daniel Borrajo, Eugene Fink, and Jim Blythe. Integratin planning and learning: the prodigy architecture. Journal of Experimental and Theoretical Artificial Intelligence , 7, 1995.
S. Vere and T. Bickmore. A basic agent. Computational Intelligence , 6: 41–60, 1990.
Daniel Weld. An introduction to least commitment planning. Al Magazine , 15: 27–62, 1994.
M. Wooldridge and N. R. Jennings. Intelligent agents: theory and practice. The Knowledge Engineering Review , 10:115–152 , 1995.
Download references
Author information
Authors and affiliations.
University of Arizona, Tucson, USA
John L. Pollock
You can also search for this author in PubMed Google Scholar
Editor information
Editors and affiliations.
Queen Mary and Westfield College, London, UK
Michael Wooldridge
Mitchell Madison Group, Melbourne, Australia
Rights and permissions
Reprints and permissions
Copyright information
© 1999 Springer Science+Business Media Dordrecht
About this chapter
Pollock, J.L. (1999). Planning Agents. In: Wooldridge, M., Rao, A. (eds) Foundations of Rational Agency. Applied Logic Series, vol 14. Springer, Dordrecht. https://doi.org/10.1007/978-94-015-9204-8_4
Download citation
DOI : https://doi.org/10.1007/978-94-015-9204-8_4
Publisher Name : Springer, Dordrecht
Print ISBN : 978-90-481-5177-6
Online ISBN : 978-94-015-9204-8
eBook Packages : Springer Book Archive
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
references.bib
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
This survey paper examines the recent advancements in AI agent implementations, with a focus on their ability to achieve complex goals that require enhanced reasoning, planning, and tool execution capabilities. The primary objectives of this work are to a) communicate the current capabilities and limitations of existing AI agent implementations, b) share insights gained from our observations of these systems in action, and c) suggest important considerations for future developments in AI agent design. We achieve this by providing overviews of single-agent and multi-agent architectures, identifying key patterns and divergences in design choices, and evaluating their overall impact on accomplishing a provided goal. Our contribution outlines key themes when selecting an agentic architecture, the impact of leadership on agent systems, agent communication styles, and key phases for planning, execution, and reflection that enable robust AI agent systems.
K eywords AI Agent ⋅ ⋅ \cdot ⋅ Agent Architecture ⋅ ⋅ \cdot ⋅ AI Reasoning ⋅ ⋅ \cdot ⋅ Planning ⋅ ⋅ \cdot ⋅ Tool Calling ⋅ ⋅ \cdot ⋅ Single Agent ⋅ ⋅ \cdot ⋅ Multi Agent ⋅ ⋅ \cdot ⋅ Agent Survey ⋅ ⋅ \cdot ⋅ LLM Agent ⋅ ⋅ \cdot ⋅ Autonomous Agent
1 Introduction
Since the launch of ChatGPT, many of the first wave of generative AI applications have been a variation of a chat over a corpus of documents using the Retrieval Augmented Generation (RAG) pattern. While there is a lot of activity in making RAG systems more robust, various groups are starting to build what the next generation of AI applications will look like, centralizing on a common theme: agents.
Beginning with investigations into recent foundation models like GPT-4 and popularized through open-source projects like AutoGPT and BabyAGI, the research community has experimented with building autonomous agent-based systems [ nakajima_yoheinakajimababyagi_2024 , birr_autogptp_2024 ] .
As opposed to zero-shot prompting of a large language model where a user types into an open-ended text field and gets a result without additional input, agents allow for more complex interaction and orchestration. In particular, agentic systems have a notion of planning, loops, reflection and other control structures that heavily leverage the model’s inherent reasoning capabilities to accomplish a task end-to-end. Paired with the ability to use tools, plugins, and function calling, agents are empowered to do more general-purpose work.
Among the community, there is a current debate on whether single or multi-agent systems are best suited for solving complex tasks. While single agent architectures excel when problems are well-defined and feedback from other agent-personas or the user is not needed, multi-agent architectures tend to thrive more when collaboration and multiple distinct execution paths are required.

1.1 Taxonomy
Agents . AI agents are language model-powered entities able to plan and take actions to execute goals over multiple iterations. AI agent architectures are either comprised of a single agent or multiple agents working together to solve a problem.
Typically, each agent is given a persona and access to a variety of tools that will help them accomplish their job either independently or as part of a team. Some agents also contain a memory component, where they can save and load information outside of their messages and prompts. In this paper, we follow the definition of agent that consists of “brain, perception, and action” [ xi2023rise ] . These components satisfy the minimum requirements for agents to understand, reason, and act on the environment around them.
Agent Persona . An agent persona describes the role or personality that the agent should take on, including any other instructions specific to that agent. Personas also contain descriptions of any tools the agent has access to. They make the agent aware of their role, the purpose of their tools, and how to leverage them effectively. Researchers have found that “shaped personality verifiably influences Large Language Model (LLM) behavior in common downstream (i.e. subsequent) tasks, such as writing social media posts” [ serapiogarcía2023personality ] . Solutions that use multiple agent personas to solve problems also show significant improvements compared to Chain-of-Thought (CoT) prompting where the model is asked to break down its plans step by step [ wang2024unleashing , wei_chain--thought_2023 ] .
Tools . In the context of AI agents, tools represent any functions that the model can call. They allow the agent to interact with external data sources by pulling or pushing information to that source. An example of an agent persona and associated tools is a professional contract writer. The writer is given a persona explaining their role and the types of tasks it must accomplish. It is also given tools related to adding notes to a document, reading an existing document, or sending an email with a final draft.
Single Agent Architectures . These architectures are powered by one language model and will perform all the reasoning, planning, and tool execution on their own. The agent is given a system prompt and any tools required to complete their task. In single agent patterns there is no feedback mechanism from other AI agents; however, there may be options for humans to provide feedback that guides the agent.
Multi-Agent Architectures . These architectures involve two or more agents, where each agent can utilize the same language model or a set of different language models. The agents may have access to the same tools or different tools. Each agent typically has their own persona.
Multi-agent architectures can have a wide variety of organizations at any level of complexity. In this paper, we divide them into two primary categories: vertical and horizontal. It is important to keep in mind that these categories represent two ends of a spectrum, where most existing architectures fall somewhere between these two extremes.
Vertical Architectures . In this structure, one agent acts as a leader and has other agents report directly to them. Depending on the architecture, reporting agents may communicate exclusively with the lead agent. Alternatively, a leader may be defined with a shared conversation between all agents. The defining features of vertical architectures include having a lead agent and a clear division of labor between the collaborating agents.
Horizontal Architectures . In this structure, all the agents are treated as equals and are part of one group discussion about the task. Communication between agents occurs in a shared thread where each agent can see all messages from the others. Agents also can volunteer to complete certain tasks or call tools, meaning they do not need to be assigned by a leading agent. Horizontal architectures are generally used for tasks where collaboration, feedback and group discussion are key to the overall success of the task [ chen_agentverse_2023 ] .
2 Key Considerations for Effective Agents
2.1 overview.
Agents are designed to extend language model capabilities to solve real-world challenges. Successful implementations require robust problem-solving capabilities enabling agents to perform well on novel tasks. To solve real-world problems effectively, agents require the ability to reason and plan as well as call tools that interact with an external environment. In this section we explore why reasoning, planning, and tool calling are critical to agent success.
2.2 The Importance of Reasoning and Planning
Reasoning is a fundamental building block of human cognition, enabling people to make decisions, solve problems, and understand the world around us. AI agents need a strong ability to reason if they are to effectively interact with complex environments, make autonomous decisions, and assist humans in a wide range of tasks. This tight synergy between “acting” and “reasoning” allows new tasks to be learned quickly and enables robust decision making or reasoning, even under previously unseen circumstances or information uncertainties [ yao_react_2023 ] . Additionally, agents need reasoning to adjust their plans based on new feedback or information learned.
If agents lacking reasoning skills are tasked with acting on straightforward tasks, they may misinterpret the query, generate a response based on a literal understanding, or fail to consider multi-step implications.
Planning, which requires strong reasoning abilities, commonly falls into one of five major approaches: task decomposition, multi-plan selection, external module-aided planning, reflection and refinement and memory-augmented planning [ huang2024understanding ] . These approaches allow the model to either break the task down into sub tasks, select one plan from many generated options, leverage a preexisting external plan, revise previous plans based on new information, or leverage external information to improve the plan.
Most agent patterns have a dedicated planning step which invokes one or more of these techniques to create a plan before any actions are executed. For example, Plan Like a Graph (PLaG) is an approach that represents plans as directed graphs, with multiple steps being executed in parallel [ lin_graph-enhanced_2024 , yao_tree_2023 ] . This can provide a significant performance increase over other methods on tasks that contain many independent subtasks that benefit from asynchronous execution.
2.3 The Importance of Effective Tool Calling
One key benefit of the agent abstraction over prompting base language models is the agents’ ability to solve complex problems by calling multiple tools. These tools enable the agent to interact with external data sources, send or retrieve information from existing APIs, and more. Problems that require extensive tool calling often go hand in hand with those that require complex reasoning.
Both single-agent and multi-agent architectures can be used to solve challenging tasks by employing reasoning and tool calling steps. Many methods use multiple iterations of reasoning, memory, and reflection to effectively and accurately complete problems [ liu_llm_2024 , shinn_reflexion_2023 , yao_react_2023 ] . They often do this by breaking a larger problem into smaller subproblems, and then solving each one with the appropriate tools in sequence.
Other works focused on advancing agent patterns highlight that while breaking a larger problem into smaller subproblems can be effective at solving complex tasks, single agent patterns often struggle to complete the long sequence required [ shi_learning_2024 , gao_efficient_2024 ] .
Multi-agent patterns can address the issues of parallel tasks and robustness since individual agents can work on individual subproblems. Many multi-agent patterns start by taking a complex problem and breaking it down into several smaller tasks. Then, each agent works independently on solving each task using their own independent set of tools.
3 Single Agent Architectures
3.1 overview.
In this section, we highlight some notable single agent methods such as ReAct, RAISE, Reflexion, AutoGPT + P, and LATS. Each of these methods contain a dedicated stage for reasoning about the problem before any action is taken to advance the goal. We selected these methods based on their contributions to the reasoning and tool calling capabilities of agents.
3.2 Key Themes
We find that successful goal execution by agents is contingent upon proper planning and self-correction [ yao_react_2023 , liu_llm_2024 , shinn_reflexion_2023 , birr_autogptp_2024 ] . Without the ability to self-evaluate and create effective plans, single agents may get stuck in an endless execution loop and never accomplish a given task or return a result that does not meet user expectations [ yao_react_2023 ] . We find that single agent architectures are especially useful when the task requires straightforward function calling and does not need feedback from another agent [ shi_learning_2024 ] .
3.3 Examples
ReAct. In the ReAct (Reason + Act) method, an agent first writes a thought about the given task. It then performs an action based on that thought, and the output is observed. This cycle can repeat until the task is complete [ yao_react_2023 ] . When applied to a diverse set of language and decision-making tasks, the ReAct method demonstrates improved effectiveness compared to zero-shot prompting on the same tasks. It also provides improved human interoperability and trustworthiness because the entire thought process of the model is recorded. When evaluated on the HotpotQA dataset, the ReAct method only hallucinated 6% of the time, compared to 14% using the chain of thought (CoT) method [ wei_chain--thought_2023 , yao_react_2023 ] .
However, the ReAct method is not without its limitations. While intertwining reasoning, observation, and action improves trustworthiness, the model can repetitively generate the same thoughts and actions and fail to create new thoughts to provoke finishing the task and exiting the ReAct loop. Incorporating human feedback during the execution of the task would likely increase its effectiveness and applicability in real-world scenarios.
RAISE. The RAISE method is built upon the ReAct method, with the addition of a memory mechanism that mirrors human short-term and long-term memory [ liu_llm_2024 ] . It does this by using a scratchpad for short-term storage and a dataset of similar previous examples for long-term storage.
By adding these components, RAISE improves upon the agent’s ability to retain context in longer conversations. The paper also highlights how fine-tuning the model results in the best performance for their task, even when using a smaller model. They also showed that RAISE outperforms ReAct in both efficiency and output quality.
While RAISE significantly improves upon existing methods in some respects, the researchers also highlighted several issues. First, RAISE struggles to understand complex logic, limiting its usefulness in many scenarios. Additionally, RAISE agents often hallucinated with respect to their roles or knowledge. For example, a sales agent without a clearly defined role might retain the ability to code in Python, which may enable them to start writing Python code instead of focusing on their sales tasks. These agents might also give the user misleading or incorrect information. This problem was addressed by fine-tuning the model, but the researchers still highlighted hallucination as a limitation in the RAISE implementation.
Reflexion. Reflexion is a single-agent pattern that uses self-reflection through linguistic feedback [ shinn_reflexion_2023 ] . By utilizing metrics such as success state, current trajectory, and persistent memory, this method uses an LLM evaluator to provide specific and relevant feedback to the agent. This results in an improved success rate as well as reduced hallucination compared to Chain-of-Thought and ReAct.
Despite these advancements, the Reflexion authors identify various limitations of the pattern. Primarily, Reflexion is susceptible to “non-optimal local minima solutions”. It also uses a sliding window for long-term memory, rather than a database. This means that the volume of long-term memory is limited by the token limit of the language model. Finally, the researchers identify that while Reflexion surpasses other single-agent patterns, there are still opportunities to improve performance on tasks that require a significant amount of diversity, exploration, and reasoning.
AUTOGPT + P. AutoGPT + P (Planning) is a method that addresses reasoning limitations for agents that command robots in natural language [ birr_autogptp_2024 ] . AutoGPT+P combines object detection and Object Affordance Mapping (OAM) with a planning system driven by a LLM. This allows the agent to explore the environment for missing objects, propose alternatives, or ask the user for assistance with reaching its goal.
AutoGPT+P starts by using an image of a scene to detect the objects present. A language model then uses those objects to select which tool to use, from four options: Plan Tool, Partial Plan Tool, Suggest Alternative Tool, and Explore Tool. These tools allow the robot to not only generate a full plan to complete the goal, but also to explore the environment, make assumptions, and create partial plans.
However, the language model does not generate the plan entirely on its own. Instead, it generates goals and steps to work aside a classical planner which executes the plan using Planning Domain Definition Language (PDDL). The paper found that “LLMs currently lack the ability to directly translate a natural language instruction into a plan for executing robotic tasks, primarily due to their constrained reasoning capabilities” [ birr_autogptp_2024 ] . By combining the LLM planning capabilities with a classical planner, their approach significantly improves upon other purely language model-based approaches to robotic planning.
As with most first of their kind approaches, AutoGPT+P is not without its drawbacks. Accuracy of tool selection varies, with certain tools being called inappropriately or getting stuck in loops. In scenarios where exploration is required, the tool selection sometimes leads to illogical exploration decisions like looking for objects in the wrong place. The framework also is limited in terms of human interaction, with the agent being unable to seek clarification and the user being unable to modify or terminate the plan during execution.

LATS. Language Agent Tree Search (LATS) is a single-agent method that synergizes planning, acting, and reasoning by using trees [ zhou_language_2023 ] . This technique, inspired by Monte Carlo Tree Search, represents a state as a node and taking an action as traversing between nodes. It uses LM-based heuristics to search for possible options, then selects an action using a state evaluator.
When compared to other tree-based methods, LATS implements a self-reflection reasoning step that dramatically improves performance. When an action is taken, both environmental feedback as well as feedback from a language model is used to determine if there are any errors in reasoning and propose alternatives. This ability to self-reflect combined with a powerful search algorithm makes LATS perform extremely well on various tasks.
However, due to the complexity of the algorithm and the reflection steps involved, LATS often uses more computational resources and takes more time to complete than other single-agent methods [ zhou_language_2023 ] . The paper also uses relatively simple question answering benchmarks and has not been tested on more robust scenarios that involve involving tool calling or complex reasoning.
4 Multi Agent Architectures
4.1 overview.
In this section, we examine a few key studies and sample frameworks with multi-agent architectures, such as Embodied LLM Agents Learn to Cooperate in Organized Teams, DyLAN, AgentVerse, and MetaGPT. We highlight how these implementations facilitate goal execution through inter-agent communication and collaborative plan execution. This is not intended to be an exhaustive list of all agent frameworks, our goal is to provide broad coverage of key themes and examples related to multi-agent patterns.
4.2 Key Themes
Multi-agent architectures create an opportunity for both the intelligent division of labor based on skill and helpful feedback from a variety of agent personas. Many multi-agent architectures work in stages where teams of agents are created and reorganized dynamically for each planning, execution, and evaluation phase [ chen_agentverse_2023 , guo2024embodied , liu2023dynamic ] . This reorganization provides superior results because specialized agents are employed for certain tasks, and removed when they are no longer needed. By matching agents roles and skills to the task at hand, agent teams can achieve greater accuracy and decrease time to meet the goal. Key features of effective multi-agent architectures include clear leadership in agent teams, dynamic team construction, and effective information sharing between team members so that important information does not get lost in superfluous chatter.
4.3 Examples
Embodied LLM Agents Learn to Cooperate in Organized Teams. Research by Guo et al. demonstrates the impact of a lead agent on the overall effectiveness of the agent team [ guo2024embodied ] . This architecture contains a vertical component through the leader agent, as well as a horizontal component from the ability for agents to converse with other agents besides the leader. The results of their study demonstrate that agent teams with an organized leader complete their tasks nearly 10% faster than teams without a leader.
Furthermore, they discovered that in teams without a designated leader, agents spent most of their time giving orders to one another (~50% of communication), splitting their remaining time between sharing information, or requesting guidance. Conversely, in teams with a designated leader, 60% of the leader’s communication involved giving directions, prompting other members to focus more on exchanging and requesting information. Their results demonstrate that agent teams are most effective when the leader is a human.

Beyond team structure, the paper emphasizes the importance of employing a “criticize-reflect” step for generating plans, evaluating performance, providing feedback, and re-organizing the team [ guo2024embodied ] . Their results indicate that agents with a dynamic team structure with rotating leadership provide the best results, with both the lowest time to task completion and the lowest communication cost on average. Ultimately, leadership and dynamic team structures improve the overall team’s ability to reason, plan, and perform tasks effectively.
DyLAN. The Dynamic LLM-Agent Network (DyLAN) framework creates a dynamic agent structure that focuses on complex tasks like reasoning and code generation [ liu2023dynamic ] . DyLAN has a specific step for determining how much each agent has contributed in the last round of work and only moves top contributors the next round of execution. This method is horizontal in nature since agents can share information with each other and there is no defined leader. DyLAN shows improved performance on a variety of benchmarks which measure arithmetic and general reasoning capabilities. This highlights the impact of dynamic teams and demonstrates that by consistently re-evaluating and ranking agent contributions, we can create agent teams that are better suited to complete a given task.
AgentVerse. Multi-agent architectures like AgentVerse demonstrate how distinct phases for group planning can improve an AI agent’s reasoning and problem-solving capabilities [ chen_agentverse_2023 ] . AgentVerse contains four primary stages for task execution: recruitment, collaborative decision making, independent action execution, and evaluation. This can be repeated until the overall goal is achieved. By strictly defining each phase, AgentVerse helps guide the set of agents to reason, discuss, and execute more effectively.
As an example, the recruitment step allows agents to be removed or added based on the progress towards the goal. This helps ensure that the right agents are participating at any given stage of problem solving. The researchers found that horizontal teams are generally best suited for collaborative tasks like consulting, while vertical teams are better suited for tasks that require clearer isolation of responsibilities for tool calling.
MetaGPT. Many multi-agent architectures allow agents to converse with one another while collaborating on a common problem. This conversational capability can lead to chatter between the agents that is superfluous and does not further the team goal. MetaGPT addresses the issue of unproductive chatter amongst agents by requiring agents to generate structured outputs like documents and diagrams instead of sharing unstructured chat messages [ hong2023metagpt ] .
Additionally, MetaGPT implements a ”publish-subscribe” mechanism for information sharing. This allows all the agents to share information in one place, but only read information relevant to their individual goals and tasks. This streamlines the overall goal execution and reduces conversational noise between agents. When compared to single-agent architectures on the HumanEval and MBPP benchmarks, MetaGPT’s multi-agent architecture demonstrates significantly better results.
5 Discussion and Observations
5.1 overview.
In this section we discuss the key themes and impacts of the design choices exhibited in the previously outlined agent patterns. These patterns serve as key examples of the growing body of research and implementation of AI agent architectures. Both single and multi-agent architectures seek to enhance the capabilities of language models by giving them the ability to execute goals on behalf of or alongside a human user. Most observed agent implementations broadly follow the plan, act, and evaluate process to iteratively solve problems.
We find that both single and multi-agent architectures demonstrate compelling performance on complex goal execution. We also find that across architectures clear feedback, task decomposition, iterative refinement, and role definition yield improved agent performance.
5.2 Key Findings
Typical Conditions for Selecting a Single vs Multi-Agent Architecture. Based on the aforementioned agent patterns, we find that single-agent patterns are generally best suited for tasks with a narrowly defined list of tools and where processes are well-defined. Single agents are also typically easier to implement since only one agent and set of tools needs to be defined. Additionally, single agent architectures do not face limitations like poor feedback from other agents or distracting and unrelated chatter from other team members. However, they may get stuck in an execution loop and fail to make progress towards their goal if their reasoning and refinement capabilities are not robust.
Multi-agent architectures are generally well-suited for tasks where feedback from multiple personas is beneficial in accomplishing the task. For example, document generation may benefit from a multi-agent architecture where one agent provides clear feedback to another on a written section of the document. Multi-agent systems are also useful when parallelization across distinct tasks or workflows is required. Crucially, Wang et. al finds that multi-agent patterns perform better than single agents in scenarios when no examples are provided [ wang_rethinking_2024 ] . By nature, multi-agent systems are more complex and often benefit from robust conversation management and clear leadership.
While single and multi-agent patterns have diverging capabilities in terms of scope, research finds that “multi-agent discussion does not necessarily enhance reasoning when the prompt provided to an agent is sufficiently robust” [ wang_rethinking_2024 ] . This suggests that those implementing agent architectures should decide between single or multiple agents based on the broader context of their use case, and not based on the reasoning capabilities required.
Agents and Asynchronous Task Execution. While a single agent can initiate multiple asynchronous calls simultaneously, its operational model does not inherently support the division of responsibilities across different execution threads. This means that, although tasks are handled asynchronously, they are not truly parallel in the sense of being autonomously managed by separate decision-making entities. Instead, the single agent must sequentially plan and execute tasks, waiting for one batch of asynchronous operations to complete before it can evaluate and move on to the next step. Conversely, in multi-agent architectures, each agent can operate independently, allowing for a more dynamic division of labor. This structure not only facilitates simultaneous task execution across different domains or objectives but also allows individual agents to proceed with their next steps without being hindered by the state of tasks handled by others, embodying a more flexible and parallel approach to task management.
Impact of Feedback and Human Oversight on Agent Systems. When solving a complex problem, it is extremely unlikely that one provides a correct, robust solution on their first try. Instead, one might pose a potential solution before criticizing it and refining it. One could also consult with someone else and receive feedback from another perspective. The same idea of iterative feedback and refinement is essential for helping agents solve complex problems.
This is partially because language models tend to commit to an answer earlier in their response, which can cause a ‘snowball effect’ of increasing diversion from their goal state [ zhang_how_2023 ] . By implementing feedback, agents are much more likely to correct their course and reach their goal.
Additionally, the inclusion of human oversight improves the immediate outcome by aligning the agent’s responses more closely with human expectations, mitigating the potential for agents to delve down an inefficient or invalid approach to solving a task. As of today, including human validation and feedback in the agent architecture yields more reliable and trustworthy results [ feng2024large , guo2024embodied ] .
Language models also exhibit sycophantic behavior, where they “tend to mirror the user’s stance, even if it means forgoing the presentation of an impartial or balanced viewpoint” [ park_ai_2023 ] . Specifically, the AgentVerse paper describes how agents are susceptible to feedback from other agents, even if the feedback is not sound. This can lead the agent team to generate a faulty plan which diverts them from their objective [ chen_agentverse_2023 ] . Robust prompting can help mitigate this, but those developing agent applications should be aware of the risks when implementing user or agent feedback systems.
Challenges with Group Conversations and Information Sharing. One challenge with multi-agent architectures lies in their ability to intelligently share messages between agents. Multi-agent patterns have a greater tendency to get caught up in niceties and ask one another things like “how are you”, while single agent patterns tend to stay focused on the task at hand since there is no team dynamic to manage. The extraneous dialogue in multi-agent systems can impair both the agent’s ability to reason effectively and execute the right tools, ultimately distracting the agents from the task and decreasing team efficiency. This is especially true in a horizontal architecture, where agents typically share a group chat and are privy to every agent’s message in a conversation. Message subscribing or filtering improves multi-agent performance by ensuring agents only receive information relevant to their tasks.
In vertical architectures, tasks tend to be clearly divided by agent skill which helps reduce distractions in the team. However, challenges arise when the leading agent fails to send critical information to their supporting agents and does not realize the other agents aren’t privy to necessary information. This failure can lead to confusion in the team or hallucination in the results. One approach to address this issue is to explicitly include information about access rights in the system prompt so that the agents have contextually appropriate interactions.
Impact of Role Definition and Dynamic Teams. Clear role definition is critical for both single and multi-agent architectures. In single-agent architectures role definition ensures that the agent stays focused on the provided task, executes the proper tools, and minimizes hallucination of other capabilities. Similarly, role definition in multi-agent architectures ensures each agent knows what it’s responsible for in the overall team and does not take on tasks outside of their described capabilities or scope. Beyond individual role definition, establishing a clear group leader also improves the overall performance of multi-agent teams by streamlining task assignment. Furthermore, defining a clear system prompt for each agent can minimize excess chatter by prompting the agents not to engage in unproductive communication.
Dynamic teams where agents are brought in and out of the system based on need have also been shown to be effective. This ensures that all agents participating in the planning or execution of tasks are fit for that round of work.
5.3 Summary
Both single and multi-agent patterns exhibit strong performance on a variety of complex tasks involving reasoning and tool execution. Single agent patterns perform well when given a defined persona and set of tools, opportunities for human feedback, and the ability to work iteratively towards their goal. When constructing an agent team that needs to collaborate on complex goals, it is beneficial to deploy agents with at least one of these key elements: clear leader(s), a defined planning phase and opportunities to refine the plan as new information is learned, intelligent message filtering, and dynamic teams whose agents possess specific skills relevant to the current sub-task. If an agent architecture employs at least one of these approaches it is likely to result in increased performance compared to a single agent architecture or a multi-agent architecture without these tactics.
6 Limitations of Current Research and Considerations for Future Research
6.1 overview.
In this section we examine some of the limitations of agent research today and identify potential areas for improving AI agent systems. While agent architectures have significantly enhanced the capability of language models in many ways, there are some major challenges around evaluations, overall reliability, and issues inherited from the language models powering each agent.
6.2 Challenges with Agent Evaluation
While LLMs are evaluated on a standard set of benchmarks designed to gauge their general understanding and reasoning capabilities, the benchmarks for agent evaluation vary greatly.
Many research teams introduce their own unique agent benchmarks alongside their agent implementation which makes comparing multiple agent implementations on the same benchmark challenging. Additionally, many of these new agent-specific benchmarks include a hand-crafted, highly complex, evaluation set where the results are manually scored [ chen_agentverse_2023 ] . This can provide a high-quality assessment of a method’s capabilities, but it also lacks the robustness of a larger dataset and risks introducing bias into the evaluation, since the ones developing the method are also the ones writing and scoring the results. Agents can also have problems generating a consistent answer over multiple iterations, due to variability in the models, environment, or problem state. This added randomness poses a much larger problem to smaller, complex evaluation sets.
6.3 Impact of Data Contamination and Static Benchmarks
Some researchers evaluate their agent implementations on the typical LLM benchmarks. Emerging research indicates that there is significant data contamination in the model’s training data, supported by the observation that a model’s performance significantly worsens when benchmark questions are modified [ golchin_time_2024 , zhu_dyval_2024 , zhu_dyval2_2024 ] . This raises doubts on the authenticity of benchmark scores for both the language models and language model powered agents.
Furthermore, researchers have found that “As LLMs progress at a rapid pace, existing datasets usually fail to match the models’ ever-evolving capabilities, because the complexity level of existing benchmarks is usually static and fixed” [ zhu_dyval2_2024 ] . To address this, work has been done to create dynamic benchmarks that are resistant to simple memorization [ zhu_dyval_2024 , zhu_dyval2_2024 ] . Researchers have also explored the idea of generating an entirely synthetic benchmark based on a user’s specific environment or use case [ lei_s3eval_2023 , wang_benchmark_2024 ] . While these techniques can help with contamination, decreasing the level of human involvement can pose additional risks regarding correctness and the ability to solve problems.
6.4 Benchmark Scope and Transferability
Many language model benchmarks are designed to be solved in a single iteration, with no tool calls, such as MMLU or GSM8K [ cobbe_training_2021 , hendrycks_measuring_2021 ] . While these are important for measuring the abilities of base language models, they are not good proxies for agent capabilities because they do not account for agent systems’ ability to reason over multiple steps or access outside information. StrategyQA improves upon this by assessing models’ reasoning abilities over multiple steps, but the answers are limited to Yes/No responses [ geva_did_2021 ] . As the industry continues to pivot towards agent focused use-cases additional measures will be needed to better assess the performance and generalizability of agents to tasks involving tools that extend beyond their training data.
Some agent specific benchmarks like AgentBench evaluate language model-based agents in a variety of different environments such as web browsing, command-line interfaces, and video games [ liu_agentbench_2023 ] . This provides a better indication for how well agents can generalize to new environments, by reasoning, planning, and calling tools to achieve a given task. Benchmarks like AgentBench and SmartPlay introduce objective evaluation metrics designed to evaluate the implementation’s success rate, output similarity to human responses, and overall efficiency [ liu_agentbench_2023 , wu_smartplay_2024 ] . While these objective metrics are important to understanding the overall reliability and accuracy of the implementation, it is also important to consider more nuanced or subjective measures of performance. Metrics such as efficiency of tool use, reliability, and robustness of planning are nearly as important as success rate but are much more difficult to measure. Many of these metrics require evaluation by a human expert, which can be costly and time consuming compared to LLM-as-judge evaluations.
6.5 Real-world Applicability
Many of the existing benchmarks focus on the ability of Agent systems to reason over logic puzzles or video games [ liu_agentbench_2023 ] . While evaluating performance on these types of tasks can help get a sense of the reasoning capabilities of agent systems, it is unclear whether performance on these benchmarks translates to real-world performance. Specifically, real-world data can be noisy and cover a much wider breadth of topics that many common benchmarks lack.
One popular benchmark that uses real-world data is WildBench, which is sourced from the WildChat dataset of 570,000 real conversations with ChatGPT [ zhao2024inthewildchat ] . Because of this, it covers a huge breadth of tasks and prompts. While WildBench covers a wide range of topics, most other real-world benchmarks focus on a specific task. For example, SWE-bench is a benchmark that uses a set of real-world issues raised on GitHub for software engineering tasks in Python [ jimenez_swe-bench_2023 ] . This can be very helpful when evaluating agents designed to write Python code and provides a sense for how well agents can reason about code related problems; however, it is less informative when trying to understand agent capabilities involving other programming languages.
6.6 Bias and Fairness in Agent Systems
Language Models have been known to exhibit bias both in terms of evaluation as well as in social or fairness terms [ gallegos_bias_2024 ] . Moreover, agents have specifically been shown to be “less robust, prone to more harmful behaviors, and capable of generating stealthier content than LLMs, highlighting significant safety challenges” [ tian_evil_2024 ] . Other research has found “a tendency for LLM agents to conform to the model’s inherent social biases despite being directed to debate from certain political perspectives” [ taubenfeld_systematic_2024 ] . This tendency can lead to faulty reasoning in any agent-based implementation.
As the complexity of tasks and agent involvement increases, more research is needed to identify and address biases within these systems. This poses a very large challenge to researchers, since scalable and novel benchmarks often involve some level of LLM involvement during creation. However, a truly robust benchmark for evaluating bias in LLM-based agents must include human evaluation.
7 Conclusion and Future Directions
The AI agent implementations explored in this survey demonstrate the rapid enhancement in language model powered reasoning, planning, and tool calling. Single and multi-agent patterns both show the ability to tackle complex multi-step problems that require advanced problem-solving skills. The key insights discussed in this paper suggest that the best agent architecture varies based on use case. Regardless of the architecture selected, the best performing agent systems tend to incorporate at least one of the following approaches: well defined system prompts, clear leadership and task division, dedicated reasoning / planning- execution - evaluation phases, dynamic team structures, human or agentic feedback, and intelligent message filtering. Architectures that leverage these techniques are more effective across a variety of benchmarks and problem types.
While the current state of AI-driven agents is promising, there are notable limitations and areas for future improvement. Challenges around comprehensive agent benchmarks, real world applicability, and the mitigation of harmful language model biases will need to be addressed in the near-term to enable reliable agents. By examining the progression from static language models to more dynamic, autonomous agents, this survey aims to provide a holistic understanding of the current AI agent landscape and offer insight for those building with existing agent architectures or developing custom agent architectures.
Problem Solving Agents in Artificial Intelligence
In this post, we will talk about Problem Solving agents in Artificial Intelligence, which are sort of goal-based agents. Because the straight mapping from states to actions of a basic reflex agent is too vast to retain for a complex environment, we utilize goal-based agents that may consider future actions and the desirability of outcomes.
You Will Learn
Problem Solving Agents
Problem Solving Agents decide what to do by finding a sequence of actions that leads to a desirable state or solution.
An agent may need to plan when the best course of action is not immediately visible. They may need to think through a series of moves that will lead them to their goal state. Such an agent is known as a problem solving agent , and the computation it does is known as a search .
The problem solving agent follows this four phase problem solving process:
- Goal Formulation: This is the first and most basic phase in problem solving. It arranges specific steps to establish a target/goal that demands some activity to reach it. AI agents are now used to formulate goals.
- Problem Formulation: It is one of the fundamental steps in problem-solving that determines what action should be taken to reach the goal.
- Search: After the Goal and Problem Formulation, the agent simulates sequences of actions and has to look for a sequence of actions that reaches the goal. This process is called search, and the sequence is called a solution . The agent might have to simulate multiple sequences that do not reach the goal, but eventually, it will find a solution, or it will find that no solution is possible. A search algorithm takes a problem as input and outputs a sequence of actions.
- Execution: After the search phase, the agent can now execute the actions that are recommended by the search algorithm, one at a time. This final stage is known as the execution phase.
Problems and Solution
Before we move into the problem formulation phase, we must first define a problem in terms of problem solving agents.
A formal definition of a problem consists of five components:
Initial State
Transition model.
It is the agent’s starting state or initial step towards its goal. For example, if a taxi agent needs to travel to a location(B), but the taxi is already at location(A), the problem’s initial state would be the location (A).
It is a description of the possible actions that the agent can take. Given a state s, Actions ( s ) returns the actions that can be executed in s. Each of these actions is said to be appropriate in s.
It describes what each action does. It is specified by a function Result ( s, a ) that returns the state that results from doing action an in state s.
The initial state, actions, and transition model together define the state space of a problem, a set of all states reachable from the initial state by any sequence of actions. The state space forms a graph in which the nodes are states, and the links between the nodes are actions.
It determines if the given state is a goal state. Sometimes there is an explicit list of potential goal states, and the test merely verifies whether the provided state is one of them. The goal is sometimes expressed via an abstract attribute rather than an explicitly enumerated set of conditions.
It assigns a numerical cost to each path that leads to the goal. The problem solving agents choose a cost function that matches its performance measure. Remember that the optimal solution has the lowest path cost of all the solutions .
Example Problems
The problem solving approach has been used in a wide range of work contexts. There are two kinds of problem approaches
- Standardized/ Toy Problem: Its purpose is to demonstrate or practice various problem solving techniques. It can be described concisely and precisely, making it appropriate as a benchmark for academics to compare the performance of algorithms.
- Real-world Problems: It is real-world problems that need solutions. It does not rely on descriptions, unlike a toy problem, yet we can have a basic description of the issue.
Some Standardized/Toy Problems
Vacuum world problem.
Let us take a vacuum cleaner agent and it can move left or right and its jump is to suck up the dirt from the floor.

The vacuum world’s problem can be stated as follows:
States: A world state specifies which objects are housed in which cells. The objects in the vacuum world are the agent and any dirt. The agent can be in either of the two cells in the simple two-cell version, and each call can include dirt or not, therefore there are 2×2×2 = 8 states. A vacuum environment with n cells has n×2 n states in general.
Initial State: Any state can be specified as the starting point.
Actions: We defined three actions in the two-cell world: sucking, moving left, and moving right. More movement activities are required in a two-dimensional multi-cell world.
Transition Model: Suck cleans the agent’s cell of any filth; Forward moves the agent one cell forward in the direction it is facing unless it meets a wall, in which case the action has no effect. Backward moves the agent in the opposite direction, whilst TurnRight and TurnLeft rotate it by 90°.
Goal States: The states in which every cell is clean.
Action Cost: Each action costs 1.
8 Puzzle Problem
In a sliding-tile puzzle , a number of tiles (sometimes called blocks or pieces) are arranged in a grid with one or more blank spaces so that some of the tiles can slide into the blank space. One variant is the Rush Hour puzzle, in which cars and trucks slide around a 6 x 6 grid in an attempt to free a car from the traffic jam. Perhaps the best-known variant is the 8- puzzle (see Figure below ), which consists of a 3 x 3 grid with eight numbered tiles and one blank space, and the 15-puzzle on a 4 x 4 grid. The object is to reach a specified goal state, such as the one shown on the right of the figure. The standard formulation of the 8 puzzles is as follows:
STATES : A state description specifies the location of each of the tiles.
INITIAL STATE : Any state can be designated as the initial state. (Note that a parity property partitions the state space—any given goal can be reached from exactly half of the possible initial states.)
ACTIONS : While in the physical world it is a tile that slides, the simplest way of describing action is to think of the blank space moving Left , Right , Up , or Down . If the blank is at an edge or corner then not all actions will be applicable.
TRANSITION MODEL : Maps a state and action to a resulting state; for example, if we apply Left to the start state in the Figure below, the resulting state has the 5 and the blank switched.

GOAL STATE : It identifies whether we have reached the correct goal state. Although any state could be the goal, we typically specify a state with the numbers in order, as in the Figure above.
ACTION COST : Each action costs 1.
You Might Like:
- Agents in Artificial Intelligence
Types of Environments in Artificial Intelligence
- Understanding PEAS in Artificial Intelligence
- River Crossing Puzzle | Farmer, Wolf, Goat and Cabbage
Share Article:
Digital image processing: all you need to know.
- Data Science
- Data Analysis
- Data Visualization
- Machine Learning
- Deep Learning
- Computer Vision
- Artificial Intelligence
- AI ML DS Interview Series
- AI ML DS Projects series
- Data Engineering
- Web Scrapping
Problem Solving in Artificial Intelligence
- Game Playing in Artificial Intelligence
- Types of Reasoning in Artificial Intelligence
- Artificial Intelligence - Terminology
- Artificial Intelligence(AI) Replacing Human Jobs
- Constraint Satisfaction Problems (CSP) in Artificial Intelligence
- What Are The Ethical Problems in Artificial Intelligence?
- Artificial Intelligence | An Introduction
- Artificial Intelligence - Boon or Bane
- What is Artificial Intelligence?
- Artificial Intelligence in Financial Market
- Artificial Intelligence Tutorial | AI Tutorial
- Top 15 Artificial Intelligence(AI) Tools List
- What is Artificial Narrow Intelligence (ANI)?
- Artificial Intelligence Permeation and Application
- Dangers of Artificial Intelligence
- What is the Role of Planning in Artificial Intelligence?
- Artificial Intelligence (AI) Researcher Jobs in China
- Artificial Intelligence vs Cognitive Computing
- 5 Mistakes to Avoid While Learning Artificial Intelligence
The reflex agent of AI directly maps states into action. Whenever these agents fail to operate in an environment where the state of mapping is too large and not easily performed by the agent, then the stated problem dissolves and sent to a problem-solving domain which breaks the large stored problem into the smaller storage area and resolves one by one. The final integrated action will be the desired outcomes.
On the basis of the problem and their working domain, different types of problem-solving agent defined and use at an atomic level without any internal state visible with a problem-solving algorithm. The problem-solving agent performs precisely by defining problems and several solutions. So we can say that problem solving is a part of artificial intelligence that encompasses a number of techniques such as a tree, B-tree, heuristic algorithms to solve a problem.
We can also say that a problem-solving agent is a result-driven agent and always focuses on satisfying the goals.
There are basically three types of problem in artificial intelligence:
1. Ignorable: In which solution steps can be ignored.
2. Recoverable: In which solution steps can be undone.
3. Irrecoverable: Solution steps cannot be undo.
Steps problem-solving in AI: The problem of AI is directly associated with the nature of humans and their activities. So we need a number of finite steps to solve a problem which makes human easy works.
These are the following steps which require to solve a problem :
- Problem definition: Detailed specification of inputs and acceptable system solutions.
- Problem analysis: Analyse the problem thoroughly.
- Knowledge Representation: collect detailed information about the problem and define all possible techniques.
- Problem-solving: Selection of best techniques.
Components to formulate the associated problem:
- Initial State: This state requires an initial state for the problem which starts the AI agent towards a specified goal. In this state new methods also initialize problem domain solving by a specific class.
- Action: This stage of problem formulation works with function with a specific class taken from the initial state and all possible actions done in this stage.
- Transition: This stage of problem formulation integrates the actual action done by the previous action stage and collects the final stage to forward it to their next stage.
- Goal test: This stage determines that the specified goal achieved by the integrated transition model or not, whenever the goal achieves stop the action and forward into the next stage to determines the cost to achieve the goal.
- Path costing: This component of problem-solving numerical assigned what will be the cost to achieve the goal. It requires all hardware software and human working cost.

Please Login to comment...
Similar reads, improve your coding skills with practice.
What kind of Experience do you want to share?
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Perspective
- Published: 25 January 2022
Intelligent problem-solving as integrated hierarchical reinforcement learning
- Manfred Eppe ORCID: orcid.org/0000-0002-5473-3221 1 nAff4 ,
- Christian Gumbsch ORCID: orcid.org/0000-0003-2741-6551 2 , 3 ,
- Matthias Kerzel 1 ,
- Phuong D. H. Nguyen 1 ,
- Martin V. Butz ORCID: orcid.org/0000-0002-8120-8537 2 &
- Stefan Wermter 1
Nature Machine Intelligence volume 4 , pages 11–20 ( 2022 ) Cite this article
5342 Accesses
32 Citations
8 Altmetric
Metrics details
- Cognitive control
- Computational models
- Computer science
- Learning algorithms
- Problem solving
According to cognitive psychology and related disciplines, the development of complex problem-solving behaviour in biological agents depends on hierarchical cognitive mechanisms. Hierarchical reinforcement learning is a promising computational approach that may eventually yield comparable problem-solving behaviour in artificial agents and robots. However, so far, the problem-solving abilities of many human and non-human animals are clearly superior to those of artificial systems. Here we propose steps to integrate biologically inspired hierarchical mechanisms to enable advanced problem-solving skills in artificial agents. We first review the literature in cognitive psychology to highlight the importance of compositional abstraction and predictive processing. Then we relate the gained insights with contemporary hierarchical reinforcement learning methods. Interestingly, our results suggest that all identified cognitive mechanisms have been implemented individually in isolated computational architectures, raising the question of why there exists no single unifying architecture that integrates them. As our final contribution, we address this question by providing an integrative perspective on the computational challenges to develop such a unifying architecture. We expect our results to guide the development of more sophisticated cognitively inspired hierarchical machine learning architectures.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
24,99 € / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
111,21 € per year
only 9,27 € per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout

Similar content being viewed by others

Phy-Q as a measure for physical reasoning intelligence

Hierarchical motor control in mammals and machines

Hierarchical generative modelling for autonomous robots
Gruber, R. et al. New Caledonian crows use mental representations to solve metatool problems. Curr. Biol. 29 , 686–692 (2019).
Article Google Scholar
Butz, M. V. & Kutter, E. F. How the Mind Comes into Being (Oxford Univ. Press, 2017).
Perkins, D. N. & Salomon, G. in International Encyclopedia of Education (eds. Husen T. & Postelwhite T. N.) 6452–6457 (Pergamon Press, 1992).
Botvinick, M. M., Niv, Y. & Barto, A. C. Hierarchically organized behavior and its neural foundations: a reinforcement learning perspective. Cognition 113 , 262–280 (2009).
Tomov, M. S., Yagati, S., Kumar, A., Yang, W. & Gershman, S. J. Discovery of hierarchical representations for efficient planning. PLoS Comput. Biol. 16 , e1007594 (2020).
Arulkumaran, K., Deisenroth, M. P., Brundage, M. & Bharath, A. A. Deep reinforcement learning: a brief survey. IEEE Signal Process. Mag. 34 , 26–38 (2017).
Li, Y. Deep reinforcement learning: an overview. Preprint at https://arxiv.org/abs/1701.07274 (2018).
Sutton, R. S. & Barto, A. G. Reinforcement Learning : An Introduction 2nd edn (MIT Press, 2018).
Neftci, E. O. & Averbeck, B. B. Reinforcement learning in artificial and biological systems. Nat. Mach. Intell. 1 , 133–143 (2019).
Eppe, M., Nguyen, P. D. H. & Wermter, S. From semantics to execution: integrating action planning with reinforcement learning for robotic causal problem-solving. Front. Robot. AI 6 , 123 (2019).
Oh, J., Singh, S., Lee, H. & Kohli, P. Zero-shot task generalization with multi-task deep reinforcement learning. In Proc. 34th International Conference on Machine Learning ( ICML ) (eds. Precup, D. & Teh, Y. W.) 2661–2670 (PMLR, 2017).
Sohn, S., Oh, J. & Lee, H. Hierarchical reinforcement learning for zero-shot generalization with subtask dependencies. In Proc. 32nd International Conference on Neural Information Processing Systems ( NeurIPS ) (eds Bengio S. et al.) Vol. 31, 7156–7166 (ACM, 2018).
Hegarty, M. Mechanical reasoning by mental simulation. Trends Cogn. Sci. 8 , 280–285 (2004).
Klauer, K. J. Teaching for analogical transfer as a means of improving problem-solving, thinking and learning. Instruct. Sci. 18 , 179–192 (1989).
Duncker, K. & Lees, L. S. On problem-solving. Psychol. Monographs 58, No.5 (whole No. 270), 85–101 https://doi.org/10.1037/h0093599 (1945).
Dayan, P. Goal-directed control and its antipodes. Neural Netw. 22 , 213–219 (2009).
Dolan, R. J. & Dayan, P. Goals and habits in the brain. Neuron 80 , 312–325 (2013).
O’Doherty, J. P., Cockburn, J. & Pauli, W. M. Learning, reward, and decision making. Annu. Rev. Psychol. 68 , 73–100 (2017).
Tolman, E. C. & Honzik, C. H. Introduction and removal of reward, and maze performance in rats. Univ. California Publ. Psychol. 4 , 257–275 (1930).
Google Scholar
Butz, M. V. & Hoffmann, J. Anticipations control behavior: animal behavior in an anticipatory learning classifier system. Adaptive Behav. 10 , 75–96 (2002).
Miller, G. A., Galanter, E. & Pribram, K. H. Plans and the Structure of Behavior (Holt, Rinehart & Winston, 1960).
Botvinick, M. & Weinstein, A. Model-based hierarchical reinforcement learning and human action control. Philos. Trans. R. Soc. B Biol. Sci. 369 , 20130480 (2014).
Wiener, J. M. & Mallot, H. A. ’Fine-to-coarse’ route planning and navigation in regionalized environments. Spatial Cogn. Comput. 3 , 331–358 (2003).
Stock, A. & Stock, C. A short history of ideo-motor action. Psychol. Res. 68 , 176–188 (2004).
Hommel, B., Müsseler, J., Aschersleben, G. & Prinz, W. The theory of event coding (TEC): a framework for perception and action planning. Behav. Brain Sci. 24 , 849–878 (2001).
Hoffmann, J. in Anticipatory Behavior in Adaptive Learning Systems : Foundations , Theories and Systems (eds Butz, M. V. et al.) 44–65 (Springer, 2003).
Kunde, W., Elsner, K. & Kiesel, A. No anticipation-no action: the role of anticipation in action and perception. Cogn. Process. 8 , 71–78 (2007).
Barsalou, L. W. Grounded cognition. Annu. Rev. Psychol. 59 , 617–645 (2008).
Butz, M. V. Toward a unified sub-symbolic computational theory of cognition. Front. Psychol. 7 , 925 (2016).
Pulvermüller, F. Brain embodiment of syntax and grammar: discrete combinatorial mechanisms spelt out in neuronal circuits. Brain Lang. 112 , 167–179 (2010).
Sutton, R. S., Precup, D. & Singh, S. Between MDPs and semi-MDPs: a framework for temporal abstraction in reinforcement learning. Artif. Intell. 112 , 181–211 (1999).
Article MathSciNet MATH Google Scholar
Flash, T. & Hochner, B. Motor primitives in vertebrates and invertebrates. Curr. Opin. Neurobiol. 15 , 660–666 (2005).
Schaal, S. in Adaptive Motion of Animals and Machines (eds. Kimura, H. et al.) 261–280 (Springer, 2006).
Feldman, J., Dodge, E. & Bryant, J. in The Oxford Handbook of Linguistic Analysis (eds Heine, B. & Narrog, H.) 111–138 (Oxford Univ. Press, 2009).
Fodor, J. A. Language, thought and compositionality. Mind Lang. 16 , 1–15 (2001).
Frankland, S. M. & Greene, J. D. Concepts and compositionality: in search of the brain’s language of thought. Annu. Rev. Psychol. 71 , 273–303 (2020).
Hummel, J. E. Getting symbols out of a neural architecture. Connection Sci. 23 , 109–118 (2011).
Haynes, J. D., Wisniewski, D., Gorgen, K., Momennejad, I. & Reverberi, C. FMRI decoding of intentions: compositionality, hierarchy and prospective memory. In Proc. 3rd International Winter Conference on Brain-Computer Interface ( BCI ), 1-3 (IEEE, 2015).
Gärdenfors, P. The Geometry of Meaning : Semantics Based on Conceptual Spaces (MIT Press, 2014).
Book MATH Google Scholar
Lakoff, G. & Johnson, M. Philosophy in the Flesh (Basic Books, 1999).
Eppe, M. et al. A computational framework for concept blending. Artif. Intell. 256 , 105–129 (2018).
Turner, M. The Origin of Ideas (Oxford Univ. Press, 2014).
Deci, E. L. & Ryan, R. M. Self-determination theory and the facilitation of intrinsic motivation. Am. Psychol. 55 , 68–78 (2000).
Friston, K. et al. Active inference and epistemic value. Cogn. Neurosci. 6 , 187–214 (2015).
Berlyne, D. E. Curiosity and exploration. Science 153 , 25–33 (1966).
Loewenstein, G. The psychology of curiosity: a review and reinterpretation. Psychol. Bull. 116 , 75–98 (1994).
Oudeyer, P.-Y., Kaplan, F. & Hafner, V. V. Intrinsic motivation systems for autonomous mental development. In IEEE Transactions on Evolutionary Computation (eds. Coello, C. A. C. et al.) Vol. 11, 265–286 (IEEE, 2007).
Pisula, W. Play and exploration in animals—a comparative analysis. Polish Psychol. Bull. 39 , 104–107 (2008).
Jeannerod, M. Mental imagery in the motor context. Neuropsychologia 33 , 1419–1432 (1995).
Kahnemann, D. & Tversky, A. in Judgement under Uncertainty : Heuristics and Biases (eds Kahneman, D. et al.) Ch. 14, 201–208 (Cambridge Univ. Press, 1982).
Wells, G. L. & Gavanski, I. Mental simulation of causality. J. Personal. Social Psychol. 56 , 161–169 (1989).
Taylor, S. E., Pham, L. B., Rivkin, I. D. & Armor, D. A. Harnessing the imagination: mental simulation, self-regulation and coping. Am. Psychol. 53 , 429–439 (1998).
Kaplan, F. & Oudeyer, P.-Y. in Embodied Artificial Intelligence , Lecture Notes in Computer Science Vol. 3139 (eds Iida, F. et al.) 259–270 (Springer, 2004).
Schmidhuber, J. Formal theory of creativity, fun, and intrinsic motivation. IEEE Trans. Auton. Mental Dev. 2 , 230–247 (2010).
Friston, K., Mattout, J. & Kilner, J. Action understanding and active inference. Biol. Cybern. 104 , 137–160 (2011).
Oudeyer, P.-Y. Computational theories of curiosity-driven learning. In The New Science of Curiosity (ed. Goren Gordon), 43-72 (Nova Science Publishers, 2018); https://arxiv.org/abs/1802.10546
Colombo, M. & Wright, C. First principles in the life sciences: the free-energy principle, organicism and mechanism. Synthese 198 , 3463–3488 (2021).
Article MathSciNet Google Scholar
Huang, Y. & Rao, R. P. Predictive coding. WIREs Cogn. Sci. 2 , 580–593 (2011).
Friston, K. The free-energy principle: a unified brain theory? Nat. Rev. Neurosci. 11 , 127–138 (2010).
Knill, D. C. & Pouget, A. The Bayesian brain: the role of uncertainty in neural coding and computation. Trends Neurosci. 27 , 712–719 (2004).
Clark, A. Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behav. Brain Sci. 36 , 181–204 (2013).
Clark, A. Surfing Uncertainty : Prediction , Action and the Embodied Mind (Oxford Univ. Press, 2016).
Zacks, J. M., Speer, N. K., Swallow, K. M., Braver, T. S. & Reyonolds, J. R. Event perception: a mind/brain perspective. Psychol. Bull. 133 , 273–293 (2007).
Eysenbach, B., Ibarz, J., Gupta, A. & Levine, S. Diversity is all you need: learning skills without a reward function. In International Conference on Learning Representations (ICLR, 2019).
Frans, K., Ho, J., Chen, X., Abbeel, P. & Schulman, J. Meta learning shared hierarchies. In Proc. International Conference on Learning Representations https://openreview.net/pdf?id=SyX0IeWAW (ICLR, 2018).
Heess, N. et al. Learning and transfer of modulated locomotor controllers. Preprint at https://arxiv.org/abs/1610.05182 (2016).
Jiang, Y., Gu, S., Murphy, K. & Finn, C. Language as an abstraction for hierarchical deep reinforcement learning. In Neural Information Processing Systems ( NeurIPS ) (eds. Wallach, H. et al.) 9414–9426 (ACM, 2019).
Li, A. C., Florensa, C., Clavera, I. & Abbeel, P. Sub-policy adaptation for hierarchical reinforcement learning. In Proc. International Conference on Learning Representations https://openreview.net/forum?id=ByeWogStDS (ICLR, 2020).
Qureshi, A. H. et al. Composing task-agnostic policies with deep reinforcement learning. In Proc. International Conference on Learning Representations https://openreview.net/forum?id=H1ezFREtwH (ICLR, 2020).
Sharma, A., Gu, S., Levine, S., Kumar, V. & Hausman, K. Dynamics-aware unsupervised discovery of skills. In Proc. International Conference on Learning Representations https://openreview.net/forum?id=HJgLZR4KvH (ICLR, 2020).
Tessler, C., Givony, S., Zahavy, T., Mankowitz, D. J. & Mannor, S. A deep hierarchical approach to lifelong learning in minecraft. In Proc. 31st AAAI Conference on Artificial Intelligence 1553–1561 (AAAI, 2017).
Vezhnevets, A. et al. Strategic attentive writer for learning macro-actions. In Neural Information Processing Systems ( NIPS ) (eds. Lee, D. et al.) 3494–3502 (NIPS, 2016).
Devin, C., Gupta, A., Darrell, T., Abbeel, P. & Levine, S. Learning modular neural network policies for multi-task and multi-robot transfer. In Proc. International Conference on Robotics and Automation ( ICRA ) (eds. Okamura, A. et al.) 2169–2176 (IEEE, 2017).
Hejna, D. J., Abbeel, P. & Pinto, L. Hierarchically decoupled morphological transfer. In Proc. International Conference on Machine Learning ( ICML ) (eds. Daumé III, H. & Singh, A.) 11409–11420 (PMLR, 2020).
Hamrick, J. B. et al. On the role of planning in model-based deep reinforcement learning. In Proc. International Conference on Learning Representations https://openreview.net/pdf?id=IrM64DGB21 (ICLR, 2021).
Sutton, R. S. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In Proc. 7th International Conference on Machine Learning ( ICML ) (eds. Porter, B. W. & Mooney, R. J.) 216–224 (Morgan Kaufmann, 1990).
Nau, D. et al. SHOP2: an HTN planning system. J. Artif. Intell. Res. 20 , 379–404 (2003).
Article MATH Google Scholar
Lyu, D., Yang, F., Liu, B. & Gustafson, S. SDRL: interpretable and data-efficient deep reinforcement learning leveraging symbolic planning. In Proc. AAAI Conference on Artificial Intelligence Vol. 33, 2970–2977 (AAAI, 2019).
Ma, A., Ouimet, M. & Cortés, J. Hierarchical reinforcement learning via dynamic subspace search for multi-agent planning. Auton. Robot. 44 , 485–503 (2020).
Bacon, P.-L., Harb, J. & Precup, D. The option-critic architecture. In Proc. 31st AAAI Conference on Artificial Intelligence 1726–1734 (AAAI, 2017).
Dietterich, T. G. State abstraction in MAXQ hierarchical reinforcement learning. In Advances in Neural Information Processing Systems ( NIPS ) (eds. Solla, S. et al.) Vol. 12, 994–1000 (NIPS, 1999).
Kulkarni, T. D., Narasimhan, K. R., Saeedi, A. & Tenenbaum, J. B. Hierarchical deep reinforcement learning: integrating temporal abstraction and intrinsic motivation. In Neural Information Processing Systems ( NIPS ) (eds. Lee, D. et al.) 3675–3683 (NIPS, 2016).
Shankar, T., Pinto, L., Tulsiani, S. & Gupta, A. Discovering motor programs by recomposing demonstrations. In Proc. International Conference on Learning Representations https://openreview.net/attachment?id=rkgHY0NYwr&name=original_pdf (ICLR, 2020).
Vezhnevets, A. S., Wu, Y. T., Eckstein, M., Leblond, R. & Leibo, J. Z. Options as responses: grounding behavioural hierarchies in multi-agent reinforcement learning. In Proc. International Conference on Machine Learning ( ICML ) (eds. Daumé III, H. & Singh, A.) 9733–9742 (PMLR, 2020).
Ghazanfari, B., Afghah, F. & Taylor, M. E. Sequential association rule mining for autonomously extracting hierarchical task structures in reinforcement learning. IEEE Access 8 , 11782–11799 (2020).
Levy, A., Konidaris, G., Platt, R. & Saenko, K. Learning multi-level hierarchies with hindsight. In Proc. International Conference on Learning Representations https://openreview.net/pdf?id=ryzECoAcY7 (ICLR, 2019).
Nachum, O., Gu, S., Lee, H. & Levine, S. Data-efficient hierarchical reinforcement learning. In Proc. 32nd International Conference on Neural Information Processing Systems (NIPS) (eds. Bengio, S. et al.) 3307–3317 (NIPS, 2018).
Rafati, J. & Noelle, D. C. Learning representations in model-free hierarchical reinforcement learning. In Proc. 33rd AAAI Conference on Artificial Intelligence 10009–10010 (AAAI, 2019).
Röder, F., Eppe, M., Nguyen, P. D. H. & Wermter, S. Curious hierarchical actor-critic reinforcement learning. In Proc. International Conference on Artificial Neural Networks ( ICANN ) (eds. Farkaš, I. et al.) 408–419 (Springer, 2020).
Zhang, T., Guo, S., Tan, T., Hu, X. & Chen, F. Generating adjacency-constrained subgoals in hierarchical reinforcement learning. In Neural Information Processing Systems ( NIPS ) (eds. Larochelle, H. et al.) 21579-21590 (NIPS, 2020).
Lample, G. & Chaplot, D. S. Playing FPS games with deep reinforcement learning. In Proc. 31st AAAI Conference on Artificial Intelligence 2140–2146 (AAAI, 2017).
Vezhnevets, A. S. et al. FeUdal networks for hierarchical reinforcement learning. In Proc. 34th International Conference on Machine Learning ( ICML ) (eds. Precup, D. & Teh, Y. W.) Vol. 70, 3540–3549 (PMLR, 2017).
Wulfmeier, M. et al. Compositional Transfer in Hierarchical Reinforcement Learning. In Robotics: Science and System XVI (RSS) (eds. Toussaint M. et al.) (Robotics: Science and Systems Foundation, 2020); https://arxiv.org/abs/1906.11228
Yang, Z., Merrick, K., Jin, L. & Abbass, H. A. Hierarchical deep reinforcement learning for continuous action control. IEEE Trans. Neural Netw. Learn. Syst. 29 , 5174–5184 (2018).
Toussaint, M., Allen, K. R., Smith, K. A. & Tenenbaum, J. B. Differentiable physics and stable modes for tool-use and manipulation planning. In Proc. Robotics : Science and Systems XIV ( RSS ) (eds. Kress-Gazit, H. et al.) https://ipvs.informatik.uni-stuttgart.de/mlr/papers/18-toussaint-RSS.pdf (Robotics: Science and Systems Foundation, 2018).
Akrour, R., Veiga, F., Peters, J. & Neumann, G. Regularizing reinforcement learning with state abstraction. In Proc. IEEE / RSJ International Conference on Intelligent Robots and Systems ( IROS ) 534–539 (IEEE, 2018).
Schaul, T. & Ring, M. Better generalization with forecasts. In Proc. 23rd International Joint Conference on Artificial Intelligence ( IJCAI ) (ed. Rossi, F.) 1656–1662 (AAAI, 2013).
Colas, C., Akakzia, A., Oudeyer, P.-Y., Chetouani, M. & Sigaud, O. Language-conditioned goal generation: a new approach to language grounding for RL. Preprint at https://arxiv.org/abs/2006.07043 (2020).
Blaes, S., Pogancic, M. V., Zhu, J. J. & Martius, G. Control what you can: intrinsically motivated task-planning agent. Neural Inf. Process. Syst. 32 , 12541–12552 (2019).
Haarnoja, T., Hartikainen, K., Abbeel, P. & Levine, S. Latent space policies for hierarchical reinforcement learning. In Proc. International Conference on Machine Learning ( ICML ) (eds. Dy, J. & Krause, A.) Vol. 4, 2965–2975 (PMLR, 2018).
Rasmussen, D., Voelker, A. & Eliasmith, C. A neural model of hierarchical reinforcement learning. PLoS ONE 12 , e0180234 (2017).
Riedmiller, M. et al. Learning by playing—solving sparse reward tasks from scratch. In Proc. International Conference on Machine Learning ( ICML ) (eds. Dy, J. & Krause, A.) Vol. 10, 6910–6919 (PMLR, 2018).
Yang, F., Lyu, D., Liu, B. & Gustafson, S. PEORL: integrating symbolic planning and hierarchical reinforcement learning for robust decision-making. In Proc. 27th International Joint Conference on Artificial Intelligence ( IJCAI ) (ed. Lang, J.) 4860–4866 (IJCAI, 2018).
Machado, M. C., Bellemare, M. G. & Bowling, M. A Laplacian framework for option discovery in reinforcement learning. In Proc. International Conference on Machine Learning (ICML) (eds. Precup, D. & Teh, Y. W.) Vol. 5, 3567–3582 (PMLR, 2017).
Pathak, D., Agrawal, P., Efros, A. A. & Darrell, T. Curiosity-driven exploration by self-supervised prediction. In Proc. 34th International Conference on Machine Learning ( ICML ) (eds. Precup, D. & Teh, Y. W.) 2778–2787 (PMLR, 2017).
Schillaci, G. et al. Intrinsic motivation and episodic memories for robot exploration of high-dimensional sensory spaces. Adaptive Behav. 29 549–566 (2020).
Colas, C., Fournier, P., Sigaud, O., Chetouani, M. & Oudeyer, P.-Y. CURIOUS: intrinsically motivated modular multi-goal reinforcement learning. In Proc. International Conference on Machine Learning ( ICML ) (eds. Chaudhuri, K. & Salakhutdinov, R.) 1331–1340 (PMLR, 2019).
Hafez, M. B., Weber, C., Kerzel, M. & Wermter, S. Improving robot dual-system motor learning with intrinsically motivated meta-control and latent-space experience imagination. Robot. Auton. Syst. 133 , 103630 (2020).
Yamamoto, K., Onishi, T. & Tsuruoka, Y. Hierarchical reinforcement learning with abductive planning. In Proc. ICML / IJCAI / AAMAS 2018 Workshop on Planning and Learning ( PAL-18 ) (2018).
Wu, B., Gupta, J. K. & Kochenderfer, M. J. Model primitive hierarchical lifelong reinforcement learning . In Proc. International Joint Conference on Autonomous Agents and Multiagent Systems ( AAMAS ) (eds. Agmon, N. et al.) Vol. 1, 34–42 (IFAAMAS, 2019).
Li, Z., Narayan, A. & Leong, T. Y. An efficient approach to model-based hierarchical reinforcement learning. In Proc. 31st AAAI Conference on Artificial Intelligence 3583–3589 (AAAI, 2017).
Hafner, D., Lillicrap, T. & Norouzi, M. Dream to control: learning behaviors by latent imagination. In Proc. International Conference on Learning Representations https://openreview.net/pdf?id=S1lOTC4tDS (ICLR, 2020).
Deisenroth, M. P., Rasmussen, C. E. & Fox, D. Learning to control a low-cost manipulator using data-efficient reinforcement learning. In Robotics : Science and Systems VII ( RSS ) (eds. Durrant-Whyte, H. et al.) 57–64 (Robotics: Science and Systems Foundation, 2011).
Ha, D. & Schmidhuber, J. Recurrent world models facilitate policy evolution. In Proc. 32nd International Conference on Neural Information Processing Systems (NeurIPS) (eds. Bengio, S. et al.) 2455–2467 (NIPS, 2018).
Battaglia, P. W. et al. Relational inductive biases, deep learning and graph networks. Preprint at https://arxiv.org/abs/1806.01261 (2018).
Andrychowicz, M. et al. Hindsight experience replay. In Proc. Neural Information Processing Systems ( NIPS ) (eds. Guyon I. et al.) 5048–5058 (NIPS, 2017); https://papers.nips.cc/paper/7090-hindsight-experience-replay.pdf
Schwartenbeck, P. et al. Computational mechanisms of curiosity and goal-directed exploration. eLife 8 , e41703 (2019).
Haarnoja, T., Zhou, A., Abbeel, P. & Levine, S. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proc. International Conference on Machine Learning ( ICML ) (eds. Dy, J. & Krause, A.) 1861–1870 (PMLR, 2018).
Yu, A. J. & Dayan, P. Uncertainty, neuromodulation and attention. Neuron 46 , 681–692 (2005).
Baldwin, D. A. & Kosie, J. E. How does the mind render streaming experience as events? Top. Cogn. Sci. 13 , 79–105 (2021).
Download references
Acknowledgements
We acknowledge funding from the DFG (projects IDEAS, LeCAREbot, TRR169, SPP 2134, RTG 1808 and EXC 2064/1), the Humboldt Foundation and Max Planck Research School IMPRS-IS.
Author information
Manfred Eppe
Present address: Hamburg University of Technology, Hamburg, Germany
Authors and Affiliations
Universität Hamburg, Hamburg, Germany
Manfred Eppe, Matthias Kerzel, Phuong D. H. Nguyen & Stefan Wermter
University of Tübingen, Tübingen, Germany
Christian Gumbsch & Martin V. Butz
Max Planck Institute for Intelligent Systems, Tübingen, Germany
Christian Gumbsch
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Manfred Eppe .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information.
Supplementary Boxes 1–6 and Table 1.
Rights and permissions
Reprints and permissions
About this article
Cite this article.
Eppe, M., Gumbsch, C., Kerzel, M. et al. Intelligent problem-solving as integrated hierarchical reinforcement learning. Nat Mach Intell 4 , 11–20 (2022). https://doi.org/10.1038/s42256-021-00433-9
Download citation
Received : 18 December 2020
Accepted : 07 December 2021
Published : 25 January 2022
Issue Date : January 2022
DOI : https://doi.org/10.1038/s42256-021-00433-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Efficient stacking and grasping in unstructured environments.
- Jinbiao Zhu
Journal of Intelligent & Robotic Systems (2024)
Four attributes of intelligence, a thousand questions
- Matthieu Bardal
- Eric Chalmers
Biological Cybernetics (2023)
An Alternative to Cognitivism: Computational Phenomenology for Deep Learning
- Pierre Beckmann
- Guillaume Köstner
- Inês Hipólito
Minds and Machines (2023)
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: AI and Robotics newsletter — what matters in AI and robotics research, free to your inbox weekly.

Welcome back.

Continue with email
Mumbai University > Computer Engineering > Sem 7 > Artificial Intelligence
Marks: 5 Marks
Year: Dec 2015, May 2016
- LSE Authors
- Subscribe to our newsletter
Ravi Sawhney
May 24th, 2024, how to enhance generative ai’s problem-solving capabilities and boost workplace productivity.
0 comments | 8 shares
Estimated reading time: 5 minutes
In 2024, enterprise software companies are betting on generative AI, in a quest to enhance productivity. OpenAI has recently released GPT-4o, which includes interpretation and generation of voice and vision. Ravi Sawhney discusses how to incorporate this technology into end-user workplace technology and introduces the concept of multi-agent workflows, an idea that allows organisations to imitate entire knowledge teams.
Back in 2021 I wrote a piece for LSE Business Review in which I demonstrated the power of OpenAI’s GPT3 in being able to interpret human language by converting it into code. At the time, the technology was in its infancy and didn’t generate the spark ChatGPT did when it was released to the public in November 2022, that moment truly ignited the generative AI (GenAI) boom. Here I provide some personal thoughts on why GenAI matters and the challenges in using it for work. I also introduce the concept of multi-agent workflows as a method to boost the potential of where we can go.
It’s all about productivity
In 2024, nearly all enterprise software companies are making bets on GenAI, which perhaps has taken away some of the limelight from existing machine learning approaches such as supervised and unsupervised learning that are still crucial parts of any complete AI framework. The premise of why organisations are doing this all ties back to what got me interested in this technology in the first place: productivity.
In its more basic form, GenAI can be thought of as the most powerful autocomplete technology we have ever seen. The ability of large language models (LLMs) to predict the next word is so good that it can step in and perform knowledge worker tasks such as classifying, editing, summarising, questions and answers as well as content creation.
Additionally, variations of this technology can operate across modalities, much like human senses, to include interpretation and generation across voice and vision. In fact, in 2024 the nomenclature is shifting from LLMs to large multimodal models (LMMs) and the recent release of GPT-4o from OpenAI is evidence of this. Whether the step-in process is advisory, with a human in-the-loop or full-blown automated decision-making, it is not hard to see how GenAI has the potential to deliver transformational boost to labour productivity across the knowledge working sector. A recent paper on this very topic estimated that, when used to drive task automation, GenAI could boost labour productivity by 3.3 percentage points annually, creating $4.4 trillion of value to global GDP.
The productivity benefits perhaps take us closer to the aspiration Keynes had when he wrote Economic Possibilities for our Grandchildren in 1930, in which he forecast that in a hundred years, thanks to technological advancements improving the standard of living, we could all be doing 15-hour work weeks. This sentiment was echoed by Nobel Prize winner in economics Sir Chirstopher Pissarides, who said ChatGPT could herald 4-day work week.
So, if the potential to meaningfully transform how we work is right in front of us and is being developed at breakneck speed, then how do we bridge the gap to make this possibility a reality?
Trust and tooling
Two typical challenges need to be considered when incorporating this technology into end-user workplace technology. The largest, arguably, is managing the trust issue. By default, LLMs do not have access to your own private information, so asking it about a very specific support issue on your own product will typically produce a confident but inaccurate response, typically referred to as “hallucinations”. Fine-tuning LLMs on your own data is one option, albeit an expensive one given the hardware requirements. A much more approachable method that has become commonplace in the community is referred to as retrieval-augmented-generation (RAG) . This is where your private data is brought into the query prompt using the power of embeddings to perform lookups from a given query. This resultant response is synthesised from this data along with the LLM’s existing knowledge, resulting in something that could be considered useful, albeit with some appropriate user guidance.
The second challenge is maths. While LLMs, with some careful prompting, could create a unique, compelling and (importantly) convincing story from scratch, it would struggle with basic to intermediate maths, depending on the foundation model you are using. Here the community has introduced the concept of tooling or sometimes referred to as agents. In this paradigm, the LLM can categorise the query being asked and, rather than trying to answer it, call the appropriate ‘tool’ for the job . For example, if being asked about the weather outside, it might call a weather API service. If being asked to perform math, it would route the query to a calculator API. And if it needs to retrieve information from a database, it might convert the request to SQL or Pandas, execute the resulting code in a sandbox environment and return the result to the user, who might be none the wiser about what is going on under the hood.
The potential of multi-agent workflows
Agent frameworks with tooling are expanding the possibilities of how LLMs can be used to solve real-world problems today. However, they still largely fall short of being able to perform complex knowledge-work tasks due to limitations such as lack of memory, planning and reasoning capabilities. Multi-agent frameworks present an opportunity to tackle some of these challenges. A good way to understand how they could work is to draw a contrast with System 1 and System 2 thinking , popularised by Daniel Kahneman.
Think of System 1 as your gut instinct: fast, automatic and intuitive. In the world of LLMs, that’s like the model’s ability to generate human-like responses based on its vast training data. In contrast, System 2 thinking is slower, more deliberate, and logical, representing the model’s capacity for structured, step-by-step problem-solving and reasoning.
To fully unleash the potential of LLMs, we need to develop techniques that leverage both System 1 and System 2 capabilities. By breaking down complex tasks into smaller, manageable steps, we can guide LLMs to perform more structured and reliable problem-solving, akin to how humans would solve challenges.
Consider a team of agents, each assigned a specific role through prompt engineering, working together to tackle a single goal. That’s essentially what agent workflows, or sometimes referred to as agentic workflows, do for LLMs. Each agent is responsible for a specific subtask, and they communicate with each other, passing information and results back and forth until the overall task is complete. By designing prompts that encourage logical reasoning, step-by-step problem-solving, and collaboration with other agents, we can create a system that mimics the deliberate and rational thinking associated with System 2.
Here is where this gets exciting: agent workflows could allow us to imitate entire knowledge teams. Imagine a virtual team of AI agents, each with its workflow’s own specialism, collaborating to solve problems and make decisions just like a human team would. This could revolutionise the way we work, allowing us to tackle more complex challenges with zero or minimal human-in-the-loop supervision. It also opens the idea of allowing us to simulate how teams will react to events in a sandbox environment, where every team member is modelled as an agent in the workflow. The conversational outputs could even be saved for retrieval latter, serving as long-term memory.
By combining the raw power of System 1 thinking with the structured reasoning of System 2, we can create AI systems that not only generate human-like responses but can also tackle more complex tasks and move towards solving problems. The future of work is here, and it’s powered by the symbiosis of human ingenuity and artificial intelligence.
- Authors’ disclaimer: All views expressed are my own.
- This blog post represents the views of the author(s), not the position of LSE Business Review or the London School of Economics and Political Science.
- Featured image provided by Shutterstock
- When you leave a comment, you’re agreeing to our Comment Policy .
About the author

Ravi Sawhney is Head of Buyside Execution at Bloomberg LP. He has wide experience in the financial markets. Ravi holds a Bsc Hons in economics from LSE.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
This site uses Akismet to reduce spam. Learn how your comment data is processed .
Related Posts

Seven signs of over-hyped Fintech
July 4th, 2017.

How generative AI can support inclusion
June 16th, 2023.

Cindy Cohn: ‘They have our lives in their hands’
May 18th, 2017.

Does the partisan divide extend to online reviews?
March 19th, 2021.
Contrastive Explanations of Centralized Multi-agent Optimization Solutions
- Parisa Zehtabi J.P. Morgan AI Research
- Alberto Pozanco J.P. Morgan AI Research
- Ayala Bolch Ariel University
- Daniel Borrajo J.P. Morgan AI Research
- Sarit Kraus Department of Computer Science, Bar-Ilan University

How to Cite
- Endnote/Zotero/Mendeley (RIS)
Information
- For Readers
- For Authors
- For Librarians
Part of the PKP Publishing Services Network
Copyright © 2019, Association for the Advancement of Artificial Intelligence. All rights reserved.

IMAGES
VIDEO
COMMENTS
algorithms and agent designs, outlined in Chapters 12 and 17. 11.1 THE PLANNING PROBLEM Let us consider what can happen when an ordinary problem-solving agent using standard search algorithms—depth-first, A , and so on—comes up against large, real-world problems. That will help us design better planning agents. 375
Planning. Problem Solving vs. Planning: A simple planning agent is very similar to problem-solving agents in that it constructs plans that achieve its goals, and then executes them. The limitations of the problem-solving approach motivates the design of planning systems. To solve a planning problem using a state-space search approach we would ...
Planning: For many complex problems, problem-solving agents engage in planning. They consider different sequences of actions to achieve their goals and decide on the most suitable action plan. Actuation: After determining the best course of action, problem-solving agents take actions to interact with their environment. This can involve physical ...
CPE/CSC 580-S06 Artificial Intelligence - Intelligent Agents Well-Defined Problems exact formulation of problems and solutions initial state current state / set of states, or the state at the beginning of the problem-solving process must be known to the agent operator description of an action state space set of all states reachable from the ...
Planning vs. Problem-Solving Basic di erence: Explicit, logic-based representation States/Situations: Through descriptions of the world by logical formulae vs. data structures!The agent can explicitly think about it and communicate. Goal conditionsas logical formulae vs. goal test (black box)!The agent can also re ect on its goals.
Planning. Planning vs problem solving. Situation calculus. Plan-space planning. Lecture 10 • 1. We are going to switch gears a little bit now. In the first section of the class, we talked about problem solving, and search in general, then we did logical representations. The motivation that I gave for doing the problem solving stuff was that ...
The problem solving agent chooses a cost function that reflects its own performance measure. The solution to the problem is an action sequence that leads from initial state to goal state and the ...
Classical Planning Agents: These agents operate best in discrete, deterministic environments. They use formal languages like STRIPS (Stanford Research Institute Problem Solver) to represent actions and states. Classical Planning agents explore different action sequences using search algorithms to find a plan that achieves a predefined goal.
Problem Solving • Agent knows world dynamics [learning] • World state is finite, small enough to enumerate [logic] ... The example problem that we'll use in looking at problem solving methods is route planning in a map. 14 Lecture 2 • 14 Example: Route Planning in a Map A map is a graph where nodes are cities and links
We consider that problem to be a distributed planning problem, where each agent must formulate plans for what it will do that take into account (sufficiently well) the plans of other agents. In this paper, we characterize the variations of distributed problem solving and distributed planning, and summarize some of the basic techniques that have ...
Figure 1: Creative Problem Solving (CPS) occurs when the initial conceptual space of the agent is insufficient to com-plete the task, and the agent needs to expand its conceptual space to achieve the task goal. Traditional planning or learn-ing in AI would return a failure in such scenarios.
Abstract. Agents are entities that act upon the world. Rational agents are those that do so in an intelligent fashion. What is essential to such an agent is the ability to select and perform actions. Actions are selected by planning, and performing such actions is a matter of plan execution. So the essence of a rational agent is the ability to ...
There is a fundamental difference betv^een an agent executing an action, and thus affecting the w^orld, and a planning system manipulating representations to derive information about doing so, w^hich v^e call applying an operator. ... They can 2 Planning and Problem Solving 51 also be flexible about the point at which planning gives way to ...
Problem-solving agents use atomic representations, that is, states of the world are considered as wholes, with no internal structure visible to the problem-solving algorithms. Agents that use factored or structured representations of states are called planning agents. We distinguish between informed algorithms, in which the agent can estimate ...
Intelligent agents represent a subset of AI systems demonstrating intelligent behaviour, including adaptive learning, planning, and problem-solving. It operate in dynamic environments, where it makes decisions based on the information available to them. These agents dynamically adjust their behaviour, learning from past experiences to improve ...
The AI agent implementations explored in this survey demonstrate the rapid enhancement in language model powered reasoning, planning, and tool calling. Single and multi-agent patterns both show the ability to tackle complex multi-step problems that require advanced problem-solving skills.
The problem solving agent follows this four phase problem solving process: Goal Formulation: This is the first and most basic phase in problem solving. It arranges specific steps to establish a target/goal that demands some activity to reach it. AI agents are now used to formulate goals. Problem Formulation: It is one of the fundamental steps ...
The problem-solving agent performs precisely by defining problems and several solutions. So we can say that problem solving is a part of artificial intelligence that encompasses a number of techniques such as a tree, B-tree, heuristic algorithms to solve a problem. We can also say that a problem-solving agent is a result-driven agent and always ...
Decision-time planning enables zero-shot problem-solving because the agent only executes the planned actions if an internal prediction model verifies that the actions are successful.
In the subject of AI, planning refers to determining a sequence of actions that are known to achieve a particular objective when performed. Problem solving is finding a plan for a task in an abstract domain. A problem is difficult if an appropriate sequence of steps to solve it is not known. This chapter discusses the overall planning task from ...
The problem-solving agent perfoms precisely by defining problems and its several solutions. According to psychology, "a problem-solving refers to a state where we wish to reach to a definite goal from a present state or condition." According to computer science, a problem-solving is a part of artificial intelligence which
Problem solving is the process of diminution or abolishment of the divergence. Planning represents this process of finding out the necessary steps. In contrast to a task, the necessary steps to take that transform the original state into the final state are not yet known and must still be figured out. The steps are represented in a Plan.
The potential of multi-agent workflows. Agent frameworks with tooling are expanding the possibilities of how LLMs can be used to solve real-world problems today. However, they still largely fall short of being able to perform complex knowledge-work tasks due to limitations such as lack of memory, planning and reasoning capabilities.
In many real-world scenarios, agents are involved in optimization problems. Since most of these scenarios are over-constrained, optimal solutions do not always satisfy all agents. Some agents might be unhappy and ask questions of the form "Why does solution S not satisfy property P ?". We propose CMAOE, a domain-independent approach to obtain contrastive explanations by: (i) generating a ...