
Community Blog
Keep up-to-date on postgraduate related issues with our quick reads written by students, postdocs, professors and industry leaders.
How to Write the Scope of the Study
- By DiscoverPhDs
- August 26, 2020

What is the Scope of the Study?
The scope of the study refers to the boundaries within which your research project will be performed; this is sometimes also called the scope of research. To define the scope of the study is to define all aspects that will be considered in your research project. It is also just as important to make clear what aspects will not be covered; i.e. what is outside of the scope of the study.
Why is the Scope of the Study Important?
The scope of the study is always considered and agreed upon in the early stages of the project, before any data collection or experimental work has started. This is important because it focuses the work of the proposed study down to what is practically achievable within a given timeframe.
A well-defined research or study scope enables a researcher to give clarity to the study outcomes that are to be investigated. It makes clear why specific data points have been collected whilst others have been excluded.
Without this, it is difficult to define an end point for a research project since no limits have been defined on the work that could take place. Similarly, it can also make the approach to answering a research question too open ended.
How do you Write the Scope of the Study?
In order to write the scope of the study that you plan to perform, you must be clear on the research parameters that you will and won’t consider. These parameters usually consist of the sample size, the duration, inclusion and exclusion criteria, the methodology and any geographical or monetary constraints.
Each of these parameters will have limits placed on them so that the study can practically be performed, and the results interpreted relative to the limitations that have been defined. These parameters will also help to shape the direction of each research question you consider.
The term limitations’ is often used together with the scope of the study to describe the constraints of any parameters that are considered and also to clarify which parameters have not been considered at all. Make sure you get the balance right here between not making the scope too broad and unachievable, and it not being too restrictive, resulting in a lack of useful data.
The sample size is a commonly used parameter in the definition of the research scope. For example, a research project involving human participants may define at the start of the study that 100 participants will be recruited. This number will be determined based on an understanding of the difficulty in recruiting participants to studies and an agreement of an acceptable period of time in which to recruit this number.
Any results that are obtained by the research group can then be interpreted by others with the knowledge that the study was capped to 100 participants and an acceptance of this as a limitation of the study. In other words, it is acknowledged that recruiting 100 rather than 1,000 participants has limited the amount of data that could be collected, however this is an acceptable limitation due to the known difficulties in recruiting so many participants (e.g. the significant period of time it would take and the costs associated with this).
Example of a Scope of the Study
The follow is a (hypothetical) example of the definition of the scope of the study, with the research question investigating the impact of the COVID-19 pandemic on mental health.
Whilst the immediate negative health problems related to the COVID-19 pandemic have been well documented, the impact of the virus on the mental health (MH) of young adults (age 18-24 years) is poorly understood. The aim of this study is to report on MH changes in population group due to the pandemic.
The scope of the study is limited to recruiting 100 volunteers between the ages of 18 and 24 who will be contacted using their university email accounts. This recruitment period will last for a maximum of 2 months and will end when either 100 volunteers have been recruited or 2 months have passed. Each volunteer to the study will be asked to complete a short questionnaire in order to evaluate any changes in their MH.
From this example we can immediately see that the scope of the study has placed a constraint on the sample size to be used and/or the time frame for recruitment of volunteers. It has also introduced a limitation by only opening recruitment to people that have university emails; i.e. anyone that does not attend university will be excluded from this study.
This may be an important factor when interpreting the results of this study; the comparison of MH during the pandemic between those that do and do not attend university, is therefore outside the scope of the study here. We are also told that the methodology used to assess any changes in MH are via a questionnaire. This is a clear definition of how the outcome measure will be investigated and any other methods are not within the scope of research and their exclusion may be a limitation of the study.
The scope of the study is important to define as it enables a researcher to focus their research to within achievable parameters.

Find out the different dissertation and thesis binding options, which is best, advantages and disadvantages, typical costs, popular services and more.

A thesis and dissertation appendix contains additional information which supports your main arguments. Find out what they should include and how to format them.

Statistical treatment of data is essential for all researchers, regardless of whether you’re a biologist, computer scientist or psychologist, but what exactly is it?
Join thousands of other students and stay up to date with the latest PhD programmes, funding opportunities and advice.

Browse PhDs Now

There’s no doubt about it – writing can be difficult. Whether you’re writing the first sentence of a paper or a grant proposal, it’s easy

Stay up to date with current information being provided by the UK Government and Universities about the impact of the global pandemic on PhD research studies.

Dr Anwar gained her PhD in Biochemistry from the University of Helsinki in 2019. She is now pursuing a career within industry and becoming more active in science outreach.

Hannah is a 1st year PhD student at Cardiff Metropolitan University. The aim of her research is to clarify what strategies are the most effective in supporting young people with dyslexia.
Join Thousands of Students
Scope and Delimitations in Research
Delimitations are the boundaries that the researcher sets in a research study, deciding what to include and what to exclude. They help to narrow down the study and make it more manageable and relevant to the research goal.
Updated on October 19, 2022

All scientific research has boundaries, whether or not the authors clearly explain them. Your study's scope and delimitations are the sections where you define the broader parameters and boundaries of your research.
The scope details what your study will explore, such as the target population, extent, or study duration. Delimitations are factors and variables not included in the study.
Scope and delimitations are not methodological shortcomings; they're always under your control. Discussing these is essential because doing so shows that your project is manageable and scientifically sound.
This article covers:
- What's meant by “scope” and “delimitations”
- Why these are integral components of every study
- How and where to actually write about scope and delimitations in your manuscript
- Examples of scope and delimitations from published studies
What is the scope in a research paper?
Simply put, the scope is the domain of your research. It describes the extent to which the research question will be explored in your study.
Articulating your study's scope early on helps you make your research question focused and realistic.
It also helps decide what data you need to collect (and, therefore, what data collection tools you need to design). Getting this right is vital for both academic articles and funding applications.
What are delimitations in a research paper?
Delimitations are those factors or aspects of the research area that you'll exclude from your research. The scope and delimitations of the study are intimately linked.
Essentially, delimitations form a more detailed and narrowed-down formulation of the scope in terms of exclusion. The delimitations explain what was (intentionally) not considered within the given piece of research.
Scope and delimitations examples
Use the following examples provided by our expert PhD editors as a reference when coming up with your own scope and delimitations.
Scope example
Your research question is, “What is the impact of bullying on the mental health of adolescents?” This topic, on its own, doesn't say much about what's being investigated.
The scope, for example, could encompass:
- Variables: “bullying” (dependent variable), “mental health” (independent variable), and ways of defining or measuring them
- Bullying type: Both face-to-face and cyberbullying
- Target population: Adolescents aged 12–17
- Geographical coverage: France or only one specific town in France
Delimitations example
Look back at the previous example.
Exploring the adverse effects of bullying on adolescents' mental health is a preliminary delimitation. This one was chosen from among many possible research questions (e.g., the impact of bullying on suicide rates, or children or adults).
Delimiting factors could include:
- Research design : Mixed-methods research, including thematic analysis of semi-structured interviews and statistical analysis of a survey
- Timeframe : Data collection to run for 3 months
- Population size : 100 survey participants; 15 interviewees
- Recruitment of participants : Quota sampling (aiming for specific portions of men, women, ethnic minority students etc.)
We can see that every choice you make in planning and conducting your research inevitably excludes other possible options.
What's the difference between limitations and delimitations?
Delimitations and limitations are entirely different, although they often get mixed up. These are the main differences:

This chart explains the difference between delimitations and limitations. Delimitations are the boundaries of the study while the limitations are the characteristics of the research design or methodology.
Delimitations encompass the elements outside of the boundaries you've set and depends on your decision of what yo include and exclude. On the flip side, limitations are the elements outside of your control, such as:
- limited financial resources
- unplanned work or expenses
- unexpected events (for example, the COVID-19 pandemic)
- time constraints
- lack of technology/instruments
- unavailable evidence or previous research on the topic
Delimitations involve narrowing your study to make it more manageable and relevant to what you're trying to prove. Limitations influence the validity and reliability of your research findings. Limitations are seen as potential weaknesses in your research.
Example of the differences
To clarify these differences, go back to the limitations of the earlier example.
Limitations could comprise:
- Sample size : Not large enough to provide generalizable conclusions.
- Sampling approach : Non-probability sampling has increased bias risk. For instance, the researchers might not manage to capture the experiences of ethnic minority students.
- Methodological pitfalls : Research participants from an urban area (Paris) are likely to be more advantaged than students in rural areas. A study exploring the latter's experiences will probably yield very different findings.
Where do you write the scope and delimitations, and why?
It can be surprisingly empowering to realize you're restricted when conducting scholarly research. But this realization also makes writing up your research easier to grasp and makes it easier to see its limits and the expectations placed on it. Properly revealing this information serves your field and the greater scientific community.
Openly (but briefly) acknowledge the scope and delimitations of your study early on. The Abstract and Introduction sections are good places to set the parameters of your paper.
Next, discuss the scope and delimitations in greater detail in the Methods section. You'll need to do this to justify your methodological approach and data collection instruments, as well as analyses
At this point, spell out why these delimitations were set. What alternative options did you consider? Why did you reject alternatives? What could your study not address?
Let's say you're gathering data that can be derived from different but related experiments. You must convince the reader that the one you selected best suits your research question.
Finally, a solid paper will return to the scope and delimitations in the Findings or Discussion section. Doing so helps readers contextualize and interpret findings because the study's scope and methods influence the results.
For instance, agricultural field experiments carried out under irrigated conditions yield different results from experiments carried out without irrigation.
Being transparent about the scope and any outstanding issues increases your research's credibility and objectivity. It helps other researchers replicate your study and advance scientific understanding of the same topic (e.g., by adopting a different approach).
How do you write the scope and delimitations?
Define the scope and delimitations of your study before collecting data. This is critical. This step should be part of your research project planning.
Answering the following questions will help you address your scope and delimitations clearly and convincingly.
- What are your study's aims and objectives?
- Why did you carry out the study?
- What was the exact topic under investigation?
- Which factors and variables were included? And state why specific variables were omitted from the research scope.
- Who or what did the study explore? What was the target population?
- What was the study's location (geographical area) or setting (e.g., laboratory)?
- What was the timeframe within which you collected your data ?
- Consider a study exploring the differences between identical twins who were raised together versus identical twins who weren't. The data collection might span 5, 10, or more years.
- A study exploring a new immigration policy will cover the period since the policy came into effect and the present moment.
- How was the research conducted (research design)?
- Experimental research, qualitative, quantitative, or mixed-methods research, literature review, etc.
- What data collection tools and analysis techniques were used? e.g., If you chose quantitative methods, which statistical analysis techniques and software did you use?
- What did you find?
- What did you conclude?
Useful vocabulary for scope and delimitations

When explaining both the scope and delimitations, it's important to use the proper language to clearly state each.
For the scope , use the following language:
- This study focuses on/considers/investigates/covers the following:
- This study aims to . . . / Here, we aim to show . . . / In this study, we . . .
- The overall objective of the research is . . . / Our objective is to . . .
When stating the delimitations, use the following language:
- This [ . . . ] will not be the focus, for it has been frequently and exhaustively discusses in earlier studies.
- To review the [ . . . ] is a task that lies outside the scope of this study.
- The following [ . . . ] has been excluded from this study . . .
- This study does not provide a complete literature review of [ . . . ]. Instead, it draws on selected pertinent studies [ . . . ]
Analysis of a published scope
In one example, Simione and Gnagnarella (2020) compared the psychological and behavioral impact of COVID-19 on Italy's health workers and general population.
Here's a breakdown of the study's scope into smaller chunks and discussion of what works and why.
Also notable is that this study's delimitations include references to:
- Recruitment of participants: Convenience sampling
- Demographic characteristics of study participants: Age, sex, etc.
- Measurements methods: E.g., the death anxiety scale of the Existential Concerns Questionnaire (ECQ; van Bruggen et al., 2017) etc.
- Data analysis tool: The statistical software R
Analysis of published scope and delimitations
Scope of the study : Johnsson et al. (2019) explored the effect of in-hospital physiotherapy on postoperative physical capacity, physical activity, and lung function in patients who underwent lung cancer surgery.
The delimitations narrowed down the scope as follows:
Refine your scope, delimitations, and scientific English
English ability shouldn't limit how clear and impactful your research can be. Expert AJE editors are available to assess your science and polish your academic writing. See AJE services here .

The AJE Team
See our "Privacy Policy"

Setting Limits and Focusing Your Study: Exploring scope and delimitation
As a researcher, it can be easy to get lost in the vast expanse of information and data available. Thus, when starting a research project, one of the most important things to consider is the scope and delimitation of the study. Setting limits and focusing your study is essential to ensure that the research project is manageable, relevant, and able to produce useful results. In this article, we will explore the importance of setting limits and focusing your study through an in-depth analysis of scope and delimitation.
Company Name 123
Lorem ipsum dolor sit amet, cu usu cibo vituperata, id ius probo maiestatis inciderint, sit eu vide volutpat.
Sign Up for More Insights
Table of Contents
Scope and Delimitation – Definition and difference
Scope refers to the range of the research project and the study limitations set in place to define the boundaries of the project and delimitation refers to the specific aspects of the research project that the study will focus on.
In simpler words, scope is the breadth of your study, while delimitation is the depth of your study.
Scope and delimitation are both essential components of a research project, and they are often confused with one another. The scope defines the parameters of the study, while delimitation sets the boundaries within those parameters. The scope and delimitation of a study are usually established early on in the research process and guide the rest of the project.
Types of Scope and Delimitation

Significance of Scope and Delimitation
Setting limits and focusing your study through scope and delimitation is crucial for the following reasons:
- It allows researchers to define the research project’s boundaries, enabling them to focus on specific aspects of the project. This focus makes it easier to gather relevant data and avoid unnecessary information that might complicate the study’s results.
- Setting limits and focusing your study through scope and delimitation enables the researcher to stay within the parameters of the project’s resources.
- A well-defined scope and delimitation ensure that the research project can be completed within the available resources, such as time and budget, while still achieving the project’s objectives.
5 Steps to Setting Limits and Defining the Scope and Delimitation of Your Study
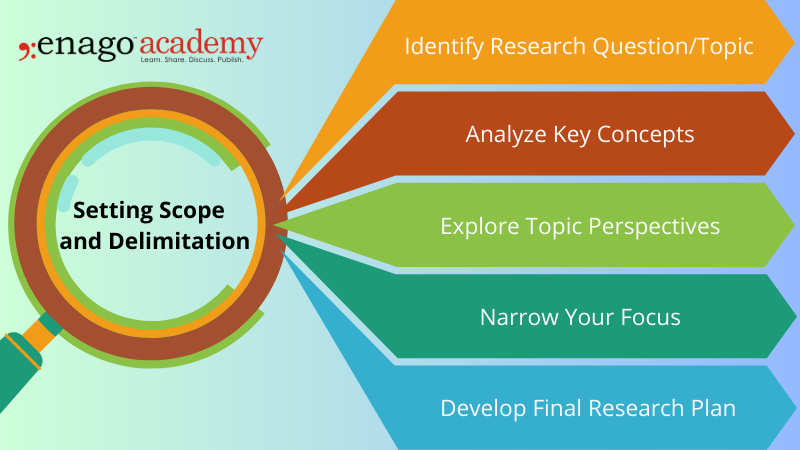
There are a few steps that you can take to set limits and focus your study.
1. Identify your research question or topic
The first step is to identify what you are interested in learning about. The research question should be specific, measurable, achievable, relevant, and time-bound (SMART). Once you have a research question or topic, you can start to narrow your focus.
2. Consider the key terms or concepts related to your topic
What are the important terms or concepts that you need to understand in order to answer your research question? Consider all available resources, such as time, budget, and data availability, when setting scope and delimitation.
The scope and delimitation should be established within the parameters of the available resources. Once you have identified the key terms or concepts, you can start to develop a glossary or list of definitions.
3. Consider the different perspectives on your topic
There are often different perspectives on any given topic. Get feedback on the proposed scope and delimitation. Advisors can provide guidance on the feasibility of the study and offer suggestions for improvement.
It is important to consider all of the different perspectives in order to get a well-rounded understanding of your topic.
4. Narrow your focus
Be specific and concise when setting scope and delimitation. The parameters of the study should be clearly defined to avoid ambiguity and ensure that the study is focused on relevant aspects of the research question.
This means deciding which aspects of your topic you will focus on and which aspects you will eliminate.
5. Develop the final research plan
Revisit and revise the scope and delimitation as needed. As the research project progresses, the scope and delimitation may need to be adjusted to ensure that the study remains focused on the research question and can produce useful results. This plan should include your research goals, methods, and timeline.
Examples of Scope and Delimitation
To better understand scope and delimitation, let us consider two examples of research questions and how scope and delimitation would apply to them.
Research question: What are the effects of social media on mental health?
Scope: The scope of the study will focus on the impact of social media on the mental health of young adults aged 18-24 in the United States.
Delimitation: The study will specifically examine the following aspects of social media: frequency of use, types of social media platforms used, and the impact of social media on self-esteem and body image.
Research question: What are the factors that influence employee job satisfaction in the healthcare industry?
Scope: The scope of the study will focus on employee job satisfaction in the healthcare industry in the United States.
Delimitation: The study will specifically examine the following factors that influence employee job satisfaction: salary, work-life balance, job security, and opportunities for career growth.
Setting limits and defining the scope and delimitation of a research study is essential to conducting effective research. By doing so, researchers can ensure that their study is focused, manageable, and feasible within the given time frame and resources. It can also help to identify areas that require further study, providing a foundation for future research.
So, the next time you embark on a research project, don’t forget to set clear limits and define the scope and delimitation of your study. It may seem like a tedious task, but it can ultimately lead to more meaningful and impactful research. And if you still can’t find a solution, reach out to Enago Academy using #AskEnago and tag @EnagoAcademy on Twitter , Facebook , and Quora .
Frequently Asked Questions
The scope in research refers to the boundaries and extent of a study, defining its specific objectives, target population, variables, methods, and limitations, which helps researchers focus and provide a clear understanding of what will be investigated.
Delimitation in research defines the specific boundaries and limitations of a study, such as geographical, temporal, or conceptual constraints, outlining what will be excluded or not within the scope of investigation, providing clarity and ensuring the study remains focused and manageable.
To write a scope; 1. Clearly define research objectives. 2. Identify specific research questions. 3. Determine the target population for the study. 4. Outline the variables to be investigated. 5. Establish limitations and constraints. 6. Set boundaries and extent of the investigation. 7. Ensure focus, clarity, and manageability. 8. Provide context for the research project.
To write delimitations; 1. Identify geographical boundaries or constraints. 2. Define the specific time period or timeframe of the study. 3. Specify the sample size or selection criteria. 4. Clarify any demographic limitations (e.g., age, gender, occupation). 5. Address any limitations related to data collection methods. 6. Consider limitations regarding the availability of resources or data. 7. Exclude specific variables or factors from the scope of the study. 8. Clearly state any conceptual boundaries or theoretical frameworks. 9. Acknowledge any potential biases or constraints in the research design. 10. Ensure that the delimitations provide a clear focus and scope for the study.

What is an example of delimitation of the study?
Thank you 💕
Thank You very simplified🩷
Thanks, I find this article very helpful
Rate this article Cancel Reply
Your email address will not be published.

Enago Academy's Most Popular Articles
![What is Academic Integrity and How to Uphold it [FREE CHECKLIST]](https://www.enago.com/academy/wp-content/uploads/2024/05/FeatureImages-59-210x136.png "scope of the study in research methodology")
Ensuring Academic Integrity and Transparency in Academic Research: A comprehensive checklist for researchers
Academic integrity is the foundation upon which the credibility and value of scientific findings are…

- Old Webinars
- Webinar Mobile App
Improving Research Manuscripts Using AI-Powered Insights: Enago reports for effective research communication
Language Quality Importance in Academia AI in Evaluating Language Quality Enago Language Reports Live Demo…

- Publishing Research
- Reporting Research
How to Optimize Your Research Process: A step-by-step guide
For researchers across disciplines, the path to uncovering novel findings and insights is often filled…

- Industry News
- Trending Now
Breaking Barriers: Sony and Nature unveil “Women in Technology Award”
Sony Group Corporation and the prestigious scientific journal Nature have collaborated to launch the inaugural…

Achieving Research Excellence: Checklist for good research practices
Academia is built on the foundation of trustworthy and high-quality research, supported by the pillars…
Choosing the Right Analytical Approach: Thematic analysis vs. content analysis for…
Research Recommendations – Guiding policy-makers for evidence-based decision making
Demystifying the Role of Confounding Variables in Research

Sign-up to read more
Subscribe for free to get unrestricted access to all our resources on research writing and academic publishing including:
- 2000+ blog articles
- 50+ Webinars
- 10+ Expert podcasts
- 50+ Infographics
- 10+ Checklists
- Research Guides
We hate spam too. We promise to protect your privacy and never spam you.
I am looking for Editing/ Proofreading services for my manuscript Tentative date of next journal submission:

What would be most effective in reducing research misconduct?
Educational resources and simple solutions for your research journey

Decoding the Scope and Delimitations of the Study in Research
Scope and delimitations of the study are two essential elements of a research paper or thesis that help to contextualize and convey the focus and boundaries of a research study. This allows readers to understand the research focus and the kind of information to expect. For researchers, especially students and early career researchers, understanding the meaning and purpose of the scope and delimitation of a study is crucial to craft a well-defined and impactful research project. In this article, we delve into the core concepts of scope and delimitation in a study, providing insightful examples, and practical tips on how to effectively incorporate them into your research endeavors.
Table of Contents
What is scope and delimitation in research
The scope of a research paper explains the context and framework for the study, outlines the extent, variables, or dimensions that will be investigated, and provides details of the parameters within which the study is conducted. Delimitations in research , on the other hand, refer to the limitations imposed on the study. It identifies aspects of the topic that will not be covered in the research, conveys why these choices were made, and how this will affect the outcome of the research. By narrowing down the scope and defining delimitations, researchers can ensure focused research and avoid pitfalls, which ensures the study remains feasible and attainable.
Example of scope and delimitation of a study
A researcher might want to study the effects of regular physical exercise on the health of senior citizens. This would be the broad scope of the study, after which the researcher would refine the scope by excluding specific groups of senior citizens, perhaps based on their age, gender, geographical location, cultural influences, and sample sizes. These then, would form the delimitations of the study; in other words, elements that describe the boundaries of the research.
The purpose of scope and delimitation in a study
The purpose of scope and delimitation in a study is to establish clear boundaries and focus for the research. This allows researchers to avoid ambiguity, set achievable objectives, and manage their project efficiently, ultimately leading to more credible and meaningful findings in their study. The scope and delimitation of a study serve several important purposes, including:
- Establishing clarity: Clearly defining the scope and delimitation of a study helps researchers and readers alike understand the boundaries of the investigation and what to expect from it.
- Focus and relevance: By setting the scope, researchers can concentrate on specific research questions, preventing the study from becoming too broad or irrelevant.
- Feasibility: Delimitations of the study prevent researchers from taking on too unrealistic or unmanageable tasks, making the research more achievable.
- Avoiding ambiguity: A well-defined scope and delimitation of the study minimizes any confusion or misinterpretation regarding the research objectives and methods.
Given the importance of both the scope and delimitations of a study, it is imperative to ensure that they are mentioned early on in the research manuscript. Most experts agree that the scope of research should be mentioned as part of the introduction and the delimitations must be mentioned as part of the methods section. Now that we’ve covered the scope and delimitation meaning and purpose, we look at how to write each of these sections.
How to write the scope of the study in research
When writing the scope of the study, remain focused on what you hope to achieve. Broadening the scope too much might make it too generic while narrowing it down too much may affect the way it would be interpreted. Ensure the scope of the study is clear, concise and accurate. Conduct a thorough literature review to understand existing literature, which will help identify gaps and refine the scope of your study.
It is helpful if you structure the scope in a way that answers the Six Ws – questions whose answers are considered basic in information-gathering.
Why: State the purpose of the research by articulating the research objectives and questions you aim to address in your study.
What: Outline the specific topic to be studied, while mentioning the variables, concepts, or aspects central to your research; these will define the extent of your study.
Where: Provide the setting or geographical location where the research study will be conducted.
When : Mention the specific timeframe within which the research data will be collected.
Who : Specify the sample size for the study and the profile of the population they will be drawn from.
How : Explain the research methodology, research design, and tools and analysis techniques.
How to write the delimitations of a study in research
When writing the delimitations of the study, researchers must provide all the details clearly and precisely. Writing the delimitations of the study requires a systematic approach to narrow down the research’s focus and establish boundaries. Follow these steps to craft delimitations effectively:
- Clearly understand the research objectives and questions you intend to address in your study.
- Conduct a comprehensive literature review to identify gaps and areas that have already been extensively covered. This helps to avoid redundancies and home in on a unique issue.
- Clearly state what aspects, variables, or factors you will be excluding in your research; mention available alternatives, if any, and why these alternatives were rejected.
- Explain how you the delimitations were set, and they contribute to the feasibility and relevance of your study, and how they align with the research objectives.
- Be sure to acknowledge limitations in your research, such as constraints related to time, resources, or data availability.
Being transparent ensures credibility, while explaining why the delimitations of your study could not be overcome with standard research methods backed up by scientific evidence can help readers understand the context better.
Differentiating between delimitations and limitations
Most early career researchers get confused and often use these two terms interchangeably which is wrong. Delimitations of a study refer to the set boundaries and specific parameters within which the research is carried out. They help narrow down your focus and makes it more relevant to what you are trying to prove.
Meanwhile, limitations in a study refer to the validity and reliability of the research being conducted. They are those elements of your study that are usually out of your immediate control but are still able to affect your findings in some way. In other words, limitation are potential weaknesses of your research.
In conclusion, scope and delimitation of a study are vital elements that shape the trajectory of your research study. The above explanations will have hopefully helped you better understand the scope and delimitations meaning, purpose, and importance in crafting focused, feasible, and impactful research studies. Be sure to follow the simple techniques to write the scope and delimitations of the study to embark on your research journey with clarity and confidence. Happy researching!
Researcher.Life is a subscription-based platform that unifies the best AI tools and services designed to speed up, simplify, and streamline every step of a researcher’s journey. The Researcher.Life All Access Pack is a one-of-a-kind subscription that unlocks full access to an AI writing assistant, literature recommender, journal finder, scientific illustration tool, and exclusive discounts on professional publication services from Editage.
Based on 21+ years of experience in academia, Researcher.Life All Access empowers researchers to put their best research forward and move closer to success. Explore our top AI Tools pack, AI Tools + Publication Services pack, or Build Your Own Plan. Find everything a researcher needs to succeed, all in one place – Get All Access now starting at just $17 a month !
Related Posts

Thesis Defense: How to Ace this Crucial Step

What is Independent Publishing in Academia?
- Resources Home 🏠
- Try SciSpace Copilot
- Search research papers
- Add Copilot Extension
- Try AI Detector
- Try Paraphraser
- Try Citation Generator
- April Papers
- June Papers
- July Papers

Here's What You Need to Understand About Research Methodology

Table of Contents
Research methodology involves a systematic and well-structured approach to conducting scholarly or scientific inquiries. Knowing the significance of research methodology and its different components is crucial as it serves as the basis for any study.
Typically, your research topic will start as a broad idea you want to investigate more thoroughly. Once you’ve identified a research problem and created research questions , you must choose the appropriate methodology and frameworks to address those questions effectively.
What is the definition of a research methodology?
Research methodology is the process or the way you intend to execute your study. The methodology section of a research paper outlines how you plan to conduct your study. It covers various steps such as collecting data, statistical analysis, observing participants, and other procedures involved in the research process
The methods section should give a description of the process that will convert your idea into a study. Additionally, the outcomes of your process must provide valid and reliable results resonant with the aims and objectives of your research. This thumb rule holds complete validity, no matter whether your paper has inclinations for qualitative or quantitative usage.
Studying research methods used in related studies can provide helpful insights and direction for your own research. Now easily discover papers related to your topic on SciSpace and utilize our AI research assistant, Copilot , to quickly review the methodologies applied in different papers.

The need for a good research methodology
While deciding on your approach towards your research, the reason or factors you weighed in choosing a particular problem and formulating a research topic need to be validated and explained. A research methodology helps you do exactly that. Moreover, a good research methodology lets you build your argument to validate your research work performed through various data collection methods, analytical methods, and other essential points.
Just imagine it as a strategy documented to provide an overview of what you intend to do.
While undertaking any research writing or performing the research itself, you may get drifted in not something of much importance. In such a case, a research methodology helps you to get back to your outlined work methodology.
A research methodology helps in keeping you accountable for your work. Additionally, it can help you evaluate whether your work is in sync with your original aims and objectives or not. Besides, a good research methodology enables you to navigate your research process smoothly and swiftly while providing effective planning to achieve your desired results.
What is the basic structure of a research methodology?
Usually, you must ensure to include the following stated aspects while deciding over the basic structure of your research methodology:
1. Your research procedure
Explain what research methods you’re going to use. Whether you intend to proceed with quantitative or qualitative, or a composite of both approaches, you need to state that explicitly. The option among the three depends on your research’s aim, objectives, and scope.
2. Provide the rationality behind your chosen approach
Based on logic and reason, let your readers know why you have chosen said research methodologies. Additionally, you have to build strong arguments supporting why your chosen research method is the best way to achieve the desired outcome.
3. Explain your mechanism
The mechanism encompasses the research methods or instruments you will use to develop your research methodology. It usually refers to your data collection methods. You can use interviews, surveys, physical questionnaires, etc., of the many available mechanisms as research methodology instruments. The data collection method is determined by the type of research and whether the data is quantitative data(includes numerical data) or qualitative data (perception, morale, etc.) Moreover, you need to put logical reasoning behind choosing a particular instrument.
4. Significance of outcomes
The results will be available once you have finished experimenting. However, you should also explain how you plan to use the data to interpret the findings. This section also aids in understanding the problem from within, breaking it down into pieces, and viewing the research problem from various perspectives.
5. Reader’s advice
Anything that you feel must be explained to spread more awareness among readers and focus groups must be included and described in detail. You should not just specify your research methodology on the assumption that a reader is aware of the topic.
All the relevant information that explains and simplifies your research paper must be included in the methodology section. If you are conducting your research in a non-traditional manner, give a logical justification and list its benefits.
6. Explain your sample space
Include information about the sample and sample space in the methodology section. The term "sample" refers to a smaller set of data that a researcher selects or chooses from a larger group of people or focus groups using a predetermined selection method. Let your readers know how you are going to distinguish between relevant and non-relevant samples. How you figured out those exact numbers to back your research methodology, i.e. the sample spacing of instruments, must be discussed thoroughly.
For example, if you are going to conduct a survey or interview, then by what procedure will you select the interviewees (or sample size in case of surveys), and how exactly will the interview or survey be conducted.
7. Challenges and limitations
This part, which is frequently assumed to be unnecessary, is actually very important. The challenges and limitations that your chosen strategy inherently possesses must be specified while you are conducting different types of research.
The importance of a good research methodology
You must have observed that all research papers, dissertations, or theses carry a chapter entirely dedicated to research methodology. This section helps maintain your credibility as a better interpreter of results rather than a manipulator.
A good research methodology always explains the procedure, data collection methods and techniques, aim, and scope of the research. In a research study, it leads to a well-organized, rationality-based approach, while the paper lacking it is often observed as messy or disorganized.
You should pay special attention to validating your chosen way towards the research methodology. This becomes extremely important in case you select an unconventional or a distinct method of execution.
Curating and developing a strong, effective research methodology can assist you in addressing a variety of situations, such as:
- When someone tries to duplicate or expand upon your research after few years.
- If a contradiction or conflict of facts occurs at a later time. This gives you the security you need to deal with these contradictions while still being able to defend your approach.
- Gaining a tactical approach in getting your research completed in time. Just ensure you are using the right approach while drafting your research methodology, and it can help you achieve your desired outcomes. Additionally, it provides a better explanation and understanding of the research question itself.
- Documenting the results so that the final outcome of the research stays as you intended it to be while starting.
Instruments you could use while writing a good research methodology
As a researcher, you must choose which tools or data collection methods that fit best in terms of the relevance of your research. This decision has to be wise.
There exists many research equipments or tools that you can use to carry out your research process. These are classified as:
a. Interviews (One-on-One or a Group)
An interview aimed to get your desired research outcomes can be undertaken in many different ways. For example, you can design your interview as structured, semi-structured, or unstructured. What sets them apart is the degree of formality in the questions. On the other hand, in a group interview, your aim should be to collect more opinions and group perceptions from the focus groups on a certain topic rather than looking out for some formal answers.
In surveys, you are in better control if you specifically draft the questions you seek the response for. For example, you may choose to include free-style questions that can be answered descriptively, or you may provide a multiple-choice type response for questions. Besides, you can also opt to choose both ways, deciding what suits your research process and purpose better.
c. Sample Groups
Similar to the group interviews, here, you can select a group of individuals and assign them a topic to discuss or freely express their opinions over that. You can simultaneously note down the answers and later draft them appropriately, deciding on the relevance of every response.
d. Observations
If your research domain is humanities or sociology, observations are the best-proven method to draw your research methodology. Of course, you can always include studying the spontaneous response of the participants towards a situation or conducting the same but in a more structured manner. A structured observation means putting the participants in a situation at a previously decided time and then studying their responses.
Of all the tools described above, it is you who should wisely choose the instruments and decide what’s the best fit for your research. You must not restrict yourself from multiple methods or a combination of a few instruments if appropriate in drafting a good research methodology.
Types of research methodology
A research methodology exists in various forms. Depending upon their approach, whether centered around words, numbers, or both, methodologies are distinguished as qualitative, quantitative, or an amalgamation of both.
1. Qualitative research methodology
When a research methodology primarily focuses on words and textual data, then it is generally referred to as qualitative research methodology. This type is usually preferred among researchers when the aim and scope of the research are mainly theoretical and explanatory.
The instruments used are observations, interviews, and sample groups. You can use this methodology if you are trying to study human behavior or response in some situations. Generally, qualitative research methodology is widely used in sociology, psychology, and other related domains.
2. Quantitative research methodology
If your research is majorly centered on data, figures, and stats, then analyzing these numerical data is often referred to as quantitative research methodology. You can use quantitative research methodology if your research requires you to validate or justify the obtained results.
In quantitative methods, surveys, tests, experiments, and evaluations of current databases can be advantageously used as instruments If your research involves testing some hypothesis, then use this methodology.
3. Amalgam methodology
As the name suggests, the amalgam methodology uses both quantitative and qualitative approaches. This methodology is used when a part of the research requires you to verify the facts and figures, whereas the other part demands you to discover the theoretical and explanatory nature of the research question.
The instruments for the amalgam methodology require you to conduct interviews and surveys, including tests and experiments. The outcome of this methodology can be insightful and valuable as it provides precise test results in line with theoretical explanations and reasoning.
The amalgam method, makes your work both factual and rational at the same time.
Final words: How to decide which is the best research methodology?
If you have kept your sincerity and awareness intact with the aims and scope of research well enough, you must have got an idea of which research methodology suits your work best.
Before deciding which research methodology answers your research question, you must invest significant time in reading and doing your homework for that. Taking references that yield relevant results should be your first approach to establishing a research methodology.
Moreover, you should never refrain from exploring other options. Before setting your work in stone, you must try all the available options as it explains why the choice of research methodology that you finally make is more appropriate than the other available options.
You should always go for a quantitative research methodology if your research requires gathering large amounts of data, figures, and statistics. This research methodology will provide you with results if your research paper involves the validation of some hypothesis.
Whereas, if you are looking for more explanations, reasons, opinions, and public perceptions around a theory, you must use qualitative research methodology.The choice of an appropriate research methodology ultimately depends on what you want to achieve through your research.
Frequently Asked Questions (FAQs) about Research Methodology
1. how to write a research methodology.
You can always provide a separate section for research methodology where you should specify details about the methods and instruments used during the research, discussions on result analysis, including insights into the background information, and conveying the research limitations.
2. What are the types of research methodology?
There generally exists four types of research methodology i.e.
- Observation
- Experimental
- Derivational
3. What is the true meaning of research methodology?
The set of techniques or procedures followed to discover and analyze the information gathered to validate or justify a research outcome is generally called Research Methodology.
4. Where lies the importance of research methodology?
Your research methodology directly reflects the validity of your research outcomes and how well-informed your research work is. Moreover, it can help future researchers cite or refer to your research if they plan to use a similar research methodology.
You might also like

Consensus GPT vs. SciSpace GPT: Choose the Best GPT for Research

Literature Review and Theoretical Framework: Understanding the Differences

Using AI for research: A beginner’s guide

Academic Research in Education
- How to Find Books, Articles and eBooks
- Books, eBooks, & Multimedia
- Evaluating Information
- Deciding on a Topic
- Creating a Thesis Statement
- The Literature Review
- Scope of Research
Defining the Scope of your Project
What is scope.
- Choosing a Design
- Citing Sources & Avoiding Plagiarism
- Contact Library
Post-Grad Collective [PGC]. (2017, February 13). Thesis Writing-Narrow the Scope [Video file]. Retrieved from https://www.youtube.com/watch?v=IlCO5yRB9No&feature=youtu.be
Learn to cite a YouTube Video!
The scope of your project sets clear parameters for your research.
A scope statement will give basic information about the depth and breadth of the project. It tells your reader exactly what you want to find out , how you will conduct your study, the reports and deliverables that will be part of the outcome of the study, and the responsibilities of the researchers involved in the study. The extent of the scope will be a part of acknowledging any biases in the research project.
Defining the scope of a project:
- focuses your research goals
- clarifies the expectations for your research project
- helps you determine potential biases in your research methodology by acknowledging the limits of your research study
- identifies the limitations of your research
- << Previous: The Literature Review
- Next: Choosing a Design >>
- Last Updated: Mar 7, 2024 9:06 AM
- URL: https://moc.libguides.com/aca_res_edu
Faculty & Staff Directory
Event Calendar
News Archives
Privacy Policy
Terms & Conditions
Public Relations
634 Henderson St.
Mount Olive, NC 28365
1-800-653-0854
- Open access
- Published: 07 September 2020
A tutorial on methodological studies: the what, when, how and why
- Lawrence Mbuagbaw ORCID: orcid.org/0000-0001-5855-5461 1 , 2 , 3 ,
- Daeria O. Lawson 1 ,
- Livia Puljak 4 ,
- David B. Allison 5 &
- Lehana Thabane 1 , 2 , 6 , 7 , 8
BMC Medical Research Methodology volume 20 , Article number: 226 ( 2020 ) Cite this article
40k Accesses
54 Citations
60 Altmetric
Metrics details
Methodological studies – studies that evaluate the design, analysis or reporting of other research-related reports – play an important role in health research. They help to highlight issues in the conduct of research with the aim of improving health research methodology, and ultimately reducing research waste.
We provide an overview of some of the key aspects of methodological studies such as what they are, and when, how and why they are done. We adopt a “frequently asked questions” format to facilitate reading this paper and provide multiple examples to help guide researchers interested in conducting methodological studies. Some of the topics addressed include: is it necessary to publish a study protocol? How to select relevant research reports and databases for a methodological study? What approaches to data extraction and statistical analysis should be considered when conducting a methodological study? What are potential threats to validity and is there a way to appraise the quality of methodological studies?
Appropriate reflection and application of basic principles of epidemiology and biostatistics are required in the design and analysis of methodological studies. This paper provides an introduction for further discussion about the conduct of methodological studies.
Peer Review reports
The field of meta-research (or research-on-research) has proliferated in recent years in response to issues with research quality and conduct [ 1 , 2 , 3 ]. As the name suggests, this field targets issues with research design, conduct, analysis and reporting. Various types of research reports are often examined as the unit of analysis in these studies (e.g. abstracts, full manuscripts, trial registry entries). Like many other novel fields of research, meta-research has seen a proliferation of use before the development of reporting guidance. For example, this was the case with randomized trials for which risk of bias tools and reporting guidelines were only developed much later – after many trials had been published and noted to have limitations [ 4 , 5 ]; and for systematic reviews as well [ 6 , 7 , 8 ]. However, in the absence of formal guidance, studies that report on research differ substantially in how they are named, conducted and reported [ 9 , 10 ]. This creates challenges in identifying, summarizing and comparing them. In this tutorial paper, we will use the term methodological study to refer to any study that reports on the design, conduct, analysis or reporting of primary or secondary research-related reports (such as trial registry entries and conference abstracts).
In the past 10 years, there has been an increase in the use of terms related to methodological studies (based on records retrieved with a keyword search [in the title and abstract] for “methodological review” and “meta-epidemiological study” in PubMed up to December 2019), suggesting that these studies may be appearing more frequently in the literature. See Fig. 1 .

Trends in the number studies that mention “methodological review” or “meta-
epidemiological study” in PubMed.
The methods used in many methodological studies have been borrowed from systematic and scoping reviews. This practice has influenced the direction of the field, with many methodological studies including searches of electronic databases, screening of records, duplicate data extraction and assessments of risk of bias in the included studies. However, the research questions posed in methodological studies do not always require the approaches listed above, and guidance is needed on when and how to apply these methods to a methodological study. Even though methodological studies can be conducted on qualitative or mixed methods research, this paper focuses on and draws examples exclusively from quantitative research.
The objectives of this paper are to provide some insights on how to conduct methodological studies so that there is greater consistency between the research questions posed, and the design, analysis and reporting of findings. We provide multiple examples to illustrate concepts and a proposed framework for categorizing methodological studies in quantitative research.
What is a methodological study?
Any study that describes or analyzes methods (design, conduct, analysis or reporting) in published (or unpublished) literature is a methodological study. Consequently, the scope of methodological studies is quite extensive and includes, but is not limited to, topics as diverse as: research question formulation [ 11 ]; adherence to reporting guidelines [ 12 , 13 , 14 ] and consistency in reporting [ 15 ]; approaches to study analysis [ 16 ]; investigating the credibility of analyses [ 17 ]; and studies that synthesize these methodological studies [ 18 ]. While the nomenclature of methodological studies is not uniform, the intents and purposes of these studies remain fairly consistent – to describe or analyze methods in primary or secondary studies. As such, methodological studies may also be classified as a subtype of observational studies.
Parallel to this are experimental studies that compare different methods. Even though they play an important role in informing optimal research methods, experimental methodological studies are beyond the scope of this paper. Examples of such studies include the randomized trials by Buscemi et al., comparing single data extraction to double data extraction [ 19 ], and Carrasco-Labra et al., comparing approaches to presenting findings in Grading of Recommendations, Assessment, Development and Evaluations (GRADE) summary of findings tables [ 20 ]. In these studies, the unit of analysis is the person or groups of individuals applying the methods. We also direct readers to the Studies Within a Trial (SWAT) and Studies Within a Review (SWAR) programme operated through the Hub for Trials Methodology Research, for further reading as a potential useful resource for these types of experimental studies [ 21 ]. Lastly, this paper is not meant to inform the conduct of research using computational simulation and mathematical modeling for which some guidance already exists [ 22 ], or studies on the development of methods using consensus-based approaches.
When should we conduct a methodological study?
Methodological studies occupy a unique niche in health research that allows them to inform methodological advances. Methodological studies should also be conducted as pre-cursors to reporting guideline development, as they provide an opportunity to understand current practices, and help to identify the need for guidance and gaps in methodological or reporting quality. For example, the development of the popular Preferred Reporting Items of Systematic reviews and Meta-Analyses (PRISMA) guidelines were preceded by methodological studies identifying poor reporting practices [ 23 , 24 ]. In these instances, after the reporting guidelines are published, methodological studies can also be used to monitor uptake of the guidelines.
These studies can also be conducted to inform the state of the art for design, analysis and reporting practices across different types of health research fields, with the aim of improving research practices, and preventing or reducing research waste. For example, Samaan et al. conducted a scoping review of adherence to different reporting guidelines in health care literature [ 18 ]. Methodological studies can also be used to determine the factors associated with reporting practices. For example, Abbade et al. investigated journal characteristics associated with the use of the Participants, Intervention, Comparison, Outcome, Timeframe (PICOT) format in framing research questions in trials of venous ulcer disease [ 11 ].
How often are methodological studies conducted?
There is no clear answer to this question. Based on a search of PubMed, the use of related terms (“methodological review” and “meta-epidemiological study”) – and therefore, the number of methodological studies – is on the rise. However, many other terms are used to describe methodological studies. There are also many studies that explore design, conduct, analysis or reporting of research reports, but that do not use any specific terms to describe or label their study design in terms of “methodology”. This diversity in nomenclature makes a census of methodological studies elusive. Appropriate terminology and key words for methodological studies are needed to facilitate improved accessibility for end-users.
Why do we conduct methodological studies?
Methodological studies provide information on the design, conduct, analysis or reporting of primary and secondary research and can be used to appraise quality, quantity, completeness, accuracy and consistency of health research. These issues can be explored in specific fields, journals, databases, geographical regions and time periods. For example, Areia et al. explored the quality of reporting of endoscopic diagnostic studies in gastroenterology [ 25 ]; Knol et al. investigated the reporting of p -values in baseline tables in randomized trial published in high impact journals [ 26 ]; Chen et al. describe adherence to the Consolidated Standards of Reporting Trials (CONSORT) statement in Chinese Journals [ 27 ]; and Hopewell et al. describe the effect of editors’ implementation of CONSORT guidelines on reporting of abstracts over time [ 28 ]. Methodological studies provide useful information to researchers, clinicians, editors, publishers and users of health literature. As a result, these studies have been at the cornerstone of important methodological developments in the past two decades and have informed the development of many health research guidelines including the highly cited CONSORT statement [ 5 ].
Where can we find methodological studies?
Methodological studies can be found in most common biomedical bibliographic databases (e.g. Embase, MEDLINE, PubMed, Web of Science). However, the biggest caveat is that methodological studies are hard to identify in the literature due to the wide variety of names used and the lack of comprehensive databases dedicated to them. A handful can be found in the Cochrane Library as “Cochrane Methodology Reviews”, but these studies only cover methodological issues related to systematic reviews. Previous attempts to catalogue all empirical studies of methods used in reviews were abandoned 10 years ago [ 29 ]. In other databases, a variety of search terms may be applied with different levels of sensitivity and specificity.
Some frequently asked questions about methodological studies
In this section, we have outlined responses to questions that might help inform the conduct of methodological studies.
Q: How should I select research reports for my methodological study?
A: Selection of research reports for a methodological study depends on the research question and eligibility criteria. Once a clear research question is set and the nature of literature one desires to review is known, one can then begin the selection process. Selection may begin with a broad search, especially if the eligibility criteria are not apparent. For example, a methodological study of Cochrane Reviews of HIV would not require a complex search as all eligible studies can easily be retrieved from the Cochrane Library after checking a few boxes [ 30 ]. On the other hand, a methodological study of subgroup analyses in trials of gastrointestinal oncology would require a search to find such trials, and further screening to identify trials that conducted a subgroup analysis [ 31 ].
The strategies used for identifying participants in observational studies can apply here. One may use a systematic search to identify all eligible studies. If the number of eligible studies is unmanageable, a random sample of articles can be expected to provide comparable results if it is sufficiently large [ 32 ]. For example, Wilson et al. used a random sample of trials from the Cochrane Stroke Group’s Trial Register to investigate completeness of reporting [ 33 ]. It is possible that a simple random sample would lead to underrepresentation of units (i.e. research reports) that are smaller in number. This is relevant if the investigators wish to compare multiple groups but have too few units in one group. In this case a stratified sample would help to create equal groups. For example, in a methodological study comparing Cochrane and non-Cochrane reviews, Kahale et al. drew random samples from both groups [ 34 ]. Alternatively, systematic or purposeful sampling strategies can be used and we encourage researchers to justify their selected approaches based on the study objective.
Q: How many databases should I search?
A: The number of databases one should search would depend on the approach to sampling, which can include targeting the entire “population” of interest or a sample of that population. If you are interested in including the entire target population for your research question, or drawing a random or systematic sample from it, then a comprehensive and exhaustive search for relevant articles is required. In this case, we recommend using systematic approaches for searching electronic databases (i.e. at least 2 databases with a replicable and time stamped search strategy). The results of your search will constitute a sampling frame from which eligible studies can be drawn.
Alternatively, if your approach to sampling is purposeful, then we recommend targeting the database(s) or data sources (e.g. journals, registries) that include the information you need. For example, if you are conducting a methodological study of high impact journals in plastic surgery and they are all indexed in PubMed, you likely do not need to search any other databases. You may also have a comprehensive list of all journals of interest and can approach your search using the journal names in your database search (or by accessing the journal archives directly from the journal’s website). Even though one could also search journals’ web pages directly, using a database such as PubMed has multiple advantages, such as the use of filters, so the search can be narrowed down to a certain period, or study types of interest. Furthermore, individual journals’ web sites may have different search functionalities, which do not necessarily yield a consistent output.
Q: Should I publish a protocol for my methodological study?
A: A protocol is a description of intended research methods. Currently, only protocols for clinical trials require registration [ 35 ]. Protocols for systematic reviews are encouraged but no formal recommendation exists. The scientific community welcomes the publication of protocols because they help protect against selective outcome reporting, the use of post hoc methodologies to embellish results, and to help avoid duplication of efforts [ 36 ]. While the latter two risks exist in methodological research, the negative consequences may be substantially less than for clinical outcomes. In a sample of 31 methodological studies, 7 (22.6%) referenced a published protocol [ 9 ]. In the Cochrane Library, there are 15 protocols for methodological reviews (21 July 2020). This suggests that publishing protocols for methodological studies is not uncommon.
Authors can consider publishing their study protocol in a scholarly journal as a manuscript. Advantages of such publication include obtaining peer-review feedback about the planned study, and easy retrieval by searching databases such as PubMed. The disadvantages in trying to publish protocols includes delays associated with manuscript handling and peer review, as well as costs, as few journals publish study protocols, and those journals mostly charge article-processing fees [ 37 ]. Authors who would like to make their protocol publicly available without publishing it in scholarly journals, could deposit their study protocols in publicly available repositories, such as the Open Science Framework ( https://osf.io/ ).
Q: How to appraise the quality of a methodological study?
A: To date, there is no published tool for appraising the risk of bias in a methodological study, but in principle, a methodological study could be considered as a type of observational study. Therefore, during conduct or appraisal, care should be taken to avoid the biases common in observational studies [ 38 ]. These biases include selection bias, comparability of groups, and ascertainment of exposure or outcome. In other words, to generate a representative sample, a comprehensive reproducible search may be necessary to build a sampling frame. Additionally, random sampling may be necessary to ensure that all the included research reports have the same probability of being selected, and the screening and selection processes should be transparent and reproducible. To ensure that the groups compared are similar in all characteristics, matching, random sampling or stratified sampling can be used. Statistical adjustments for between-group differences can also be applied at the analysis stage. Finally, duplicate data extraction can reduce errors in assessment of exposures or outcomes.
Q: Should I justify a sample size?
A: In all instances where one is not using the target population (i.e. the group to which inferences from the research report are directed) [ 39 ], a sample size justification is good practice. The sample size justification may take the form of a description of what is expected to be achieved with the number of articles selected, or a formal sample size estimation that outlines the number of articles required to answer the research question with a certain precision and power. Sample size justifications in methodological studies are reasonable in the following instances:
Comparing two groups
Determining a proportion, mean or another quantifier
Determining factors associated with an outcome using regression-based analyses
For example, El Dib et al. computed a sample size requirement for a methodological study of diagnostic strategies in randomized trials, based on a confidence interval approach [ 40 ].
Q: What should I call my study?
A: Other terms which have been used to describe/label methodological studies include “ methodological review ”, “methodological survey” , “meta-epidemiological study” , “systematic review” , “systematic survey”, “meta-research”, “research-on-research” and many others. We recommend that the study nomenclature be clear, unambiguous, informative and allow for appropriate indexing. Methodological study nomenclature that should be avoided includes “ systematic review” – as this will likely be confused with a systematic review of a clinical question. “ Systematic survey” may also lead to confusion about whether the survey was systematic (i.e. using a preplanned methodology) or a survey using “ systematic” sampling (i.e. a sampling approach using specific intervals to determine who is selected) [ 32 ]. Any of the above meanings of the words “ systematic” may be true for methodological studies and could be potentially misleading. “ Meta-epidemiological study” is ideal for indexing, but not very informative as it describes an entire field. The term “ review ” may point towards an appraisal or “review” of the design, conduct, analysis or reporting (or methodological components) of the targeted research reports, yet it has also been used to describe narrative reviews [ 41 , 42 ]. The term “ survey ” is also in line with the approaches used in many methodological studies [ 9 ], and would be indicative of the sampling procedures of this study design. However, in the absence of guidelines on nomenclature, the term “ methodological study ” is broad enough to capture most of the scenarios of such studies.
Q: Should I account for clustering in my methodological study?
A: Data from methodological studies are often clustered. For example, articles coming from a specific source may have different reporting standards (e.g. the Cochrane Library). Articles within the same journal may be similar due to editorial practices and policies, reporting requirements and endorsement of guidelines. There is emerging evidence that these are real concerns that should be accounted for in analyses [ 43 ]. Some cluster variables are described in the section: “ What variables are relevant to methodological studies?”
A variety of modelling approaches can be used to account for correlated data, including the use of marginal, fixed or mixed effects regression models with appropriate computation of standard errors [ 44 ]. For example, Kosa et al. used generalized estimation equations to account for correlation of articles within journals [ 15 ]. Not accounting for clustering could lead to incorrect p -values, unduly narrow confidence intervals, and biased estimates [ 45 ].
Q: Should I extract data in duplicate?
A: Yes. Duplicate data extraction takes more time but results in less errors [ 19 ]. Data extraction errors in turn affect the effect estimate [ 46 ], and therefore should be mitigated. Duplicate data extraction should be considered in the absence of other approaches to minimize extraction errors. However, much like systematic reviews, this area will likely see rapid new advances with machine learning and natural language processing technologies to support researchers with screening and data extraction [ 47 , 48 ]. However, experience plays an important role in the quality of extracted data and inexperienced extractors should be paired with experienced extractors [ 46 , 49 ].
Q: Should I assess the risk of bias of research reports included in my methodological study?
A : Risk of bias is most useful in determining the certainty that can be placed in the effect measure from a study. In methodological studies, risk of bias may not serve the purpose of determining the trustworthiness of results, as effect measures are often not the primary goal of methodological studies. Determining risk of bias in methodological studies is likely a practice borrowed from systematic review methodology, but whose intrinsic value is not obvious in methodological studies. When it is part of the research question, investigators often focus on one aspect of risk of bias. For example, Speich investigated how blinding was reported in surgical trials [ 50 ], and Abraha et al., investigated the application of intention-to-treat analyses in systematic reviews and trials [ 51 ].
Q: What variables are relevant to methodological studies?
A: There is empirical evidence that certain variables may inform the findings in a methodological study. We outline some of these and provide a brief overview below:
Country: Countries and regions differ in their research cultures, and the resources available to conduct research. Therefore, it is reasonable to believe that there may be differences in methodological features across countries. Methodological studies have reported loco-regional differences in reporting quality [ 52 , 53 ]. This may also be related to challenges non-English speakers face in publishing papers in English.
Authors’ expertise: The inclusion of authors with expertise in research methodology, biostatistics, and scientific writing is likely to influence the end-product. Oltean et al. found that among randomized trials in orthopaedic surgery, the use of analyses that accounted for clustering was more likely when specialists (e.g. statistician, epidemiologist or clinical trials methodologist) were included on the study team [ 54 ]. Fleming et al. found that including methodologists in the review team was associated with appropriate use of reporting guidelines [ 55 ].
Source of funding and conflicts of interest: Some studies have found that funded studies report better [ 56 , 57 ], while others do not [ 53 , 58 ]. The presence of funding would indicate the availability of resources deployed to ensure optimal design, conduct, analysis and reporting. However, the source of funding may introduce conflicts of interest and warrant assessment. For example, Kaiser et al. investigated the effect of industry funding on obesity or nutrition randomized trials and found that reporting quality was similar [ 59 ]. Thomas et al. looked at reporting quality of long-term weight loss trials and found that industry funded studies were better [ 60 ]. Kan et al. examined the association between industry funding and “positive trials” (trials reporting a significant intervention effect) and found that industry funding was highly predictive of a positive trial [ 61 ]. This finding is similar to that of a recent Cochrane Methodology Review by Hansen et al. [ 62 ]
Journal characteristics: Certain journals’ characteristics may influence the study design, analysis or reporting. Characteristics such as journal endorsement of guidelines [ 63 , 64 ], and Journal Impact Factor (JIF) have been shown to be associated with reporting [ 63 , 65 , 66 , 67 ].
Study size (sample size/number of sites): Some studies have shown that reporting is better in larger studies [ 53 , 56 , 58 ].
Year of publication: It is reasonable to assume that design, conduct, analysis and reporting of research will change over time. Many studies have demonstrated improvements in reporting over time or after the publication of reporting guidelines [ 68 , 69 ].
Type of intervention: In a methodological study of reporting quality of weight loss intervention studies, Thabane et al. found that trials of pharmacologic interventions were reported better than trials of non-pharmacologic interventions [ 70 ].
Interactions between variables: Complex interactions between the previously listed variables are possible. High income countries with more resources may be more likely to conduct larger studies and incorporate a variety of experts. Authors in certain countries may prefer certain journals, and journal endorsement of guidelines and editorial policies may change over time.
Q: Should I focus only on high impact journals?
A: Investigators may choose to investigate only high impact journals because they are more likely to influence practice and policy, or because they assume that methodological standards would be higher. However, the JIF may severely limit the scope of articles included and may skew the sample towards articles with positive findings. The generalizability and applicability of findings from a handful of journals must be examined carefully, especially since the JIF varies over time. Even among journals that are all “high impact”, variations exist in methodological standards.
Q: Can I conduct a methodological study of qualitative research?
A: Yes. Even though a lot of methodological research has been conducted in the quantitative research field, methodological studies of qualitative studies are feasible. Certain databases that catalogue qualitative research including the Cumulative Index to Nursing & Allied Health Literature (CINAHL) have defined subject headings that are specific to methodological research (e.g. “research methodology”). Alternatively, one could also conduct a qualitative methodological review; that is, use qualitative approaches to synthesize methodological issues in qualitative studies.
Q: What reporting guidelines should I use for my methodological study?
A: There is no guideline that covers the entire scope of methodological studies. One adaptation of the PRISMA guidelines has been published, which works well for studies that aim to use the entire target population of research reports [ 71 ]. However, it is not widely used (40 citations in 2 years as of 09 December 2019), and methodological studies that are designed as cross-sectional or before-after studies require a more fit-for purpose guideline. A more encompassing reporting guideline for a broad range of methodological studies is currently under development [ 72 ]. However, in the absence of formal guidance, the requirements for scientific reporting should be respected, and authors of methodological studies should focus on transparency and reproducibility.
Q: What are the potential threats to validity and how can I avoid them?
A: Methodological studies may be compromised by a lack of internal or external validity. The main threats to internal validity in methodological studies are selection and confounding bias. Investigators must ensure that the methods used to select articles does not make them differ systematically from the set of articles to which they would like to make inferences. For example, attempting to make extrapolations to all journals after analyzing high-impact journals would be misleading.
Many factors (confounders) may distort the association between the exposure and outcome if the included research reports differ with respect to these factors [ 73 ]. For example, when examining the association between source of funding and completeness of reporting, it may be necessary to account for journals that endorse the guidelines. Confounding bias can be addressed by restriction, matching and statistical adjustment [ 73 ]. Restriction appears to be the method of choice for many investigators who choose to include only high impact journals or articles in a specific field. For example, Knol et al. examined the reporting of p -values in baseline tables of high impact journals [ 26 ]. Matching is also sometimes used. In the methodological study of non-randomized interventional studies of elective ventral hernia repair, Parker et al. matched prospective studies with retrospective studies and compared reporting standards [ 74 ]. Some other methodological studies use statistical adjustments. For example, Zhang et al. used regression techniques to determine the factors associated with missing participant data in trials [ 16 ].
With regard to external validity, researchers interested in conducting methodological studies must consider how generalizable or applicable their findings are. This should tie in closely with the research question and should be explicit. For example. Findings from methodological studies on trials published in high impact cardiology journals cannot be assumed to be applicable to trials in other fields. However, investigators must ensure that their sample truly represents the target sample either by a) conducting a comprehensive and exhaustive search, or b) using an appropriate and justified, randomly selected sample of research reports.
Even applicability to high impact journals may vary based on the investigators’ definition, and over time. For example, for high impact journals in the field of general medicine, Bouwmeester et al. included the Annals of Internal Medicine (AIM), BMJ, the Journal of the American Medical Association (JAMA), Lancet, the New England Journal of Medicine (NEJM), and PLoS Medicine ( n = 6) [ 75 ]. In contrast, the high impact journals selected in the methodological study by Schiller et al. were BMJ, JAMA, Lancet, and NEJM ( n = 4) [ 76 ]. Another methodological study by Kosa et al. included AIM, BMJ, JAMA, Lancet and NEJM ( n = 5). In the methodological study by Thabut et al., journals with a JIF greater than 5 were considered to be high impact. Riado Minguez et al. used first quartile journals in the Journal Citation Reports (JCR) for a specific year to determine “high impact” [ 77 ]. Ultimately, the definition of high impact will be based on the number of journals the investigators are willing to include, the year of impact and the JIF cut-off [ 78 ]. We acknowledge that the term “generalizability” may apply differently for methodological studies, especially when in many instances it is possible to include the entire target population in the sample studied.
Finally, methodological studies are not exempt from information bias which may stem from discrepancies in the included research reports [ 79 ], errors in data extraction, or inappropriate interpretation of the information extracted. Likewise, publication bias may also be a concern in methodological studies, but such concepts have not yet been explored.
A proposed framework
In order to inform discussions about methodological studies, the development of guidance for what should be reported, we have outlined some key features of methodological studies that can be used to classify them. For each of the categories outlined below, we provide an example. In our experience, the choice of approach to completing a methodological study can be informed by asking the following four questions:
What is the aim?
Methodological studies that investigate bias
A methodological study may be focused on exploring sources of bias in primary or secondary studies (meta-bias), or how bias is analyzed. We have taken care to distinguish bias (i.e. systematic deviations from the truth irrespective of the source) from reporting quality or completeness (i.e. not adhering to a specific reporting guideline or norm). An example of where this distinction would be important is in the case of a randomized trial with no blinding. This study (depending on the nature of the intervention) would be at risk of performance bias. However, if the authors report that their study was not blinded, they would have reported adequately. In fact, some methodological studies attempt to capture both “quality of conduct” and “quality of reporting”, such as Richie et al., who reported on the risk of bias in randomized trials of pharmacy practice interventions [ 80 ]. Babic et al. investigated how risk of bias was used to inform sensitivity analyses in Cochrane reviews [ 81 ]. Further, biases related to choice of outcomes can also be explored. For example, Tan et al investigated differences in treatment effect size based on the outcome reported [ 82 ].
Methodological studies that investigate quality (or completeness) of reporting
Methodological studies may report quality of reporting against a reporting checklist (i.e. adherence to guidelines) or against expected norms. For example, Croituro et al. report on the quality of reporting in systematic reviews published in dermatology journals based on their adherence to the PRISMA statement [ 83 ], and Khan et al. described the quality of reporting of harms in randomized controlled trials published in high impact cardiovascular journals based on the CONSORT extension for harms [ 84 ]. Other methodological studies investigate reporting of certain features of interest that may not be part of formally published checklists or guidelines. For example, Mbuagbaw et al. described how often the implications for research are elaborated using the Evidence, Participants, Intervention, Comparison, Outcome, Timeframe (EPICOT) format [ 30 ].
Methodological studies that investigate the consistency of reporting
Sometimes investigators may be interested in how consistent reports of the same research are, as it is expected that there should be consistency between: conference abstracts and published manuscripts; manuscript abstracts and manuscript main text; and trial registration and published manuscript. For example, Rosmarakis et al. investigated consistency between conference abstracts and full text manuscripts [ 85 ].
Methodological studies that investigate factors associated with reporting
In addition to identifying issues with reporting in primary and secondary studies, authors of methodological studies may be interested in determining the factors that are associated with certain reporting practices. Many methodological studies incorporate this, albeit as a secondary outcome. For example, Farrokhyar et al. investigated the factors associated with reporting quality in randomized trials of coronary artery bypass grafting surgery [ 53 ].
Methodological studies that investigate methods
Methodological studies may also be used to describe methods or compare methods, and the factors associated with methods. Muller et al. described the methods used for systematic reviews and meta-analyses of observational studies [ 86 ].
Methodological studies that summarize other methodological studies
Some methodological studies synthesize results from other methodological studies. For example, Li et al. conducted a scoping review of methodological reviews that investigated consistency between full text and abstracts in primary biomedical research [ 87 ].
Methodological studies that investigate nomenclature and terminology
Some methodological studies may investigate the use of names and terms in health research. For example, Martinic et al. investigated the definitions of systematic reviews used in overviews of systematic reviews (OSRs), meta-epidemiological studies and epidemiology textbooks [ 88 ].
Other types of methodological studies
In addition to the previously mentioned experimental methodological studies, there may exist other types of methodological studies not captured here.
What is the design?
Methodological studies that are descriptive
Most methodological studies are purely descriptive and report their findings as counts (percent) and means (standard deviation) or medians (interquartile range). For example, Mbuagbaw et al. described the reporting of research recommendations in Cochrane HIV systematic reviews [ 30 ]. Gohari et al. described the quality of reporting of randomized trials in diabetes in Iran [ 12 ].
Methodological studies that are analytical
Some methodological studies are analytical wherein “analytical studies identify and quantify associations, test hypotheses, identify causes and determine whether an association exists between variables, such as between an exposure and a disease.” [ 89 ] In the case of methodological studies all these investigations are possible. For example, Kosa et al. investigated the association between agreement in primary outcome from trial registry to published manuscript and study covariates. They found that larger and more recent studies were more likely to have agreement [ 15 ]. Tricco et al. compared the conclusion statements from Cochrane and non-Cochrane systematic reviews with a meta-analysis of the primary outcome and found that non-Cochrane reviews were more likely to report positive findings. These results are a test of the null hypothesis that the proportions of Cochrane and non-Cochrane reviews that report positive results are equal [ 90 ].
What is the sampling strategy?
Methodological studies that include the target population
Methodological reviews with narrow research questions may be able to include the entire target population. For example, in the methodological study of Cochrane HIV systematic reviews, Mbuagbaw et al. included all of the available studies ( n = 103) [ 30 ].
Methodological studies that include a sample of the target population
Many methodological studies use random samples of the target population [ 33 , 91 , 92 ]. Alternatively, purposeful sampling may be used, limiting the sample to a subset of research-related reports published within a certain time period, or in journals with a certain ranking or on a topic. Systematic sampling can also be used when random sampling may be challenging to implement.
What is the unit of analysis?
Methodological studies with a research report as the unit of analysis
Many methodological studies use a research report (e.g. full manuscript of study, abstract portion of the study) as the unit of analysis, and inferences can be made at the study-level. However, both published and unpublished research-related reports can be studied. These may include articles, conference abstracts, registry entries etc.
Methodological studies with a design, analysis or reporting item as the unit of analysis
Some methodological studies report on items which may occur more than once per article. For example, Paquette et al. report on subgroup analyses in Cochrane reviews of atrial fibrillation in which 17 systematic reviews planned 56 subgroup analyses [ 93 ].
This framework is outlined in Fig. 2 .

A proposed framework for methodological studies
Conclusions
Methodological studies have examined different aspects of reporting such as quality, completeness, consistency and adherence to reporting guidelines. As such, many of the methodological study examples cited in this tutorial are related to reporting. However, as an evolving field, the scope of research questions that can be addressed by methodological studies is expected to increase.
In this paper we have outlined the scope and purpose of methodological studies, along with examples of instances in which various approaches have been used. In the absence of formal guidance on the design, conduct, analysis and reporting of methodological studies, we have provided some advice to help make methodological studies consistent. This advice is grounded in good contemporary scientific practice. Generally, the research question should tie in with the sampling approach and planned analysis. We have also highlighted the variables that may inform findings from methodological studies. Lastly, we have provided suggestions for ways in which authors can categorize their methodological studies to inform their design and analysis.
Availability of data and materials
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
Abbreviations
Consolidated Standards of Reporting Trials
Evidence, Participants, Intervention, Comparison, Outcome, Timeframe
Grading of Recommendations, Assessment, Development and Evaluations
Participants, Intervention, Comparison, Outcome, Timeframe
Preferred Reporting Items of Systematic reviews and Meta-Analyses
Studies Within a Review
Studies Within a Trial
Chalmers I, Glasziou P. Avoidable waste in the production and reporting of research evidence. Lancet. 2009;374(9683):86–9.
PubMed Google Scholar
Chan AW, Song F, Vickers A, Jefferson T, Dickersin K, Gotzsche PC, Krumholz HM, Ghersi D, van der Worp HB. Increasing value and reducing waste: addressing inaccessible research. Lancet. 2014;383(9913):257–66.
PubMed PubMed Central Google Scholar
Ioannidis JP, Greenland S, Hlatky MA, Khoury MJ, Macleod MR, Moher D, Schulz KF, Tibshirani R. Increasing value and reducing waste in research design, conduct, and analysis. Lancet. 2014;383(9912):166–75.
Higgins JP, Altman DG, Gotzsche PC, Juni P, Moher D, Oxman AD, Savovic J, Schulz KF, Weeks L, Sterne JA. The Cochrane Collaboration's tool for assessing risk of bias in randomised trials. BMJ. 2011;343:d5928.
Moher D, Schulz KF, Altman DG. The CONSORT statement: revised recommendations for improving the quality of reports of parallel-group randomised trials. Lancet. 2001;357.
Liberati A, Altman DG, Tetzlaff J, Mulrow C, Gotzsche PC, Ioannidis JP, Clarke M, Devereaux PJ, Kleijnen J, Moher D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: explanation and elaboration. PLoS Med. 2009;6(7):e1000100.
Shea BJ, Hamel C, Wells GA, Bouter LM, Kristjansson E, Grimshaw J, Henry DA, Boers M. AMSTAR is a reliable and valid measurement tool to assess the methodological quality of systematic reviews. J Clin Epidemiol. 2009;62(10):1013–20.
Shea BJ, Reeves BC, Wells G, Thuku M, Hamel C, Moran J, Moher D, Tugwell P, Welch V, Kristjansson E, et al. AMSTAR 2: a critical appraisal tool for systematic reviews that include randomised or non-randomised studies of healthcare interventions, or both. Bmj. 2017;358:j4008.
Lawson DO, Leenus A, Mbuagbaw L. Mapping the nomenclature, methodology, and reporting of studies that review methods: a pilot methodological review. Pilot Feasibility Studies. 2020;6(1):13.
Puljak L, Makaric ZL, Buljan I, Pieper D. What is a meta-epidemiological study? Analysis of published literature indicated heterogeneous study designs and definitions. J Comp Eff Res. 2020.
Abbade LPF, Wang M, Sriganesh K, Jin Y, Mbuagbaw L, Thabane L. The framing of research questions using the PICOT format in randomized controlled trials of venous ulcer disease is suboptimal: a systematic survey. Wound Repair Regen. 2017;25(5):892–900.
Gohari F, Baradaran HR, Tabatabaee M, Anijidani S, Mohammadpour Touserkani F, Atlasi R, Razmgir M. Quality of reporting randomized controlled trials (RCTs) in diabetes in Iran; a systematic review. J Diabetes Metab Disord. 2015;15(1):36.
Wang M, Jin Y, Hu ZJ, Thabane A, Dennis B, Gajic-Veljanoski O, Paul J, Thabane L. The reporting quality of abstracts of stepped wedge randomized trials is suboptimal: a systematic survey of the literature. Contemp Clin Trials Commun. 2017;8:1–10.
Shanthanna H, Kaushal A, Mbuagbaw L, Couban R, Busse J, Thabane L: A cross-sectional study of the reporting quality of pilot or feasibility trials in high-impact anesthesia journals Can J Anaesthesia 2018, 65(11):1180–1195.
Kosa SD, Mbuagbaw L, Borg Debono V, Bhandari M, Dennis BB, Ene G, Leenus A, Shi D, Thabane M, Valvasori S, et al. Agreement in reporting between trial publications and current clinical trial registry in high impact journals: a methodological review. Contemporary Clinical Trials. 2018;65:144–50.
Zhang Y, Florez ID, Colunga Lozano LE, Aloweni FAB, Kennedy SA, Li A, Craigie S, Zhang S, Agarwal A, Lopes LC, et al. A systematic survey on reporting and methods for handling missing participant data for continuous outcomes in randomized controlled trials. J Clin Epidemiol. 2017;88:57–66.
CAS PubMed Google Scholar
Hernández AV, Boersma E, Murray GD, Habbema JD, Steyerberg EW. Subgroup analyses in therapeutic cardiovascular clinical trials: are most of them misleading? Am Heart J. 2006;151(2):257–64.
Samaan Z, Mbuagbaw L, Kosa D, Borg Debono V, Dillenburg R, Zhang S, Fruci V, Dennis B, Bawor M, Thabane L. A systematic scoping review of adherence to reporting guidelines in health care literature. J Multidiscip Healthc. 2013;6:169–88.
Buscemi N, Hartling L, Vandermeer B, Tjosvold L, Klassen TP. Single data extraction generated more errors than double data extraction in systematic reviews. J Clin Epidemiol. 2006;59(7):697–703.
Carrasco-Labra A, Brignardello-Petersen R, Santesso N, Neumann I, Mustafa RA, Mbuagbaw L, Etxeandia Ikobaltzeta I, De Stio C, McCullagh LJ, Alonso-Coello P. Improving GRADE evidence tables part 1: a randomized trial shows improved understanding of content in summary-of-findings tables with a new format. J Clin Epidemiol. 2016;74:7–18.
The Northern Ireland Hub for Trials Methodology Research: SWAT/SWAR Information [ https://www.qub.ac.uk/sites/TheNorthernIrelandNetworkforTrialsMethodologyResearch/SWATSWARInformation/ ]. Accessed 31 Aug 2020.
Chick S, Sánchez P, Ferrin D, Morrice D. How to conduct a successful simulation study. In: Proceedings of the 2003 winter simulation conference: 2003; 2003. p. 66–70.
Google Scholar
Mulrow CD. The medical review article: state of the science. Ann Intern Med. 1987;106(3):485–8.
Sacks HS, Reitman D, Pagano D, Kupelnick B. Meta-analysis: an update. Mount Sinai J Med New York. 1996;63(3–4):216–24.
CAS Google Scholar
Areia M, Soares M, Dinis-Ribeiro M. Quality reporting of endoscopic diagnostic studies in gastrointestinal journals: where do we stand on the use of the STARD and CONSORT statements? Endoscopy. 2010;42(2):138–47.
Knol M, Groenwold R, Grobbee D. P-values in baseline tables of randomised controlled trials are inappropriate but still common in high impact journals. Eur J Prev Cardiol. 2012;19(2):231–2.
Chen M, Cui J, Zhang AL, Sze DM, Xue CC, May BH. Adherence to CONSORT items in randomized controlled trials of integrative medicine for colorectal Cancer published in Chinese journals. J Altern Complement Med. 2018;24(2):115–24.
Hopewell S, Ravaud P, Baron G, Boutron I. Effect of editors' implementation of CONSORT guidelines on the reporting of abstracts in high impact medical journals: interrupted time series analysis. BMJ. 2012;344:e4178.
The Cochrane Methodology Register Issue 2 2009 [ https://cmr.cochrane.org/help.htm ]. Accessed 31 Aug 2020.
Mbuagbaw L, Kredo T, Welch V, Mursleen S, Ross S, Zani B, Motaze NV, Quinlan L. Critical EPICOT items were absent in Cochrane human immunodeficiency virus systematic reviews: a bibliometric analysis. J Clin Epidemiol. 2016;74:66–72.
Barton S, Peckitt C, Sclafani F, Cunningham D, Chau I. The influence of industry sponsorship on the reporting of subgroup analyses within phase III randomised controlled trials in gastrointestinal oncology. Eur J Cancer. 2015;51(18):2732–9.
Setia MS. Methodology series module 5: sampling strategies. Indian J Dermatol. 2016;61(5):505–9.
Wilson B, Burnett P, Moher D, Altman DG, Al-Shahi Salman R. Completeness of reporting of randomised controlled trials including people with transient ischaemic attack or stroke: a systematic review. Eur Stroke J. 2018;3(4):337–46.
Kahale LA, Diab B, Brignardello-Petersen R, Agarwal A, Mustafa RA, Kwong J, Neumann I, Li L, Lopes LC, Briel M, et al. Systematic reviews do not adequately report or address missing outcome data in their analyses: a methodological survey. J Clin Epidemiol. 2018;99:14–23.
De Angelis CD, Drazen JM, Frizelle FA, Haug C, Hoey J, Horton R, Kotzin S, Laine C, Marusic A, Overbeke AJPM, et al. Is this clinical trial fully registered?: a statement from the International Committee of Medical Journal Editors*. Ann Intern Med. 2005;143(2):146–8.
Ohtake PJ, Childs JD. Why publish study protocols? Phys Ther. 2014;94(9):1208–9.
Rombey T, Allers K, Mathes T, Hoffmann F, Pieper D. A descriptive analysis of the characteristics and the peer review process of systematic review protocols published in an open peer review journal from 2012 to 2017. BMC Med Res Methodol. 2019;19(1):57.
Grimes DA, Schulz KF. Bias and causal associations in observational research. Lancet. 2002;359(9302):248–52.
Porta M (ed.): A dictionary of epidemiology, 5th edn. Oxford: Oxford University Press, Inc.; 2008.
El Dib R, Tikkinen KAO, Akl EA, Gomaa HA, Mustafa RA, Agarwal A, Carpenter CR, Zhang Y, Jorge EC, Almeida R, et al. Systematic survey of randomized trials evaluating the impact of alternative diagnostic strategies on patient-important outcomes. J Clin Epidemiol. 2017;84:61–9.
Helzer JE, Robins LN, Taibleson M, Woodruff RA Jr, Reich T, Wish ED. Reliability of psychiatric diagnosis. I. a methodological review. Arch Gen Psychiatry. 1977;34(2):129–33.
Chung ST, Chacko SK, Sunehag AL, Haymond MW. Measurements of gluconeogenesis and Glycogenolysis: a methodological review. Diabetes. 2015;64(12):3996–4010.
CAS PubMed PubMed Central Google Scholar
Sterne JA, Juni P, Schulz KF, Altman DG, Bartlett C, Egger M. Statistical methods for assessing the influence of study characteristics on treatment effects in 'meta-epidemiological' research. Stat Med. 2002;21(11):1513–24.
Moen EL, Fricano-Kugler CJ, Luikart BW, O’Malley AJ. Analyzing clustered data: why and how to account for multiple observations nested within a study participant? PLoS One. 2016;11(1):e0146721.
Zyzanski SJ, Flocke SA, Dickinson LM. On the nature and analysis of clustered data. Ann Fam Med. 2004;2(3):199–200.
Mathes T, Klassen P, Pieper D. Frequency of data extraction errors and methods to increase data extraction quality: a methodological review. BMC Med Res Methodol. 2017;17(1):152.
Bui DDA, Del Fiol G, Hurdle JF, Jonnalagadda S. Extractive text summarization system to aid data extraction from full text in systematic review development. J Biomed Inform. 2016;64:265–72.
Bui DD, Del Fiol G, Jonnalagadda S. PDF text classification to leverage information extraction from publication reports. J Biomed Inform. 2016;61:141–8.
Maticic K, Krnic Martinic M, Puljak L. Assessment of reporting quality of abstracts of systematic reviews with meta-analysis using PRISMA-A and discordance in assessments between raters without prior experience. BMC Med Res Methodol. 2019;19(1):32.
Speich B. Blinding in surgical randomized clinical trials in 2015. Ann Surg. 2017;266(1):21–2.
Abraha I, Cozzolino F, Orso M, Marchesi M, Germani A, Lombardo G, Eusebi P, De Florio R, Luchetta ML, Iorio A, et al. A systematic review found that deviations from intention-to-treat are common in randomized trials and systematic reviews. J Clin Epidemiol. 2017;84:37–46.
Zhong Y, Zhou W, Jiang H, Fan T, Diao X, Yang H, Min J, Wang G, Fu J, Mao B. Quality of reporting of two-group parallel randomized controlled clinical trials of multi-herb formulae: A survey of reports indexed in the Science Citation Index Expanded. Eur J Integrative Med. 2011;3(4):e309–16.
Farrokhyar F, Chu R, Whitlock R, Thabane L. A systematic review of the quality of publications reporting coronary artery bypass grafting trials. Can J Surg. 2007;50(4):266–77.
Oltean H, Gagnier JJ. Use of clustering analysis in randomized controlled trials in orthopaedic surgery. BMC Med Res Methodol. 2015;15:17.
Fleming PS, Koletsi D, Pandis N. Blinded by PRISMA: are systematic reviewers focusing on PRISMA and ignoring other guidelines? PLoS One. 2014;9(5):e96407.
Balasubramanian SP, Wiener M, Alshameeri Z, Tiruvoipati R, Elbourne D, Reed MW. Standards of reporting of randomized controlled trials in general surgery: can we do better? Ann Surg. 2006;244(5):663–7.
de Vries TW, van Roon EN. Low quality of reporting adverse drug reactions in paediatric randomised controlled trials. Arch Dis Child. 2010;95(12):1023–6.
Borg Debono V, Zhang S, Ye C, Paul J, Arya A, Hurlburt L, Murthy Y, Thabane L. The quality of reporting of RCTs used within a postoperative pain management meta-analysis, using the CONSORT statement. BMC Anesthesiol. 2012;12:13.
Kaiser KA, Cofield SS, Fontaine KR, Glasser SP, Thabane L, Chu R, Ambrale S, Dwary AD, Kumar A, Nayyar G, et al. Is funding source related to study reporting quality in obesity or nutrition randomized control trials in top-tier medical journals? Int J Obes. 2012;36(7):977–81.
Thomas O, Thabane L, Douketis J, Chu R, Westfall AO, Allison DB. Industry funding and the reporting quality of large long-term weight loss trials. Int J Obes. 2008;32(10):1531–6.
Khan NR, Saad H, Oravec CS, Rossi N, Nguyen V, Venable GT, Lillard JC, Patel P, Taylor DR, Vaughn BN, et al. A review of industry funding in randomized controlled trials published in the neurosurgical literature-the elephant in the room. Neurosurgery. 2018;83(5):890–7.
Hansen C, Lundh A, Rasmussen K, Hrobjartsson A. Financial conflicts of interest in systematic reviews: associations with results, conclusions, and methodological quality. Cochrane Database Syst Rev. 2019;8:Mr000047.
Kiehna EN, Starke RM, Pouratian N, Dumont AS. Standards for reporting randomized controlled trials in neurosurgery. J Neurosurg. 2011;114(2):280–5.
Liu LQ, Morris PJ, Pengel LH. Compliance to the CONSORT statement of randomized controlled trials in solid organ transplantation: a 3-year overview. Transpl Int. 2013;26(3):300–6.
Bala MM, Akl EA, Sun X, Bassler D, Mertz D, Mejza F, Vandvik PO, Malaga G, Johnston BC, Dahm P, et al. Randomized trials published in higher vs. lower impact journals differ in design, conduct, and analysis. J Clin Epidemiol. 2013;66(3):286–95.
Lee SY, Teoh PJ, Camm CF, Agha RA. Compliance of randomized controlled trials in trauma surgery with the CONSORT statement. J Trauma Acute Care Surg. 2013;75(4):562–72.
Ziogas DC, Zintzaras E. Analysis of the quality of reporting of randomized controlled trials in acute and chronic myeloid leukemia, and myelodysplastic syndromes as governed by the CONSORT statement. Ann Epidemiol. 2009;19(7):494–500.
Alvarez F, Meyer N, Gourraud PA, Paul C. CONSORT adoption and quality of reporting of randomized controlled trials: a systematic analysis in two dermatology journals. Br J Dermatol. 2009;161(5):1159–65.
Mbuagbaw L, Thabane M, Vanniyasingam T, Borg Debono V, Kosa S, Zhang S, Ye C, Parpia S, Dennis BB, Thabane L. Improvement in the quality of abstracts in major clinical journals since CONSORT extension for abstracts: a systematic review. Contemporary Clin trials. 2014;38(2):245–50.
Thabane L, Chu R, Cuddy K, Douketis J. What is the quality of reporting in weight loss intervention studies? A systematic review of randomized controlled trials. Int J Obes. 2007;31(10):1554–9.
Murad MH, Wang Z. Guidelines for reporting meta-epidemiological methodology research. Evidence Based Med. 2017;22(4):139.
METRIC - MEthodological sTudy ReportIng Checklist: guidelines for reporting methodological studies in health research [ http://www.equator-network.org/library/reporting-guidelines-under-development/reporting-guidelines-under-development-for-other-study-designs/#METRIC ]. Accessed 31 Aug 2020.
Jager KJ, Zoccali C, MacLeod A, Dekker FW. Confounding: what it is and how to deal with it. Kidney Int. 2008;73(3):256–60.
Parker SG, Halligan S, Erotocritou M, Wood CPJ, Boulton RW, Plumb AAO, Windsor ACJ, Mallett S. A systematic methodological review of non-randomised interventional studies of elective ventral hernia repair: clear definitions and a standardised minimum dataset are needed. Hernia. 2019.
Bouwmeester W, Zuithoff NPA, Mallett S, Geerlings MI, Vergouwe Y, Steyerberg EW, Altman DG, Moons KGM. Reporting and methods in clinical prediction research: a systematic review. PLoS Med. 2012;9(5):1–12.
Schiller P, Burchardi N, Niestroj M, Kieser M. Quality of reporting of clinical non-inferiority and equivalence randomised trials--update and extension. Trials. 2012;13:214.
Riado Minguez D, Kowalski M, Vallve Odena M, Longin Pontzen D, Jelicic Kadic A, Jeric M, Dosenovic S, Jakus D, Vrdoljak M, Poklepovic Pericic T, et al. Methodological and reporting quality of systematic reviews published in the highest ranking journals in the field of pain. Anesth Analg. 2017;125(4):1348–54.
Thabut G, Estellat C, Boutron I, Samama CM, Ravaud P. Methodological issues in trials assessing primary prophylaxis of venous thrombo-embolism. Eur Heart J. 2005;27(2):227–36.
Puljak L, Riva N, Parmelli E, González-Lorenzo M, Moja L, Pieper D. Data extraction methods: an analysis of internal reporting discrepancies in single manuscripts and practical advice. J Clin Epidemiol. 2020;117:158–64.
Ritchie A, Seubert L, Clifford R, Perry D, Bond C. Do randomised controlled trials relevant to pharmacy meet best practice standards for quality conduct and reporting? A systematic review. Int J Pharm Pract. 2019.
Babic A, Vuka I, Saric F, Proloscic I, Slapnicar E, Cavar J, Pericic TP, Pieper D, Puljak L. Overall bias methods and their use in sensitivity analysis of Cochrane reviews were not consistent. J Clin Epidemiol. 2019.
Tan A, Porcher R, Crequit P, Ravaud P, Dechartres A. Differences in treatment effect size between overall survival and progression-free survival in immunotherapy trials: a Meta-epidemiologic study of trials with results posted at ClinicalTrials.gov. J Clin Oncol. 2017;35(15):1686–94.
Croitoru D, Huang Y, Kurdina A, Chan AW, Drucker AM. Quality of reporting in systematic reviews published in dermatology journals. Br J Dermatol. 2020;182(6):1469–76.
Khan MS, Ochani RK, Shaikh A, Vaduganathan M, Khan SU, Fatima K, Yamani N, Mandrola J, Doukky R, Krasuski RA: Assessing the Quality of Reporting of Harms in Randomized Controlled Trials Published in High Impact Cardiovascular Journals. Eur Heart J Qual Care Clin Outcomes 2019.
Rosmarakis ES, Soteriades ES, Vergidis PI, Kasiakou SK, Falagas ME. From conference abstract to full paper: differences between data presented in conferences and journals. FASEB J. 2005;19(7):673–80.
Mueller M, D’Addario M, Egger M, Cevallos M, Dekkers O, Mugglin C, Scott P. Methods to systematically review and meta-analyse observational studies: a systematic scoping review of recommendations. BMC Med Res Methodol. 2018;18(1):44.
Li G, Abbade LPF, Nwosu I, Jin Y, Leenus A, Maaz M, Wang M, Bhatt M, Zielinski L, Sanger N, et al. A scoping review of comparisons between abstracts and full reports in primary biomedical research. BMC Med Res Methodol. 2017;17(1):181.
Krnic Martinic M, Pieper D, Glatt A, Puljak L. Definition of a systematic review used in overviews of systematic reviews, meta-epidemiological studies and textbooks. BMC Med Res Methodol. 2019;19(1):203.
Analytical study [ https://medical-dictionary.thefreedictionary.com/analytical+study ]. Accessed 31 Aug 2020.
Tricco AC, Tetzlaff J, Pham B, Brehaut J, Moher D. Non-Cochrane vs. Cochrane reviews were twice as likely to have positive conclusion statements: cross-sectional study. J Clin Epidemiol. 2009;62(4):380–6 e381.
Schalken N, Rietbergen C. The reporting quality of systematic reviews and Meta-analyses in industrial and organizational psychology: a systematic review. Front Psychol. 2017;8:1395.
Ranker LR, Petersen JM, Fox MP. Awareness of and potential for dependent error in the observational epidemiologic literature: A review. Ann Epidemiol. 2019;36:15–9 e12.
Paquette M, Alotaibi AM, Nieuwlaat R, Santesso N, Mbuagbaw L. A meta-epidemiological study of subgroup analyses in cochrane systematic reviews of atrial fibrillation. Syst Rev. 2019;8(1):241.
Download references
Acknowledgements
This work did not receive any dedicated funding.
Author information
Authors and affiliations.
Department of Health Research Methods, Evidence and Impact, McMaster University, Hamilton, ON, Canada
Lawrence Mbuagbaw, Daeria O. Lawson & Lehana Thabane
Biostatistics Unit/FSORC, 50 Charlton Avenue East, St Joseph’s Healthcare—Hamilton, 3rd Floor Martha Wing, Room H321, Hamilton, Ontario, L8N 4A6, Canada
Lawrence Mbuagbaw & Lehana Thabane
Centre for the Development of Best Practices in Health, Yaoundé, Cameroon
Lawrence Mbuagbaw
Center for Evidence-Based Medicine and Health Care, Catholic University of Croatia, Ilica 242, 10000, Zagreb, Croatia
Livia Puljak
Department of Epidemiology and Biostatistics, School of Public Health – Bloomington, Indiana University, Bloomington, IN, 47405, USA
David B. Allison
Departments of Paediatrics and Anaesthesia, McMaster University, Hamilton, ON, Canada
Lehana Thabane
Centre for Evaluation of Medicine, St. Joseph’s Healthcare-Hamilton, Hamilton, ON, Canada
Population Health Research Institute, Hamilton Health Sciences, Hamilton, ON, Canada
You can also search for this author in PubMed Google Scholar
Contributions
LM conceived the idea and drafted the outline and paper. DOL and LT commented on the idea and draft outline. LM, LP and DOL performed literature searches and data extraction. All authors (LM, DOL, LT, LP, DBA) reviewed several draft versions of the manuscript and approved the final manuscript.
Corresponding author
Correspondence to Lawrence Mbuagbaw .
Ethics declarations
Ethics approval and consent to participate.
Not applicable.
Consent for publication
Competing interests.
DOL, DBA, LM, LP and LT are involved in the development of a reporting guideline for methodological studies.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Mbuagbaw, L., Lawson, D.O., Puljak, L. et al. A tutorial on methodological studies: the what, when, how and why. BMC Med Res Methodol 20 , 226 (2020). https://doi.org/10.1186/s12874-020-01107-7
Download citation
Received : 27 May 2020
Accepted : 27 August 2020
Published : 07 September 2020
DOI : https://doi.org/10.1186/s12874-020-01107-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Methodological study
- Meta-epidemiology
- Research methods
- Research-on-research
BMC Medical Research Methodology
ISSN: 1471-2288
- General enquiries: [email protected]
Get science-backed answers as you write with Paperpal's Research feature
What is Research Methodology? Definition, Types, and Examples

Research methodology 1,2 is a structured and scientific approach used to collect, analyze, and interpret quantitative or qualitative data to answer research questions or test hypotheses. A research methodology is like a plan for carrying out research and helps keep researchers on track by limiting the scope of the research. Several aspects must be considered before selecting an appropriate research methodology, such as research limitations and ethical concerns that may affect your research.
The research methodology section in a scientific paper describes the different methodological choices made, such as the data collection and analysis methods, and why these choices were selected. The reasons should explain why the methods chosen are the most appropriate to answer the research question. A good research methodology also helps ensure the reliability and validity of the research findings. There are three types of research methodology—quantitative, qualitative, and mixed-method, which can be chosen based on the research objectives.
What is research methodology ?
A research methodology describes the techniques and procedures used to identify and analyze information regarding a specific research topic. It is a process by which researchers design their study so that they can achieve their objectives using the selected research instruments. It includes all the important aspects of research, including research design, data collection methods, data analysis methods, and the overall framework within which the research is conducted. While these points can help you understand what is research methodology, you also need to know why it is important to pick the right methodology.
Why is research methodology important?
Having a good research methodology in place has the following advantages: 3
- Helps other researchers who may want to replicate your research; the explanations will be of benefit to them.
- You can easily answer any questions about your research if they arise at a later stage.
- A research methodology provides a framework and guidelines for researchers to clearly define research questions, hypotheses, and objectives.
- It helps researchers identify the most appropriate research design, sampling technique, and data collection and analysis methods.
- A sound research methodology helps researchers ensure that their findings are valid and reliable and free from biases and errors.
- It also helps ensure that ethical guidelines are followed while conducting research.
- A good research methodology helps researchers in planning their research efficiently, by ensuring optimum usage of their time and resources.
Writing the methods section of a research paper? Let Paperpal help you achieve perfection
Types of research methodology.
There are three types of research methodology based on the type of research and the data required. 1
- Quantitative research methodology focuses on measuring and testing numerical data. This approach is good for reaching a large number of people in a short amount of time. This type of research helps in testing the causal relationships between variables, making predictions, and generalizing results to wider populations.
- Qualitative research methodology examines the opinions, behaviors, and experiences of people. It collects and analyzes words and textual data. This research methodology requires fewer participants but is still more time consuming because the time spent per participant is quite large. This method is used in exploratory research where the research problem being investigated is not clearly defined.
- Mixed-method research methodology uses the characteristics of both quantitative and qualitative research methodologies in the same study. This method allows researchers to validate their findings, verify if the results observed using both methods are complementary, and explain any unexpected results obtained from one method by using the other method.
What are the types of sampling designs in research methodology?
Sampling 4 is an important part of a research methodology and involves selecting a representative sample of the population to conduct the study, making statistical inferences about them, and estimating the characteristics of the whole population based on these inferences. There are two types of sampling designs in research methodology—probability and nonprobability.
- Probability sampling
In this type of sampling design, a sample is chosen from a larger population using some form of random selection, that is, every member of the population has an equal chance of being selected. The different types of probability sampling are:
- Systematic —sample members are chosen at regular intervals. It requires selecting a starting point for the sample and sample size determination that can be repeated at regular intervals. This type of sampling method has a predefined range; hence, it is the least time consuming.
- Stratified —researchers divide the population into smaller groups that don’t overlap but represent the entire population. While sampling, these groups can be organized, and then a sample can be drawn from each group separately.
- Cluster —the population is divided into clusters based on demographic parameters like age, sex, location, etc.
- Convenience —selects participants who are most easily accessible to researchers due to geographical proximity, availability at a particular time, etc.
- Purposive —participants are selected at the researcher’s discretion. Researchers consider the purpose of the study and the understanding of the target audience.
- Snowball —already selected participants use their social networks to refer the researcher to other potential participants.
- Quota —while designing the study, the researchers decide how many people with which characteristics to include as participants. The characteristics help in choosing people most likely to provide insights into the subject.
What are data collection methods?
During research, data are collected using various methods depending on the research methodology being followed and the research methods being undertaken. Both qualitative and quantitative research have different data collection methods, as listed below.
Qualitative research 5
- One-on-one interviews: Helps the interviewers understand a respondent’s subjective opinion and experience pertaining to a specific topic or event
- Document study/literature review/record keeping: Researchers’ review of already existing written materials such as archives, annual reports, research articles, guidelines, policy documents, etc.
- Focus groups: Constructive discussions that usually include a small sample of about 6-10 people and a moderator, to understand the participants’ opinion on a given topic.
- Qualitative observation : Researchers collect data using their five senses (sight, smell, touch, taste, and hearing).
Quantitative research 6
- Sampling: The most common type is probability sampling.
- Interviews: Commonly telephonic or done in-person.
- Observations: Structured observations are most commonly used in quantitative research. In this method, researchers make observations about specific behaviors of individuals in a structured setting.
- Document review: Reviewing existing research or documents to collect evidence for supporting the research.
- Surveys and questionnaires. Surveys can be administered both online and offline depending on the requirement and sample size.
Let Paperpal help you write the perfect research methods section. Start now!
What are data analysis methods.
The data collected using the various methods for qualitative and quantitative research need to be analyzed to generate meaningful conclusions. These data analysis methods 7 also differ between quantitative and qualitative research.
Quantitative research involves a deductive method for data analysis where hypotheses are developed at the beginning of the research and precise measurement is required. The methods include statistical analysis applications to analyze numerical data and are grouped into two categories—descriptive and inferential.
Descriptive analysis is used to describe the basic features of different types of data to present it in a way that ensures the patterns become meaningful. The different types of descriptive analysis methods are:
- Measures of frequency (count, percent, frequency)
- Measures of central tendency (mean, median, mode)
- Measures of dispersion or variation (range, variance, standard deviation)
- Measure of position (percentile ranks, quartile ranks)
Inferential analysis is used to make predictions about a larger population based on the analysis of the data collected from a smaller population. This analysis is used to study the relationships between different variables. Some commonly used inferential data analysis methods are:
- Correlation: To understand the relationship between two or more variables.
- Cross-tabulation: Analyze the relationship between multiple variables.
- Regression analysis: Study the impact of independent variables on the dependent variable.
- Frequency tables: To understand the frequency of data.
- Analysis of variance: To test the degree to which two or more variables differ in an experiment.
Qualitative research involves an inductive method for data analysis where hypotheses are developed after data collection. The methods include:
- Content analysis: For analyzing documented information from text and images by determining the presence of certain words or concepts in texts.
- Narrative analysis: For analyzing content obtained from sources such as interviews, field observations, and surveys. The stories and opinions shared by people are used to answer research questions.
- Discourse analysis: For analyzing interactions with people considering the social context, that is, the lifestyle and environment, under which the interaction occurs.
- Grounded theory: Involves hypothesis creation by data collection and analysis to explain why a phenomenon occurred.
- Thematic analysis: To identify important themes or patterns in data and use these to address an issue.
How to choose a research methodology?
Here are some important factors to consider when choosing a research methodology: 8
- Research objectives, aims, and questions —these would help structure the research design.
- Review existing literature to identify any gaps in knowledge.
- Check the statistical requirements —if data-driven or statistical results are needed then quantitative research is the best. If the research questions can be answered based on people’s opinions and perceptions, then qualitative research is most suitable.
- Sample size —sample size can often determine the feasibility of a research methodology. For a large sample, less effort- and time-intensive methods are appropriate.
- Constraints —constraints of time, geography, and resources can help define the appropriate methodology.
Got writer’s block? Kickstart your research paper writing with Paperpal now!
How to write a research methodology .
A research methodology should include the following components: 3,9
- Research design —should be selected based on the research question and the data required. Common research designs include experimental, quasi-experimental, correlational, descriptive, and exploratory.
- Research method —this can be quantitative, qualitative, or mixed-method.
- Reason for selecting a specific methodology —explain why this methodology is the most suitable to answer your research problem.
- Research instruments —explain the research instruments you plan to use, mainly referring to the data collection methods such as interviews, surveys, etc. Here as well, a reason should be mentioned for selecting the particular instrument.
- Sampling —this involves selecting a representative subset of the population being studied.
- Data collection —involves gathering data using several data collection methods, such as surveys, interviews, etc.
- Data analysis —describe the data analysis methods you will use once you’ve collected the data.
- Research limitations —mention any limitations you foresee while conducting your research.
- Validity and reliability —validity helps identify the accuracy and truthfulness of the findings; reliability refers to the consistency and stability of the results over time and across different conditions.
- Ethical considerations —research should be conducted ethically. The considerations include obtaining consent from participants, maintaining confidentiality, and addressing conflicts of interest.
Streamline Your Research Paper Writing Process with Paperpal
The methods section is a critical part of the research papers, allowing researchers to use this to understand your findings and replicate your work when pursuing their own research. However, it is usually also the most difficult section to write. This is where Paperpal can help you overcome the writer’s block and create the first draft in minutes with Paperpal Copilot, its secure generative AI feature suite.
With Paperpal you can get research advice, write and refine your work, rephrase and verify the writing, and ensure submission readiness, all in one place. Here’s how you can use Paperpal to develop the first draft of your methods section.
- Generate an outline: Input some details about your research to instantly generate an outline for your methods section
- Develop the section: Use the outline and suggested sentence templates to expand your ideas and develop the first draft.
- P araph ras e and trim : Get clear, concise academic text with paraphrasing that conveys your work effectively and word reduction to fix redundancies.
- Choose the right words: Enhance text by choosing contextual synonyms based on how the words have been used in previously published work.
- Check and verify text : Make sure the generated text showcases your methods correctly, has all the right citations, and is original and authentic. .
You can repeat this process to develop each section of your research manuscript, including the title, abstract and keywords. Ready to write your research papers faster, better, and without the stress? Sign up for Paperpal and start writing today!
Frequently Asked Questions
Q1. What are the key components of research methodology?
A1. A good research methodology has the following key components:
- Research design
- Data collection procedures
- Data analysis methods
- Ethical considerations
Q2. Why is ethical consideration important in research methodology?
A2. Ethical consideration is important in research methodology to ensure the readers of the reliability and validity of the study. Researchers must clearly mention the ethical norms and standards followed during the conduct of the research and also mention if the research has been cleared by any institutional board. The following 10 points are the important principles related to ethical considerations: 10
- Participants should not be subjected to harm.
- Respect for the dignity of participants should be prioritized.
- Full consent should be obtained from participants before the study.
- Participants’ privacy should be ensured.
- Confidentiality of the research data should be ensured.
- Anonymity of individuals and organizations participating in the research should be maintained.
- The aims and objectives of the research should not be exaggerated.
- Affiliations, sources of funding, and any possible conflicts of interest should be declared.
- Communication in relation to the research should be honest and transparent.
- Misleading information and biased representation of primary data findings should be avoided.
Q3. What is the difference between methodology and method?
A3. Research methodology is different from a research method, although both terms are often confused. Research methods are the tools used to gather data, while the research methodology provides a framework for how research is planned, conducted, and analyzed. The latter guides researchers in making decisions about the most appropriate methods for their research. Research methods refer to the specific techniques, procedures, and tools used by researchers to collect, analyze, and interpret data, for instance surveys, questionnaires, interviews, etc.
Research methodology is, thus, an integral part of a research study. It helps ensure that you stay on track to meet your research objectives and answer your research questions using the most appropriate data collection and analysis tools based on your research design.
Accelerate your research paper writing with Paperpal. Try for free now!
- Research methodologies. Pfeiffer Library website. Accessed August 15, 2023. https://library.tiffin.edu/researchmethodologies/whatareresearchmethodologies
- Types of research methodology. Eduvoice website. Accessed August 16, 2023. https://eduvoice.in/types-research-methodology/
- The basics of research methodology: A key to quality research. Voxco. Accessed August 16, 2023. https://www.voxco.com/blog/what-is-research-methodology/
- Sampling methods: Types with examples. QuestionPro website. Accessed August 16, 2023. https://www.questionpro.com/blog/types-of-sampling-for-social-research/
- What is qualitative research? Methods, types, approaches, examples. Researcher.Life blog. Accessed August 15, 2023. https://researcher.life/blog/article/what-is-qualitative-research-methods-types-examples/
- What is quantitative research? Definition, methods, types, and examples. Researcher.Life blog. Accessed August 15, 2023. https://researcher.life/blog/article/what-is-quantitative-research-types-and-examples/
- Data analysis in research: Types & methods. QuestionPro website. Accessed August 16, 2023. https://www.questionpro.com/blog/data-analysis-in-research/#Data_analysis_in_qualitative_research
- Factors to consider while choosing the right research methodology. PhD Monster website. Accessed August 17, 2023. https://www.phdmonster.com/factors-to-consider-while-choosing-the-right-research-methodology/
- What is research methodology? Research and writing guides. Accessed August 14, 2023. https://paperpile.com/g/what-is-research-methodology/
- Ethical considerations. Business research methodology website. Accessed August 17, 2023. https://research-methodology.net/research-methodology/ethical-considerations/
Paperpal is a comprehensive AI writing toolkit that helps students and researchers achieve 2x the writing in half the time. It leverages 21+ years of STM experience and insights from millions of research articles to provide in-depth academic writing, language editing, and submission readiness support to help you write better, faster.
Get accurate academic translations, rewriting support, grammar checks, vocabulary suggestions, and generative AI assistance that delivers human precision at machine speed. Try for free or upgrade to Paperpal Prime starting at US$19 a month to access premium features, including consistency, plagiarism, and 30+ submission readiness checks to help you succeed.
Experience the future of academic writing – Sign up to Paperpal and start writing for free!
Related Reads:
- Dangling Modifiers and How to Avoid Them in Your Writing
- Webinar: How to Use Generative AI Tools Ethically in Your Academic Writing
- Research Outlines: How to Write An Introduction Section in Minutes with Paperpal Copilot
- How to Paraphrase Research Papers Effectively
Language and Grammar Rules for Academic Writing
Climatic vs. climactic: difference and examples, you may also like, how to structure an essay, leveraging generative ai to enhance student understanding of..., how to write a good hook for essays,..., addressing peer review feedback and mastering manuscript revisions..., how paperpal can boost comprehension and foster interdisciplinary..., what is the importance of a concept paper..., how to write the first draft of a..., mla works cited page: format, template & examples, how to ace grant writing for research funding..., powerful academic phrases to improve your essay writing .
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Starting the research process
- Research Objectives | Definition & Examples
Research Objectives | Definition & Examples
Published on July 12, 2022 by Eoghan Ryan . Revised on November 20, 2023.
Research objectives describe what your research is trying to achieve and explain why you are pursuing it. They summarize the approach and purpose of your project and help to focus your research.
Your objectives should appear in the introduction of your research paper , at the end of your problem statement . They should:
- Establish the scope and depth of your project
- Contribute to your research design
- Indicate how your project will contribute to existing knowledge
Table of contents
What is a research objective, why are research objectives important, how to write research aims and objectives, smart research objectives, other interesting articles, frequently asked questions about research objectives.
Research objectives describe what your research project intends to accomplish. They should guide every step of the research process , including how you collect data , build your argument , and develop your conclusions .
Your research objectives may evolve slightly as your research progresses, but they should always line up with the research carried out and the actual content of your paper.
Research aims
A distinction is often made between research objectives and research aims.
A research aim typically refers to a broad statement indicating the general purpose of your research project. It should appear at the end of your problem statement, before your research objectives.
Your research objectives are more specific than your research aim and indicate the particular focus and approach of your project. Though you will only have one research aim, you will likely have several research objectives.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

Research objectives are important because they:
- Establish the scope and depth of your project: This helps you avoid unnecessary research. It also means that your research methods and conclusions can easily be evaluated .
- Contribute to your research design: When you know what your objectives are, you have a clearer idea of what methods are most appropriate for your research.
- Indicate how your project will contribute to extant research: They allow you to display your knowledge of up-to-date research, employ or build on current research methods, and attempt to contribute to recent debates.
Once you’ve established a research problem you want to address, you need to decide how you will address it. This is where your research aim and objectives come in.
Step 1: Decide on a general aim
Your research aim should reflect your research problem and should be relatively broad.
Step 2: Decide on specific objectives
Break down your aim into a limited number of steps that will help you resolve your research problem. What specific aspects of the problem do you want to examine or understand?
Step 3: Formulate your aims and objectives
Once you’ve established your research aim and objectives, you need to explain them clearly and concisely to the reader.
You’ll lay out your aims and objectives at the end of your problem statement, which appears in your introduction. Frame them as clear declarative statements, and use appropriate verbs to accurately characterize the work that you will carry out.
The acronym “SMART” is commonly used in relation to research objectives. It states that your objectives should be:
- Specific: Make sure your objectives aren’t overly vague. Your research needs to be clearly defined in order to get useful results.
- Measurable: Know how you’ll measure whether your objectives have been achieved.
- Achievable: Your objectives may be challenging, but they should be feasible. Make sure that relevant groundwork has been done on your topic or that relevant primary or secondary sources exist. Also ensure that you have access to relevant research facilities (labs, library resources , research databases , etc.).
- Relevant: Make sure that they directly address the research problem you want to work on and that they contribute to the current state of research in your field.
- Time-based: Set clear deadlines for objectives to ensure that the project stays on track.
Prevent plagiarism. Run a free check.
If you want to know more about the research process , methodology , research bias , or statistics , make sure to check out some of our other articles with explanations and examples.
Methodology
- Sampling methods
- Simple random sampling
- Stratified sampling
- Cluster sampling
- Likert scales
- Reproducibility
Statistics
- Null hypothesis
- Statistical power
- Probability distribution
- Effect size
- Poisson distribution
Research bias
- Optimism bias
- Cognitive bias
- Implicit bias
- Hawthorne effect
- Anchoring bias
- Explicit bias
Research objectives describe what you intend your research project to accomplish.
They summarize the approach and purpose of the project and help to focus your research.
Your objectives should appear in the introduction of your research paper , at the end of your problem statement .
Your research objectives indicate how you’ll try to address your research problem and should be specific:
Once you’ve decided on your research objectives , you need to explain them in your paper, at the end of your problem statement .
Keep your research objectives clear and concise, and use appropriate verbs to accurately convey the work that you will carry out for each one.
I will compare …
A research aim is a broad statement indicating the general purpose of your research project. It should appear in your introduction at the end of your problem statement , before your research objectives.
Research objectives are more specific than your research aim. They indicate the specific ways you’ll address the overarching aim.
Scope of research is determined at the beginning of your research process , prior to the data collection stage. Sometimes called “scope of study,” your scope delineates what will and will not be covered in your project. It helps you focus your work and your time, ensuring that you’ll be able to achieve your goals and outcomes.
Defining a scope can be very useful in any research project, from a research proposal to a thesis or dissertation . A scope is needed for all types of research: quantitative , qualitative , and mixed methods .
To define your scope of research, consider the following:
- Budget constraints or any specifics of grant funding
- Your proposed timeline and duration
- Specifics about your population of study, your proposed sample size , and the research methodology you’ll pursue
- Any inclusion and exclusion criteria
- Any anticipated control , extraneous , or confounding variables that could bias your research if not accounted for properly.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Ryan, E. (2023, November 20). Research Objectives | Definition & Examples. Scribbr. Retrieved June 24, 2024, from https://www.scribbr.com/research-process/research-objectives/
Is this article helpful?

Eoghan Ryan
Other students also liked, writing strong research questions | criteria & examples, how to write a problem statement | guide & examples, "i thought ai proofreading was useless but..".
I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes”
What Is Research Methodology? A Plain-Language Explanation & Definition (With Examples)
By Derek Jansen (MBA) and Kerryn Warren (PhD) | June 2020 (Last updated April 2023)
If you’re new to formal academic research, it’s quite likely that you’re feeling a little overwhelmed by all the technical lingo that gets thrown around. And who could blame you – “research methodology”, “research methods”, “sampling strategies”… it all seems never-ending!
In this post, we’ll demystify the landscape with plain-language explanations and loads of examples (including easy-to-follow videos), so that you can approach your dissertation, thesis or research project with confidence. Let’s get started.
Research Methodology 101
- What exactly research methodology means
- What qualitative , quantitative and mixed methods are
- What sampling strategy is
- What data collection methods are
- What data analysis methods are
- How to choose your research methodology
- Example of a research methodology

What is research methodology?
Research methodology simply refers to the practical “how” of a research study. More specifically, it’s about how a researcher systematically designs a study to ensure valid and reliable results that address the research aims, objectives and research questions . Specifically, how the researcher went about deciding:
- What type of data to collect (e.g., qualitative or quantitative data )
- Who to collect it from (i.e., the sampling strategy )
- How to collect it (i.e., the data collection method )
- How to analyse it (i.e., the data analysis methods )
Within any formal piece of academic research (be it a dissertation, thesis or journal article), you’ll find a research methodology chapter or section which covers the aspects mentioned above. Importantly, a good methodology chapter explains not just what methodological choices were made, but also explains why they were made. In other words, the methodology chapter should justify the design choices, by showing that the chosen methods and techniques are the best fit for the research aims, objectives and research questions.
So, it’s the same as research design?
Not quite. As we mentioned, research methodology refers to the collection of practical decisions regarding what data you’ll collect, from who, how you’ll collect it and how you’ll analyse it. Research design, on the other hand, is more about the overall strategy you’ll adopt in your study. For example, whether you’ll use an experimental design in which you manipulate one variable while controlling others. You can learn more about research design and the various design types here .
Need a helping hand?
What are qualitative, quantitative and mixed-methods?
Qualitative, quantitative and mixed-methods are different types of methodological approaches, distinguished by their focus on words , numbers or both . This is a bit of an oversimplification, but its a good starting point for understanding.
Let’s take a closer look.
Qualitative research refers to research which focuses on collecting and analysing words (written or spoken) and textual or visual data, whereas quantitative research focuses on measurement and testing using numerical data . Qualitative analysis can also focus on other “softer” data points, such as body language or visual elements.
It’s quite common for a qualitative methodology to be used when the research aims and research questions are exploratory in nature. For example, a qualitative methodology might be used to understand peoples’ perceptions about an event that took place, or a political candidate running for president.
Contrasted to this, a quantitative methodology is typically used when the research aims and research questions are confirmatory in nature. For example, a quantitative methodology might be used to measure the relationship between two variables (e.g. personality type and likelihood to commit a crime) or to test a set of hypotheses .
As you’ve probably guessed, the mixed-method methodology attempts to combine the best of both qualitative and quantitative methodologies to integrate perspectives and create a rich picture. If you’d like to learn more about these three methodological approaches, be sure to watch our explainer video below.
What is sampling strategy?
Simply put, sampling is about deciding who (or where) you’re going to collect your data from . Why does this matter? Well, generally it’s not possible to collect data from every single person in your group of interest (this is called the “population”), so you’ll need to engage a smaller portion of that group that’s accessible and manageable (this is called the “sample”).
How you go about selecting the sample (i.e., your sampling strategy) will have a major impact on your study. There are many different sampling methods you can choose from, but the two overarching categories are probability sampling and non-probability sampling .
Probability sampling involves using a completely random sample from the group of people you’re interested in. This is comparable to throwing the names all potential participants into a hat, shaking it up, and picking out the “winners”. By using a completely random sample, you’ll minimise the risk of selection bias and the results of your study will be more generalisable to the entire population.
Non-probability sampling , on the other hand, doesn’t use a random sample . For example, it might involve using a convenience sample, which means you’d only interview or survey people that you have access to (perhaps your friends, family or work colleagues), rather than a truly random sample. With non-probability sampling, the results are typically not generalisable .
To learn more about sampling methods, be sure to check out the video below.
What are data collection methods?
As the name suggests, data collection methods simply refers to the way in which you go about collecting the data for your study. Some of the most common data collection methods include:
- Interviews (which can be unstructured, semi-structured or structured)
- Focus groups and group interviews
- Surveys (online or physical surveys)
- Observations (watching and recording activities)
- Biophysical measurements (e.g., blood pressure, heart rate, etc.)
- Documents and records (e.g., financial reports, court records, etc.)
The choice of which data collection method to use depends on your overall research aims and research questions , as well as practicalities and resource constraints. For example, if your research is exploratory in nature, qualitative methods such as interviews and focus groups would likely be a good fit. Conversely, if your research aims to measure specific variables or test hypotheses, large-scale surveys that produce large volumes of numerical data would likely be a better fit.
What are data analysis methods?
Data analysis methods refer to the methods and techniques that you’ll use to make sense of your data. These can be grouped according to whether the research is qualitative (words-based) or quantitative (numbers-based).
Popular data analysis methods in qualitative research include:
- Qualitative content analysis
- Thematic analysis
- Discourse analysis
- Narrative analysis
- Interpretative phenomenological analysis (IPA)
- Visual analysis (of photographs, videos, art, etc.)
Qualitative data analysis all begins with data coding , after which an analysis method is applied. In some cases, more than one analysis method is used, depending on the research aims and research questions . In the video below, we explore some common qualitative analysis methods, along with practical examples.
Moving on to the quantitative side of things, popular data analysis methods in this type of research include:
- Descriptive statistics (e.g. means, medians, modes )
- Inferential statistics (e.g. correlation, regression, structural equation modelling)
Again, the choice of which data collection method to use depends on your overall research aims and objectives , as well as practicalities and resource constraints. In the video below, we explain some core concepts central to quantitative analysis.
How do I choose a research methodology?
As you’ve probably picked up by now, your research aims and objectives have a major influence on the research methodology . So, the starting point for developing your research methodology is to take a step back and look at the big picture of your research, before you make methodology decisions. The first question you need to ask yourself is whether your research is exploratory or confirmatory in nature.
If your research aims and objectives are primarily exploratory in nature, your research will likely be qualitative and therefore you might consider qualitative data collection methods (e.g. interviews) and analysis methods (e.g. qualitative content analysis).
Conversely, if your research aims and objective are looking to measure or test something (i.e. they’re confirmatory), then your research will quite likely be quantitative in nature, and you might consider quantitative data collection methods (e.g. surveys) and analyses (e.g. statistical analysis).
Designing your research and working out your methodology is a large topic, which we cover extensively on the blog . For now, however, the key takeaway is that you should always start with your research aims, objectives and research questions (the golden thread). Every methodological choice you make needs align with those three components.
Example of a research methodology chapter
In the video below, we provide a detailed walkthrough of a research methodology from an actual dissertation, as well as an overview of our free methodology template .

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:
")
199 Comments

Thank you for this simple yet comprehensive and easy to digest presentation. God Bless!

You’re most welcome, Leo. Best of luck with your research!

I found it very useful. many thanks

This is really directional. A make-easy research knowledge.

Thank you for this, I think will help my research proposal

Thanks for good interpretation,well understood.

Good morning sorry I want to the search topic

Thank u more

Thank you, your explanation is simple and very helpful.

Very educative a.nd exciting platform. A bigger thank you and I’ll like to always be with you

That’s the best analysis

So simple yet so insightful. Thank you.

This really easy to read as it is self-explanatory. Very much appreciated…

Thanks for this. It’s so helpful and explicit. For those elements highlighted in orange, they were good sources of referrals for concepts I didn’t understand. A million thanks for this.

Good morning, I have been reading your research lessons through out a period of times. They are important, impressive and clear. Want to subscribe and be and be active with you.

Thankyou So much Sir Derek…
Good morning thanks so much for the on line lectures am a student of university of Makeni.select a research topic and deliberate on it so that we’ll continue to understand more.sorry that’s a suggestion.

Beautiful presentation. I love it.

please provide a research mehodology example for zoology

It’s very educative and well explained

Thanks for the concise and informative data.

This is really good for students to be safe and well understand that research is all about

Thank you so much Derek sir🖤🙏🤗

Very simple and reliable

This is really helpful. Thanks alot. God bless you.

very useful, Thank you very much..

thanks a lot its really useful

in a nutshell..thank you!

Thanks for updating my understanding on this aspect of my Thesis writing.

thank you so much my through this video am competently going to do a good job my thesis

Thanks a lot. Very simple to understand. I appreciate 🙏

Very simple but yet insightful Thank you

This has been an eye opening experience. Thank you grad coach team.

Very useful message for research scholars

Really very helpful thank you

yes you are right and i’m left

Research methodology with a simplest way i have never seen before this article.

wow thank u so much
Good morning thanks so much for the on line lectures am a student of university of Makeni.select a research topic and deliberate on is so that we will continue to understand more.sorry that’s a suggestion.

Very precise and informative.

Thanks for simplifying these terms for us, really appreciate it.

Thanks this has really helped me. It is very easy to understand.

I found the notes and the presentation assisting and opening my understanding on research methodology

Good presentation

Im so glad you clarified my misconceptions. Im now ready to fry my onions. Thank you so much. God bless

Thank you a lot.

thanks for the easy way of learning and desirable presentation.

Thanks a lot. I am inspired

Well written

I am writing a APA Format paper . I using questionnaire with 120 STDs teacher for my participant. Can you write me mthology for this research. Send it through email sent. Just need a sample as an example please. My topic is ” impacts of overcrowding on students learning
Thanks for your comment.
We can’t write your methodology for you. If you’re looking for samples, you should be able to find some sample methodologies on Google. Alternatively, you can download some previous dissertations from a dissertation directory and have a look at the methodology chapters therein.
All the best with your research.

Thank you so much for this!! God Bless

Thank you. Explicit explanation

Thank you, Derek and Kerryn, for making this simple to understand. I’m currently at the inception stage of my research.

Thnks a lot , this was very usefull on my assignment

excellent explanation

I’m currently working on my master’s thesis, thanks for this! I’m certain that I will use Qualitative methodology.

Thanks a lot for this concise piece, it was quite relieving and helpful. God bless you BIG…

I am currently doing my dissertation proposal and I am sure that I will do quantitative research. Thank you very much it was extremely helpful.

Very interesting and informative yet I would like to know about examples of Research Questions as well, if possible.

I’m about to submit a research presentation, I have come to understand from your simplification on understanding research methodology. My research will be mixed methodology, qualitative as well as quantitative. So aim and objective of mixed method would be both exploratory and confirmatory. Thanks you very much for your guidance.

OMG thanks for that, you’re a life saver. You covered all the points I needed. Thank you so much ❤️ ❤️ ❤️

Thank you immensely for this simple, easy to comprehend explanation of data collection methods. I have been stuck here for months 😩. Glad I found your piece. Super insightful.

I’m going to write synopsis which will be quantitative research method and I don’t know how to frame my topic, can I kindly get some ideas..

Thanks for this, I was really struggling.
This was really informative I was struggling but this helped me.

Thanks a lot for this information, simple and straightforward. I’m a last year student from the University of South Africa UNISA South Africa.

its very much informative and understandable. I have enlightened.

An interesting nice exploration of a topic.

Thank you. Accurate and simple🥰

This article was really helpful, it helped me understanding the basic concepts of the topic Research Methodology. The examples were very clear, and easy to understand. I would like to visit this website again. Thank you so much for such a great explanation of the subject.

Thanks dude

Thank you Doctor Derek for this wonderful piece, please help to provide your details for reference purpose. God bless.

Many compliments to you

Great work , thank you very much for the simple explanation

Thank you. I had to give a presentation on this topic. I have looked everywhere on the internet but this is the best and simple explanation.

thank you, its very informative.

Well explained. Now I know my research methodology will be qualitative and exploratory. Thank you so much, keep up the good work

Well explained, thank you very much.

This is good explanation, I have understood the different methods of research. Thanks a lot.

Great work…very well explanation

Thanks Derek. Kerryn was just fantastic!
Great to hear that, Hyacinth. Best of luck with your research!

Its a good templates very attractive and important to PhD students and lectuter
Thanks for the feedback, Matobela. Good luck with your research methodology.

Thank you. This is really helpful.
You’re very welcome, Elie. Good luck with your research methodology.

Well explained thanks

This is a very helpful site especially for young researchers at college. It provides sufficient information to guide students and equip them with the necessary foundation to ask any other questions aimed at deepening their understanding.
Thanks for the kind words, Edward. Good luck with your research!

Thank you. I have learned a lot.
Great to hear that, Ngwisa. Good luck with your research methodology!

Thank you for keeping your presentation simples and short and covering key information for research methodology. My key takeaway: Start with defining your research objective the other will depend on the aims of your research question.

My name is Zanele I would like to be assisted with my research , and the topic is shortage of nursing staff globally want are the causes , effects on health, patients and community and also globally

Thanks for making it simple and clear. It greatly helped in understanding research methodology. Regards.

This is well simplified and straight to the point

Thank you Dr

I was given an assignment to research 2 publications and describe their research methodology? I don’t know how to start this task can someone help me?
Sure. You’re welcome to book an initial consultation with one of our Research Coaches to discuss how we can assist – https://gradcoach.com/book/new/ .

Thanks a lot I am relieved of a heavy burden.keep up with the good work

I’m very much grateful Dr Derek. I’m planning to pursue one of the careers that really needs one to be very much eager to know. There’s a lot of research to do and everything, but since I’ve gotten this information I will use it to the best of my potential.

Thank you so much, words are not enough to explain how helpful this session has been for me!

Thanks this has thought me alot.

Very concise and helpful. Thanks a lot

Thank Derek. This is very helpful. Your step by step explanation has made it easier for me to understand different concepts. Now i can get on with my research.

I wish i had come across this sooner. So simple but yet insightful

really nice explanation thank you so much

I’m so grateful finding this site, it’s really helpful…….every term well explained and provide accurate understanding especially to student going into an in-depth research for the very first time, even though my lecturer already explained this topic to the class, I think I got the clear and efficient explanation here, much thanks to the author.

It is very helpful material

I would like to be assisted with my research topic : Literature Review and research methodologies. My topic is : what is the relationship between unemployment and economic growth?

Its really nice and good for us.

THANKS SO MUCH FOR EXPLANATION, ITS VERY CLEAR TO ME WHAT I WILL BE DOING FROM NOW .GREAT READS.

Short but sweet.Thank you

Informative article. Thanks for your detailed information.

I’m currently working on my Ph.D. thesis. Thanks a lot, Derek and Kerryn, Well-organized sequences, facilitate the readers’ following.

great article for someone who does not have any background can even understand

I am a bit confused about research design and methodology. Are they the same? If not, what are the differences and how are they related?
Thanks in advance.

concise and informative.

Thank you very much

How can we site this article is Harvard style?

Very well written piece that afforded better understanding of the concept. Thank you!

Am a new researcher trying to learn how best to write a research proposal. I find your article spot on and want to download the free template but finding difficulties. Can u kindly send it to my email, the free download entitled, “Free Download: Research Proposal Template (with Examples)”.

Thank too much

Thank you very much for your comprehensive explanation about research methodology so I like to thank you again for giving us such great things.

Good very well explained.Thanks for sharing it.

Thank u sir, it is really a good guideline.

so helpful thank you very much.

Thanks for the video it was very explanatory and detailed, easy to comprehend and follow up. please, keep it up the good work

It was very helpful, a well-written document with precise information.

how do i reference this?

MLA Jansen, Derek, and Kerryn Warren. “What (Exactly) Is Research Methodology?” Grad Coach, June 2021, gradcoach.com/what-is-research-methodology/.
APA Jansen, D., & Warren, K. (2021, June). What (Exactly) Is Research Methodology? Grad Coach. https://gradcoach.com/what-is-research-methodology/

Your explanation is easily understood. Thank you

Very help article. Now I can go my methodology chapter in my thesis with ease

I feel guided ,Thank you

This simplification is very helpful. It is simple but very educative, thanks ever so much

The write up is informative and educative. It is an academic intellectual representation that every good researcher can find useful. Thanks

Wow, this is wonderful long live.

Nice initiative

thank you the video was helpful to me.

Thank you very much for your simple and clear explanations I’m really satisfied by the way you did it By now, I think I can realize a very good article by following your fastidious indications May God bless you

Thanks very much, it was very concise and informational for a beginner like me to gain an insight into what i am about to undertake. I really appreciate.

very informative sir, it is amazing to understand the meaning of question hidden behind that, and simple language is used other than legislature to understand easily. stay happy.

This one is really amazing. All content in your youtube channel is a very helpful guide for doing research. Thanks, GradCoach.

research methodologies

Please send me more information concerning dissertation research.

Nice piece of knowledge shared….. #Thump_UP

This is amazing, it has said it all. Thanks to Gradcoach

This is wonderful,very elaborate and clear.I hope to reach out for your assistance in my research very soon.

This is the answer I am searching about…
realy thanks a lot

Thank you very much for this awesome, to the point and inclusive article.

Thank you very much I need validity and reliability explanation I have exams

Thank you for a well explained piece. This will help me going forward.

Very simple and well detailed Many thanks

This is so very simple yet so very effective and comprehensive. An Excellent piece of work.

I wish I saw this earlier on! Great insights for a beginner(researcher) like me. Thanks a mil!

Thank you very much, for such a simplified, clear and practical step by step both for academic students and general research work. Holistic, effective to use and easy to read step by step. One can easily apply the steps in practical terms and produce a quality document/up-to standard
Thanks for simplifying these terms for us, really appreciated.

Thanks for a great work. well understood .

This was very helpful. It was simple but profound and very easy to understand. Thank you so much!

Great and amazing research guidelines. Best site for learning research

hello sir/ma’am, i didn’t find yet that what type of research methodology i am using. because i am writing my report on CSR and collect all my data from websites and articles so which type of methodology i should write in dissertation report. please help me. i am from India.

how does this really work?

perfect content, thanks a lot

As a researcher, I commend you for the detailed and simplified information on the topic in question. I would like to remain in touch for the sharing of research ideas on other topics. Thank you

Impressive. Thank you, Grad Coach 😍
Thank you Grad Coach for this piece of information. I have at least learned about the different types of research methodologies.

Very useful content with easy way

Thank you very much for the presentation. I am an MPH student with the Adventist University of Africa. I have successfully completed my theory and starting on my research this July. My topic is “Factors associated with Dental Caries in (one District) in Botswana. I need help on how to go about this quantitative research

I am so grateful to run across something that was sooo helpful. I have been on my doctorate journey for quite some time. Your breakdown on methodology helped me to refresh my intent. Thank you.

thanks so much for this good lecture. student from university of science and technology, Wudil. Kano Nigeria.

It’s profound easy to understand I appreciate

Thanks a lot for sharing superb information in a detailed but concise manner. It was really helpful and helped a lot in getting into my own research methodology.

Comment * thanks very much

This was sooo helpful for me thank you so much i didn’t even know what i had to write thank you!
You’re most welcome 🙂

Simple and good. Very much helpful. Thank you so much.

This is very good work. I have benefited.

Thank you so much for sharing

This is powerful thank you so much guys
I am nkasa lizwi doing my research proposal on honors with the university of Walter Sisulu Komani I m on part 3 now can you assist me.my topic is: transitional challenges faced by educators in intermediate phase in the Alfred Nzo District.

Appreciate the presentation. Very useful step-by-step guidelines to follow.

I appreciate sir

wow! This is super insightful for me. Thank you!

Indeed this material is very helpful! Kudos writers/authors.

I want to say thank you very much, I got a lot of info and knowledge. Be blessed.

I want present a seminar paper on Optimisation of Deep learning-based models on vulnerability detection in digital transactions.
Need assistance

Dear Sir, I want to be assisted on my research on Sanitation and Water management in emergencies areas.

I am deeply grateful for the knowledge gained. I will be getting in touch shortly as I want to be assisted in my ongoing research.

The information shared is informative, crisp and clear. Kudos Team! And thanks a lot!

hello i want to study

Hello!! Grad coach teams. I am extremely happy in your tutorial or consultation. i am really benefited all material and briefing. Thank you very much for your generous helps. Please keep it up. If you add in your briefing, references for further reading, it will be very nice.

All I have to say is, thank u gyz.

Good, l thanks

thank you, it is very useful
Trackbacks/Pingbacks
- What Is A Literature Review (In A Dissertation Or Thesis) - Grad Coach - […] the literature review is to inform the choice of methodology for your own research. As we’ve discussed on the Grad Coach blog,…
- Free Download: Research Proposal Template (With Examples) - Grad Coach - […] Research design (methodology) […]
- Dissertation vs Thesis: What's the difference? - Grad Coach - […] and thesis writing on a daily basis – everything from how to find a good research topic to which…
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Implement Sci
Scoping studies: advancing the methodology
Danielle levac.
1 School of Rehabilitation Science, McMaster University, 1400 Main Street West, Room 403, Hamilton, Ontario, Canada
Heather Colquhoun
Kelly k o'brien.
2 Department of Physical Therapy, University of Toronto, 160-500 University Avenue, Toronto, Ontario, Canada
Scoping studies are an increasingly popular approach to reviewing health research evidence. In 2005, Arksey and O'Malley published the first methodological framework for conducting scoping studies. While this framework provides an excellent foundation for scoping study methodology, further clarifying and enhancing this framework will help support the consistency with which authors undertake and report scoping studies and may encourage researchers and clinicians to engage in this process.
We build upon our experiences conducting three scoping studies using the Arksey and O'Malley methodology to propose recommendations that clarify and enhance each stage of the framework. Recommendations include: clarifying and linking the purpose and research question (stage one); balancing feasibility with breadth and comprehensiveness of the scoping process (stage two); using an iterative team approach to selecting studies (stage three) and extracting data (stage four); incorporating a numerical summary and qualitative thematic analysis, reporting results, and considering the implications of study findings to policy, practice, or research (stage five); and incorporating consultation with stakeholders as a required knowledge translation component of scoping study methodology (stage six). Lastly, we propose additional considerations for scoping study methodology in order to support the advancement, application and relevance of scoping studies in health research.
Specific recommendations to clarify and enhance this methodology are outlined for each stage of the Arksey and O'Malley framework. Continued debate and development about scoping study methodology will help to maximize the usefulness and rigor of scoping study findings within healthcare research and practice.
Scoping studies (or scoping reviews) represent an increasingly popular approach to reviewing health research evidence [ 1 ]. However, no universal scoping study definition or purpose exists (Table (Table1) 1 ) [ 1 , 2 ]. Definitions commonly refer to 'mapping,' a process of summarizing a range of evidence in order to convey the breadth and depth of a field. Scoping studies differ from systematic reviews because authors do not typically assess the quality of included studies [ 3 - 5 ]. Scoping studies also differ from narrative or literature reviews in that the scoping process requires analytical reinterpretation of the literature [ 1 ].
Definitions and purposes of scoping studies
| Authors | Definition | Purpose(s) |
|---|---|---|
| (2002) | None provided. | 'The purpose of a scoping exercise is both to map a wide range of literature, and to envisage where gaps and innovative approaches may lie"' [[ ] p. 28]. |
| 'Aim to map rapidly the key concepts underpinning a research area and the main sources and types of evidence available' [[ ] p. 194], as cited in [ ] | 1. To examine the extent, range, and nature of research activity. 2. To determine the value for undertaking a full systematic review. 3. To summarize and disseminate research findings. 4. To identify research gaps in the existing literature. [[ ] p. 21] | |
| (2008) | 'Scoping studies are concerned with contextualizing knowledge in terms of identifying the current state of understanding; identifying the sorts of things we know and do not know; and then setting this within policy and practice contexts' [ ] | 1. Literature mapping: 'is a map of the relevant literature. These vary in scope from general accounts of the literature to studies that are just short of systematic reviews. Literature scoping studies often also involve the syntheses of findings from different types of study.' 2. Conceptual mapping: 'a scoping study designed to establish how a particular term is used in what literature, by whom and for what purpose.' 3. Policy mapping: 'a scoping study designed to identify the main documents and statements from government agencies and professional bodies that have a bearing on the nature of practice in that area.'' 4. Stakeholder consultation: 'Do[es] not constitute scoping studies in their own right, but they do have an important part to play in scoping studies concerned with the identification of research priorities, in helping to target research questions, and in validating the outcomes of scoping studies through peer-review' [ ]. |
| (2009) | 'Preliminary assessment of potential size and scope of research literature.' [[ ] p.95] | 'Aims to identify the nature and extent of research evidence (usually including ongoing research' [[ ] p.95]. |
| (2009) | 'Scoping involves the synthesis and analysis of a wide range of research and non-research material to provide greater conceptual clarity about a specific topic or field of evidence' [[ ] p.1386]. | 'We propose that a common synthesising construct emerges to explain the purpose of scoping, namely that of 'reconnaissance'. It is generally synonymous with a preliminarily investigation in which information is systematically gathered and examined in order to establish strengths and weakness and guide in which ever context, future decision-making' [[ ] p. 1396]. |
| | None provided. | 1.'Clarification of working definitions and conceptual boundaries of a topic area, developed in the form of systematic overview (narrative review) of the literature but specifically excluding a systematic review, to determine a frame of reference; 2. Outline what is already known and identify gaps in existing research, and; 4. Conceptual analysis may include the 'mapping' of existing empirical evidence to describe and interpret issues that will inform further research and development opportunities.' [[ ] p. 1387] |
| | 'Scoping reviews are exploratory projects that systematically map the literature available on a topic, identifying the key concepts, theories, sources of evidence, and gaps in the research. They are often preliminary to full syntheses, undertaken when feasibility is a concern -- either because the potentially relevant literature is thought to be especially vast and diverse (varying by method, theoretical orientation or discipline) or there is suspicion that not enough literature exists. These entail the systematic selection, collection and summarization of existing knowledge in a broad thematic area for the purpose of identifying where there is sufficient evidence to conduct a full synthesis or where insufficient evidence exists and further primary research is necessary.' [ ] | None provided. |
Researchers can undertake a scoping study to examine the extent, range, and nature of research activity, determine the value of undertaking a full systematic review, summarize and disseminate research findings, or identify gaps in the existing literature [ 6 ]. As such, researchers can use scoping studies to clarify a complex concept and refine subsequent research inquiries [ 1 ]. Scoping studies may be particularly relevant to disciplines with emerging evidence, such as rehabilitation science, in which the paucity of randomized controlled trials makes it difficult for researchers to undertake systematic reviews. In these situations, scoping studies are ideal because researchers can incorporate a range of study designs in both published and grey literature, address questions beyond those related to intervention effectiveness, and generate findings that can complement the findings of clinical trials.
In an effort to provide guidance to authors undertaking scoping studies, Arksey and O'Malley [ 6 ] developed a six-stage methodological framework: identifying the research question, searching for relevant studies, selecting studies, charting the data, collating, summarizing, and reporting the results, and consulting with stakeholders to inform or validate study findings (Table (Table2). 2 ). While this framework provided an excellent methodological foundation, published scoping studies continue to lack sufficient methodological description or detail about the data analysis process, making it challenging for readers to understand how study findings were determined [ 1 ]. Arksey and O'Malley [ 6 ] encouraged other authors to refine their framework in order to enhance the methodology.
Overview of the Arksey and O'Malley methodological framework for conducting a scoping study
| Arksey and O'Malley Framework Stage | Description |
|---|---|
| 1: Identifying the research question | Identifying the research question provides the roadmap for subsequent stages. Relevant aspects of the question must be clearly defined as they have ramifications for search strategies. Research questions are broad in nature as they seek to provide breadth of coverage. |
| 2: Identifying relevant studies | This stage involves identifying the relevant studies and developing a decision plan for where to search, which terms to use, which sources are to be searched, time span, and language. Comprehensiveness and breadth is important in the search. Sources include electronic databases, reference lists, hand searching of key journals, and organizations and conferences. Breadth is important; however, practicalities of the search are as well. Time, budget and personnel resources are potential limiting factors and decisions need to be made upfront about how these will impact the search. |
| 3: Study selection | Study selection involves inclusion and exclusion criteria. These criteria are based on the specifics of the research question and on new familiarity with the subject matter through reading the studies. |
| 4: Charting the data | A data-charting form is developed and used to extract data from each study. A 'narrative review' or 'descriptive analytical' method is used to extract contextual or process oriented information from each study. |
| 5: Collating, summarizing, and reporting results | An analytic framework or thematic construction is used to provide an overview of the breadth of the literature but not a synthesis. A numerical analysis of the extent and nature of studies using tables and charts is presented. A thematic analysis is then presented. Clarity and consistency are required when reporting results. |
| 6: Consultation (optional) | Provides opportunities for consumer and stakeholder involvement to suggest additional references and provide insights beyond those in the literature. |
In this paper, we apply our experiences using the Arksey and O'Malley framework to build on the existing methodological framework. Specifically, we propose recommendations for each stage of the framework, followed by considerations for the advancement, application, and relevance of scoping studies in health research. Continual refinement of the framework stages may provide greater clarity about scoping study methodology, encourage researchers and clinicians to engage in this process, and help to enhance the methodological rigor with which authors undertake and report scoping studies [ 1 ].
We each completed a scoping study in separate areas of rehabilitation using the Arksey and O'Malley framework [ 6 ]. Goals of these studies included: identifying research priorities within HIV and rehabilitation [ 7 ], applying motor learning strategies within pediatric physical and occupational therapy intervention approaches [ 8 ], and exploring the use of theory within studies of knowledge translation [ 9 ]. The amount of literature reviewed in our studies ranged from 31 (DL) to 146 (KO) publications. Upon discovering that we had similar challenges implementing the scoping study methodology, we decided to use our experiences to further develop the existing framework. We conducted an informal literature search on scoping study methodology. We searched CINAHL, MEDLINE, PubMed, ERIC, PsycInfo, and Web of Science databases using the search terms 'scoping,' 'scoping study,' 'scoping review,' and 'scoping methodology' for papers published in English between January 1990 and May 2010. Reference lists of pertinent papers were also searched. This search yielded seven citations that reflected on scoping study methodology, which were reviewed by one author (DL). After independently considering our own experiences utilizing the Arskey and O'Malley [ 6 ] framework, we met on seven occasions to discuss the challenges and develop recommendations for each stage of the methodological framework.
Recommendations to enhance scoping study methodology
We outline the challenges and recommendations associated with each stage of the methodological framework (Table (Table3 3 ).
Summary of challenges and recommendations for scoping studies
| Framework Stage | Challenges | Recommendations for clarification or additional steps |
|---|---|---|
| #1 Identifying the research question | 1. Scoping study questions are broad. 2. Establishing scoping study purpose is not associated with a framework stage. 3. The four purposes of scoping studies lack clarity. | 1. Clearly articulate the research question that will guide the scope of inquiry. Consider the concept, target population, and health outcomes of interest to clarify the focus of the scoping study and establish an effective search strategy. 2. Mutually consider the purpose of the scoping study with the research question. Envision the intended outcome ( ., framework, list of recommendations) to help determine the purpose of the study. 3. Consider rationale for conducting the scoping study to help clarify the purpose. |
| #2 Identifying relevant studies | 1. Balancing breadth and comprehensiveness of the scoping study with feasibility of resources can be challenging. | 1a. Research question and purpose should guide decision-making around the scope of the study. 1b. Assemble a suitable team with content and methodological expertise that will ensure successful completion of the study. 1c. When limiting scope is unavoidable, justify decisions and acknowledge the potential limitations to the study. |
| #3 Study selection | 1. The linearity of this stage is misleading. 2. The process of decision making for study selection is unclear. | 1. This stage should be considered an iterative process involving searching the literature, refining the search strategy, and reviewing articles for study inclusion. 2a. At the beginning of the process, the team should meet to discuss decisions surrounding study inclusion and exclusion. At least two reviewers should independently review abstracts for inclusion. 2b. Reviewers should meet at the beginning, midpoint and final stages of the abstract review process to discuss challenges and uncertainties related to study selection and to go back and refine the search strategy if needed. 2c. Two researchers should independently review full articles for inclusion. 2d. When disagreements on study inclusion occur, a third reviewer can determine final inclusion. |
| #4 Charting the data | 1. The nature and extent of data to extract from included studies is unclear. 2. The 'descriptive analytical method' of charting data is poorly defined. | 1a. The research team should collectively develop the data-charting form and determine which variables to extract in order to answer the research question. 1b. Charting should be considered an iterative process in which researchers continually extract data and update the data-charting form. 1c. Two authors should independently extract data from the first five to ten included studies using the data-charting form and meet to determine whether their approach to data extraction is consistent with the research question and purpose. 2. Process-oriented data may require extra planning for analysis. A qualitative content analysis approach is suggested. |
| #5 Collating, summarizing, and reporting the results | 1. Little detail provided and multiple steps are summarized as one framework stage. | Researchers should break this stage into three distinct steps: 1a. Analysis (including descriptive numerical summary analysis and qualitative thematic analysis); 1b. Reporting the results and producing the outcome that refers to the overall purpose or research question; 1c. Consider the meaning of the findings as they relate to the overall study purpose; discuss implications for future research, practice and policy. |
| #6 Consultation | 1. This stage is optional. 2. Lack of clarity exists about when, how and why to consult with stakeholders and how to integrate the information with study findings. | 1. Consultation should be an essential component of scoping study methodology. 2a. Clearly establish a purpose for the consultation. 2b. Preliminary findings can be used as a foundation to inform the consultation. 2c. Clearly articulate the type of stakeholders to consult and how data will be collected, analyzed, reported and integrated within the overall study outcome. 2d. Incorporate opportunities for knowledge transfer and exchange with stakeholders in the field. |
Framework stage one: Identifying the research question
Scoping study research questions are broad in nature as the focus is on summarizing breadth of evidence. Arksey and O'Malley [ 6 ] acknowledge the need to maintain a broad scope to research questions, however we found our research questions lacked the direction, clarity, and focus needed to inform subsequent stages of the research process, such as identifying studies and making decisions about study inclusion. To clarify this stage, we recommend that researchers combine a broad research question with a clearly articulated scope of inquiry. This includes defining the concept, target population, and health outcomes of interest to clarify the focus of the scoping study and establish an effective search strategy. For example, in one author's (KO) scoping study, the research question was broadly 'what is known about HIV and rehabilitation?' Defining the concept of 'rehabilitation' was essential in order to establish a clear scope to the study, guide the search strategy, and establish parameters around study selection in subsequent stages of the process [ 7 ].
Although Arskey and O'Malley [ 6 ] outline four main purposes for undertaking a scoping study, they do not articulate that purpose be specified within a specific framework stage. We recommend researchers simultaneously consider the purpose of the scoping study when articulating the research question. Linking a clear purpose for undertaking a scoping study to a well-defined research question at the first stage of the framework will help to provide a clear rationale for completing the study and facilitate decision making about study selection and data extraction later in the methodological process. A helpful strategy may be to envision the content and format of the intended outcome that may assist researchers to clearly determine the purpose at the beginning of a study. In the abovementioned HIV study, authors linked the broadly stated research question with a more specific purpose 'to identify the key research priorities in HIV and rehabilitation to advance policy and practice for people living with HIV in Canada' [ 7 ]. The envisioned outcome was a thematic framework that represented strengths and opportunities in HIV rehabilitation research, followed by a list of the key research priorities to pursue in future work.
Finally, the purposes put forth by Arksey and O'Malley [ 6 ] require more debate. We concur with Anderson et al. [ 2 ] and Davis et al. [ 1 ], who state that researchers may benefit from further clarification of the purposes for undertaking a scoping study. The first purpose, as articulated by Arksey and O'Malley [ 6 ], is to summarize the extent, range, and nature of research activity; however, researchers are not required to reflect on their underlying motivation for doing so. We recommend that researchers consider the rationale for why they should summarize the activity in a field and the implications that this will have on research, practice, or policy. The second purpose is to assess the need for a full systematic review. However, it is difficult to determine whether a systematic review is advantageous when a scoping study does not involve methodological quality assessment of included studies. Furthermore, it is unclear how this purpose differs from existing methods of determining feasibility for a systematic review. The third purpose is to summarize and disseminate research findings, but we question how this differs from other narrative or systematic literature reviews. Lastly, the fourth purpose of undertaking a scoping study -- to identify gaps in the existing literature -- may yield false conclusions about the nature and extent of those gaps if the quality of the evidence is not assessed. The purpose 'to identify the key research priorities in HIV and rehabilitation to advance policy and practice for people living with HIV in Canada' does not explicitly align with one of the four Arskey and O'Malley purposes [ 7 ]. However, it appears authors inherently first summarized the extent, range, and nature of research (purpose one) and identified gaps in the existing literature (purpose four) in order to subsequently identify the key research priorities in HIV and rehabilitation (author purpose). This suggests authors might have an overall study purpose with multiple objectives articulated by Arksey and O'Malley that are required in order to help achieve their overall purpose.
Framework stage two: Identifying relevant studies
A strength of scoping studies includes the breadth and depth, or comprehensiveness, of evidence covered in a given field [ 1 ]. However, practical issues related to time, funding, and access to resources often require researchers to consider the balance between feasibility, breadth, and comprehensiveness. Brien et al. [ 5 ] reported that their search strategy yielded a vast amount of literature, making it difficult to determine how in depth to carry out the information synthesis. Although Arksey and O'Malley [ 6 ] identify these concerns and provide some suggestions to support these decisions, we also struggled with the trade-off between breadth and comprehensiveness and feasibility in our scoping studies. As such, we recommend that researchers ensure decisions surrounding feasibility do not compromise their ability to answer the research question or achieve the study purpose. Second, we recommend that a scoping study team be assembled whose members provide the methodological and context expertise needed for decisions regarding breadth and comprehensiveness. When limiting scope is unavoidable, researchers should justify their decisions and acknowledge the potential limitations of their study.
Framework stage three: Study selection
Arksey and O'Malley [ 6 ] provide suggestions to manage the time-consuming process of determining which studies to include in a scoping study. We experienced this stage as more iterative and requiring additional steps than implied in the original framework. While Arksey and O'Malley [ 6 ] do not indicate a team approach is imperative, we agree with others and suggest scoping studies involve multidisciplinary teams using a transparent and replicable process [ 2 , 10 ]. In two of our studies (HC and DL) where decision making was primarily completed by a single author, we faced several challenges, including uncertainty about which studies to include, variables to extract on the data-charting form, and the nature and extent of detail to conduct the data extraction process. This raised questions related to rigor and led to our recommendations for undertaking a systematic team approach to conducting a scoping study.
Specifically, we recommend that the team meet to discuss decisions surrounding study inclusion and exclusion at the beginning of the scoping process. Refining the search strategy based on abstracts retrieved from the search and reviewing full articles for study inclusion is also a critical step. We recommend that at least two researchers each independently review abstracts yielded from the search strategy for study selection. Reviewers should meet at the beginning, midpoint, and final stages of the abstract review process to discuss any challenges or uncertainties related to study selection and to go back and refine the search strategy if needed. This can help to alleviate potential ambiguity with a broad research question and to ensure that abstracts selected are relevant for full article review. Next, two reviewers should independently review the full articles for inclusion. When disagreements occur, a third reviewer can be consulted to determine final inclusion.
Framework stage four: Charting the data
This stage involves extracting data from included studies. Based on our experiences, we were uncertain about the nature and extent of information to extract from the included studies. To clarify this stage, we recommend that the research team collectively develop the data-charting form to determine which variables to extract that will help to answer the research question. Secondly, we recommend that charting be considered an iterative process in which researchers continually update the data-charting form. This is particularly true for process-oriented data, such as understanding how a theory or model has been used within a study. Uncertainty about the nature and extent of data that should be extracted may be resolved by researchers beginning the charting process and becoming familiar with study data, and then meeting again to refine the form. We recommend an additional step to charting the data in which two researchers independently extract data from the first five to ten studies using the data-charting form and meet to determine whether their approach to data extraction is consistent with the research question and purpose. Researchers may review one study several times within this stage. The number of researchers involved in the data extraction process will likely depend upon the number of included studies. For example, in one study, authors had difficulty developing one data-charting form that could apply to all included studies representing a range study designs, reviews, reports, and commentaries [ 7 ]. As a preliminary step, authors decided to classify the included studies into three areas --HIV disability, interventions, and roles of rehabilitation professionals in HIV care -- to help determine the nature and extent of information to extract from each of the types of studies [ 7 ].
Arksey and O'Malley [ 6 ] refer to a 'descriptive analytical method' that involves summarizing process information, such as the use of a theory or model in a meaningful format. Our experiences indicated that this is a highly valuable, though challenging aspect of scoping studies, as we struggled to chart and summarize complex concepts in a meaningful way. Arksey and O'Malley [ 6 ] indicate that synthesis of material is critical as scoping studies are not a short summary of many articles. We agree, and feel that additional direction in the framework might help to navigate this crucial but challenging stage. Perhaps synthesizing process information may benefit from utilization of qualitative content analysis approaches to make sense of the wealth of extracted data [ 11 ]. This issue also highlights the overlap with the next analytical stage. The role and relevance of analyzing process data and using qualitative content analysis within scoping study methodology requires further discussion.
Framework stage five: Collating, summarizing, and reporting the results
Stage five is the most extensive in the scoping process, yet it lacks detail in the Arksey and O'Malley framework. Scoping studies have been criticized for rarely providing methodological detail about how results were achieved [ 1 ]. We appreciate the importance of breaking the analysis phase into meaningful and systematic steps so that researchers can provide this undertake scoping studies and report on findings in a rigorous manner. As a result, we recommend three distinct steps in framework stage five to increase the consistency with which researchers undertake and report scoping study methodology: analyzing the data, reporting results, and applying meaning to the results. As described in the existing framework, analysis (otherwise referred to as collating and summarizing) should involve a descriptive numerical summary and a thematic analysis. Arksey and O'Malley [ 6 ] describe the need to provide a descriptive numerical summary, stating that researchers should describe the characteristics of included studies, such as the overall number of studies included, types of study design, years of publication, types of interventions, characteristics of the study populations, and countries where studies were conducted. However, the description of thematic analysis requires additional detail to assist authors in understanding and completing this step. In our experience, this analytical stage resembled qualitative data analytical techniques, and researchers may consider using qualitative content analytical techniques [ 10 ] and qualitative software to facilitate this process.
Second, when reporting results, we recommend that researchers consider the best approach to stating the outcome or end product of the study and how the scoping study findings will be articulated to readers ( e.g ., through themes, a framework, or a table of strengths and gaps in the evidence). This product should be tied to the purpose of the scoping study as recommended in framework stage one.
Finally, in order to advance the legitimacy of scoping study methodology, we must consider the implications of findings within the broader context. As a result, we recommend that researchers consider the meaning of their scoping study results and the broader implications for research, policy, and practice. For example, for the question 'how are motor-learning strategies used within contemporary physical and occupational therapy intervention approaches for children with neuromotor conditions?,' the author (DL) presented themes that described strategy use. Results yielded insights into how researchers should better describe interventions in their publications and provided further considerations for clinicians to make informed decisions about which therapeutic approach might best fit their clients' needs. Considering the overall implications of the results as an explicit framework stage will help to ensure that scoping study results have practical implications for future clinical practice, research, and policy. This recommendation leads to the final stage of the framework.
Optional stage six: Consultation
Arksey and O'Malley [ 6 ] suggest that consultation is an optional stage in conducting a scoping study. Although only one of our three scoping studies incorporated this stage, we argue that it adds methodological rigor and should be considered a required component. Arksey and O'Malley [ 6 ] suggest that the purposes of consulting with stakeholders are to offer additional sources of information, perspectives, meaning, and applicability to the scoping study. However, it is unclear when, how, and why to consult with stakeholders, and how to analyze and integrate these data with the findings. We recommend researchers clearly establish a purpose for the consultation, which may include sharing preliminary findings with stakeholders, validating the findings, or informing future research. We suggest researchers use preliminary findings from stage five (either in the form of a framework, themes, or list of findings) as a foundation from which to inform the consultation. This will enable stakeholders to build on the evidence and offer a higher level of meaning, content expertise, and perspective to the preliminary findings. We also recommend that researchers clearly articulate the type of stakeholders with whom they wish to consult, how they will collect the data ( e.g ., focus groups, interviews, surveys), and how these data will be analyzed, reported, and integrated within the overall study outcome.
Finally, given that consultation requires researchers to orient stakeholders on the scoping study purpose, research question, preliminary findings, and plans for dissemination, we recommend that this stage additionally be considered a knowledge transfer mechanism. This may address Brien et al .'s [ 5 ] concern about the usefulness of scoping studies for stakeholders and how to translate knowledge about scoping studies. Given the importance of knowledge transfer and exchange in the uptake of research evidence [ 12 , 13 ], the consultation stage can be used to specifically translate the preliminary scoping study findings and develop effective dissemination strategies with stakeholders in the field, offering additional value to a scoping study.
One scoping study included a consultation phase comprised of focus groups and interviews with 28 stakeholders including people living with HIV, researchers, educators, clinicians, and policy makers [ 7 ]. Authors shared preliminary findings from the literature review phase of the scoping study with stakeholders and asked whether they may be able to identify any additional emerging issues related to HIV and rehabilitation not yet published in the evidence. The team proceeded to conduct a second consultation with 17 new and returning stakeholders whereby the team presented a preliminary framework of HIV and rehabilitation research and stakeholders refined the framework to further identify six key research priorities on HIV and rehabilitation. This series of consultations engaged community members in the development of the study outcome and provided opportunities for knowledge transfer about HIV and rehabilitation research. This process offered an ideal mechanism to enhance the validity of the study outcome while translating findings with the community. Nevertheless, further development of steps for undertaking knowledge translation as a part of the scoping study framework is required.
Additional considerations for scoping studies to support the advancement, application, and relevance of scoping studies in health research
Scoping study terminology.
Discrepancies in nomenclature between 'scoping reviews,' 'scoping studies,' 'scoping literature reviews,' and 'scoping exercises' lead to confusion. Despite our collective use of the Arksey and O'Malley framework, two authors (DL, HC) titled their studies as 'scoping reviews' while the other used 'scoping study.' In this paper, we use 'scoping studies' for consistency with Arksey and O'Malley's original framework. Nevertheless, the potential differences (if any) among the terms merit clarification. Lack of a universal definition for scoping studies is also problematic to researchers trying to clearly articulate their reasons for undertaking a scoping study. Finally, we advocate for labeling the methodology as the 'Arksey and O'Malley framework' to provide consistency for future use.
Quality assessment
Another consideration for scoping study methodology is the potential need to assess included studies for methodological quality. Brien et al. [ 5 ] state that this lack of quality assessment makes the results of scoping studies more challenging to interpret. Grant and Booth [ 4 ] imply that a lack of quality assessment limits the uptake of scoping study findings into policy and practice. While our research questions did not directly relate to any quality assessment debate, we recognize the challenges in assessing quality among the vast range of published and grey literature that may be included in scoping studies. This also raises the question of whether and how evidence from stakeholder consultation is evaluated in the scoping study process. It remains unclear whether the lack of quality assessment impacts the uptake and relevance of scoping study findings.
A final consideration for legitimization of scoping study methodology includes the development of a critical appraisal tool for scoping study quality [ 5 ]. Anderson et al. [ 2 ] offer criteria for assessing the value and utility of a commissioned scoping study in health policy contexts, but these criteria are not necessarily applicable to scoping studies in other areas of health research. Developing a critical appraisal tool would require the elements of a methodologically rigorous scoping study to be defined. This could include, but would not be limited to, the minimum level of analysis required and the requirements for reporting results. Overall, the issues surrounding quality assessment of included studies and subsequent scoping studies require further discussion.
Limitations
This paper responds to Arksey and O'Malley's [ 6 ] request for feedback to their proposed methodological framework. However, the recommendations that we propose are derived from our subjective experiences undertaking scoping studies of varying sizes in the rehabilitation field, and we recognize that they may not represent the opinions of all scoping study authors. Other than our individual experiences with our own studies, we have not yet implemented the full framework recommendations. Hence, readers can determine how strongly to interpret and implement these recommendations in their scoping study research. We invite others to trial our recommendations and continue the process of refining and improving this methodology.
Scoping studies present an increasingly popular option for synthesizing health evidence. Brien et al. [ 5 ] argue that guidelines are required to facilitate scoping review reporting and transparency. In this paper, we build on the existing methodological framework for scoping studies outlined by Arksey and O'Malley [ 6 ] and provide recommendations to clarify and enhance each stage, which may increase the consistency with which researchers undertake and report scoping studies. Recommendations include: clarifying and linking the purpose and research question; balancing feasibility with breadth and comprehensiveness of the scoping process; using an iterative team approach to selecting studies and extracting data; incorporating a numerical summary and qualitative thematic analysis; identifying the implications of the study findings for policy, practice, or research; and adopting consultation as a required component of scoping study methodology. Ongoing considerations include: establishing a common accepted definition and purpose(s) of scoping studies; defining methodological rigor for the assessment of scoping study quality; debating the need for quality assessment of included studies; and formalizing knowledge translation as a required element of scoping methodology. Continued debate and development about scoping study methodology will help to maximize the usefulness of scoping study findings within healthcare research and practice.
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
DL and HC conceived of this paper. DL undertook the literature review process. DL, HC and KO developed challenges and recommendations. All authors drafted the manuscript. All authors read and approved the final manuscript.
Authors' information
DL is a physical therapist and doctoral candidate in the School of Rehabilitation Science at McMaster University. HC is an occupational therapist and doctoral candidate in the School of Rehabilitation Science at McMaster University. KO is a clinical epidemiologist, physical therapist, and postdoctoral fellow in the School of Rehabilitation Science at McMaster University. She is also a Lecturer in the Department of Physical Therapy at the University of Toronto.
Acknowledgements
DL is supported by a Doctoral Award from the Canadian Child Health Clinician Scientist Program, a strategic training initiative of the Canadian Institutes of Health Research (CIHR), and the McMaster Child Health Research Institute. HC is supported by a Doctoral Award from the CIHR, the CIHR Quality of Life Strategic Training Program in Rehabilitation Research and the Canadian Occupational Therapy Foundation. KO is supported by a Fellowship from the CIHR, HIV/AIDS Research Program and a Michael DeGroote Postdoctoral Fellowship (McMaster University). The authors acknowledge the helpful feedback of Dr. Cheryl Missiuna on an earlier draft of this manuscript.
- Davis K, Drey N, Gould D. What are scoping studies? A review of the nursing literature. Int J Nurs Stud. 2009; 46 :1386–1400. doi: 10.1016/j.ijnurstu.2009.02.010. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Anderson S, Allen P, Peckham S, Goodwin N. Asking the right questions: scoping studies in the commissioning of research on the organisation and delivery of health services. Health Res Policy Sys. 2008; 6 :7. doi: 10.1186/1478-4505-6-7. [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Rumrill P, Fitzgerald S, Merchant W. Using scoping literature reviews as a means of understanding and interpreting existing literature. Work. 2010; 35 :399–404. [ PubMed ] [ Google Scholar ]
- Grant M, Booth A. A typology of reviews: an analysis of 14 review types and associated methodologies. Health Info Libr J. 2009; 26 :91–108. doi: 10.1111/j.1471-1842.2009.00848.x. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Brien S, Lorenzetti D, Lewis S, Kennedy J, Ghali W. Overview of a formal scoping review on health system report cards. Implement Sci. 2010; 5 :2. doi: 10.1186/1748-5908-5-2. [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Arksey H, O'Malley L. Scoping studies: Towards a Methodological Framework. Int J Soc Res Methodol. 2005; 8 :19–32. doi: 10.1080/1364557032000119616. [ CrossRef ] [ Google Scholar ]
- O'Brien K, Wilkins A, Zack E, Solomon P. Scoping the field: identifying key research priorities in HIV and rehabilitation. AIDS Behav. 2010; 14 :448–458. doi: 10.1007/s10461-009-9528-z. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Levac D, Wishart L, Missiuna C, Wright V. The application of motor learning strategies within functionally based interventions for children with neuromotor conditions. Peds Phys Ther. 2009; 21 :345–355. doi: 10.1097/PEP.0b013e3181beb09d. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Colquhoun H, Letts L, Law M, MacDermid J, Missiuna C. A scoping review of the use of theory in studies of knowledge translation. Can J Occup Ther. in press . [ PubMed ]
- Ehrich K, Freeman G, Richards S, Robinson I, Shepperd S. How to do a scoping exercise: continuity of care. Res Pol Plan. 2002; 20 :25–29. [ Google Scholar ]
- Hsieh HF, Shannon SE. Three approaches to qualitative content analysis. Qual Health Res. 2005; 15 :1277–1288. doi: 10.1177/1049732305276687. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Graham ID, Logan J, Harrison MB, Straus SE, Tetroe J, Caswell W, Robinson N. Lost in knowledge translation: time for a map? J Contin Educ Health Prof. 2006; 26 :13–24. doi: 10.1002/chp.47. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Schuster M, McGlynn E, Brook R. How good is the quality of healthcare in the United States? Milbank Q. 2005; 83 :843–895. doi: 10.1111/j.1468-0009.2005.00403.x. [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Mays N, Roberts E, Popay J. In: Studying the organization and delivery of health services: research methods. Fulop N, Allen P, Clarke A, Black N, editor. London: Routledge; 2001. Synthesising research evidence; p. 194. [ Google Scholar ]
- Canadian Institutes of Health Research. Knowledge Translation. http://www.cihr-irsc.gc.ca/e/29418.html
Reference management. Clean and simple.
What is research methodology?

The basics of research methodology
Why do you need a research methodology, what needs to be included, why do you need to document your research method, what are the different types of research instruments, qualitative / quantitative / mixed research methodologies, how do you choose the best research methodology for you, frequently asked questions about research methodology, related articles.
When you’re working on your first piece of academic research, there are many different things to focus on, and it can be overwhelming to stay on top of everything. This is especially true of budding or inexperienced researchers.
If you’ve never put together a research proposal before or find yourself in a position where you need to explain your research methodology decisions, there are a few things you need to be aware of.
Once you understand the ins and outs, handling academic research in the future will be less intimidating. We break down the basics below:
A research methodology encompasses the way in which you intend to carry out your research. This includes how you plan to tackle things like collection methods, statistical analysis, participant observations, and more.
You can think of your research methodology as being a formula. One part will be how you plan on putting your research into practice, and another will be why you feel this is the best way to approach it. Your research methodology is ultimately a methodological and systematic plan to resolve your research problem.
In short, you are explaining how you will take your idea and turn it into a study, which in turn will produce valid and reliable results that are in accordance with the aims and objectives of your research. This is true whether your paper plans to make use of qualitative methods or quantitative methods.
The purpose of a research methodology is to explain the reasoning behind your approach to your research - you'll need to support your collection methods, methods of analysis, and other key points of your work.
Think of it like writing a plan or an outline for you what you intend to do.
When carrying out research, it can be easy to go off-track or depart from your standard methodology.
Tip: Having a methodology keeps you accountable and on track with your original aims and objectives, and gives you a suitable and sound plan to keep your project manageable, smooth, and effective.
With all that said, how do you write out your standard approach to a research methodology?
As a general plan, your methodology should include the following information:
- Your research method. You need to state whether you plan to use quantitative analysis, qualitative analysis, or mixed-method research methods. This will often be determined by what you hope to achieve with your research.
- Explain your reasoning. Why are you taking this methodological approach? Why is this particular methodology the best way to answer your research problem and achieve your objectives?
- Explain your instruments. This will mainly be about your collection methods. There are varying instruments to use such as interviews, physical surveys, questionnaires, for example. Your methodology will need to detail your reasoning in choosing a particular instrument for your research.
- What will you do with your results? How are you going to analyze the data once you have gathered it?
- Advise your reader. If there is anything in your research methodology that your reader might be unfamiliar with, you should explain it in more detail. For example, you should give any background information to your methods that might be relevant or provide your reasoning if you are conducting your research in a non-standard way.
- How will your sampling process go? What will your sampling procedure be and why? For example, if you will collect data by carrying out semi-structured or unstructured interviews, how will you choose your interviewees and how will you conduct the interviews themselves?
- Any practical limitations? You should discuss any limitations you foresee being an issue when you’re carrying out your research.
In any dissertation, thesis, or academic journal, you will always find a chapter dedicated to explaining the research methodology of the person who carried out the study, also referred to as the methodology section of the work.
A good research methodology will explain what you are going to do and why, while a poor methodology will lead to a messy or disorganized approach.
You should also be able to justify in this section your reasoning for why you intend to carry out your research in a particular way, especially if it might be a particularly unique method.
Having a sound methodology in place can also help you with the following:
- When another researcher at a later date wishes to try and replicate your research, they will need your explanations and guidelines.
- In the event that you receive any criticism or questioning on the research you carried out at a later point, you will be able to refer back to it and succinctly explain the how and why of your approach.
- It provides you with a plan to follow throughout your research. When you are drafting your methodology approach, you need to be sure that the method you are using is the right one for your goal. This will help you with both explaining and understanding your method.
- It affords you the opportunity to document from the outset what you intend to achieve with your research, from start to finish.
A research instrument is a tool you will use to help you collect, measure and analyze the data you use as part of your research.
The choice of research instrument will usually be yours to make as the researcher and will be whichever best suits your methodology.
There are many different research instruments you can use in collecting data for your research.
Generally, they can be grouped as follows:
- Interviews (either as a group or one-on-one). You can carry out interviews in many different ways. For example, your interview can be structured, semi-structured, or unstructured. The difference between them is how formal the set of questions is that is asked of the interviewee. In a group interview, you may choose to ask the interviewees to give you their opinions or perceptions on certain topics.
- Surveys (online or in-person). In survey research, you are posing questions in which you ask for a response from the person taking the survey. You may wish to have either free-answer questions such as essay-style questions, or you may wish to use closed questions such as multiple choice. You may even wish to make the survey a mixture of both.
- Focus Groups. Similar to the group interview above, you may wish to ask a focus group to discuss a particular topic or opinion while you make a note of the answers given.
- Observations. This is a good research instrument to use if you are looking into human behaviors. Different ways of researching this include studying the spontaneous behavior of participants in their everyday life, or something more structured. A structured observation is research conducted at a set time and place where researchers observe behavior as planned and agreed upon with participants.
These are the most common ways of carrying out research, but it is really dependent on your needs as a researcher and what approach you think is best to take.
It is also possible to combine a number of research instruments if this is necessary and appropriate in answering your research problem.
There are three different types of methodologies, and they are distinguished by whether they focus on words, numbers, or both.
| Data type | What is it? | Methodology |
|---|---|---|
Quantitative | This methodology focuses more on measuring and testing numerical data. What is the aim of quantitative research? | Surveys, tests, existing databases. |
Qualitative | Qualitative research is a process of collecting and analyzing both words and textual data. | Observations, interviews, focus groups. |
Mixed-method | A mixed-method approach combines both of the above approaches. | Where you can use a mixed method of research, this can produce some incredibly interesting results. This is due to testing in a way that provides data that is both proven to be exact while also being exploratory at the same time. |
➡️ Want to learn more about the differences between qualitative and quantitative research, and how to use both methods? Check out our guide for that!
If you've done your due diligence, you'll have an idea of which methodology approach is best suited to your research.
It’s likely that you will have carried out considerable reading and homework before you reach this point and you may have taken inspiration from other similar studies that have yielded good results.
Still, it is important to consider different options before setting your research in stone. Exploring different options available will help you to explain why the choice you ultimately make is preferable to other methods.
If proving your research problem requires you to gather large volumes of numerical data to test hypotheses, a quantitative research method is likely to provide you with the most usable results.
If instead you’re looking to try and learn more about people, and their perception of events, your methodology is more exploratory in nature and would therefore probably be better served using a qualitative research methodology.
It helps to always bring things back to the question: what do I want to achieve with my research?
Once you have conducted your research, you need to analyze it. Here are some helpful guides for qualitative data analysis:
➡️ How to do a content analysis
➡️ How to do a thematic analysis
➡️ How to do a rhetorical analysis
Research methodology refers to the techniques used to find and analyze information for a study, ensuring that the results are valid, reliable and that they address the research objective.
Data can typically be organized into four different categories or methods: observational, experimental, simulation, and derived.
Writing a methodology section is a process of introducing your methods and instruments, discussing your analysis, providing more background information, addressing your research limitations, and more.
Your research methodology section will need a clear research question and proposed research approach. You'll need to add a background, introduce your research question, write your methodology and add the works you cited during your data collecting phase.
The research methodology section of your study will indicate how valid your findings are and how well-informed your paper is. It also assists future researchers planning to use the same methodology, who want to cite your study or replicate it.

- Privacy Policy
Home » Delimitations in Research – Types, Examples and Writing Guide
Delimitations in Research – Types, Examples and Writing Guide
Table of Contents

Delimitations
Definition:
Delimitations refer to the specific boundaries or limitations that are set in a research study in order to narrow its scope and focus. Delimitations may be related to a variety of factors, including the population being studied, the geographical location, the time period, the research design , and the methods or tools being used to collect data .
The Importance of Delimitations in Research Studies
Here are some reasons why delimitations are important in research studies:
- Provide focus : Delimitations help researchers focus on a specific area of interest and avoid getting sidetracked by tangential topics. By setting clear boundaries, researchers can concentrate their efforts on the most relevant and significant aspects of the research question.
- Increase validity : Delimitations ensure that the research is more valid by defining the boundaries of the study. When researchers establish clear criteria for inclusion and exclusion, they can better control for extraneous variables that might otherwise confound the results.
- Improve generalizability : Delimitations help researchers determine the extent to which their findings can be generalized to other populations or contexts. By specifying the sample size, geographic region, time frame, or other relevant factors, researchers can provide more accurate estimates of the generalizability of their results.
- Enhance feasibility : Delimitations help researchers identify the resources and time required to complete the study. By setting realistic parameters, researchers can ensure that the study is feasible and can be completed within the available time and resources.
- Clarify scope: Delimitations help readers understand the scope of the research project. By explicitly stating what is included and excluded, researchers can avoid confusion and ensure that readers understand the boundaries of the study.
Types of Delimitations in Research
Here are some types of delimitations in research and their significance:
Time Delimitations
This type of delimitation refers to the time frame in which the research will be conducted. Time delimitations are important because they help to narrow down the scope of the study and ensure that the research is feasible within the given time constraints.
Geographical Delimitations
Geographical delimitations refer to the geographic boundaries within which the research will be conducted. These delimitations are significant because they help to ensure that the research is relevant to the intended population or location.
Population Delimitations
Population delimitations refer to the specific group of people that the research will focus on. These delimitations are important because they help to ensure that the research is targeted to a specific group, which can improve the accuracy of the results.
Data Delimitations
Data delimitations refer to the specific types of data that will be used in the research. These delimitations are important because they help to ensure that the data is relevant to the research question and that the research is conducted using reliable and valid data sources.
Scope Delimitations
Scope delimitations refer to the specific aspects or dimensions of the research that will be examined. These delimitations are important because they help to ensure that the research is focused and that the findings are relevant to the research question.
How to Write Delimitations
In order to write delimitations in research, you can follow these steps:
- Identify the scope of your study : Determine the extent of your research by defining its boundaries. This will help you to identify the areas that are within the scope of your research and those that are outside of it.
- Determine the time frame : Decide on the time period that your research will cover. This could be a specific period, such as a year, or it could be a general time frame, such as the last decade.
- I dentify the population : Determine the group of people or objects that your study will focus on. This could be a specific age group, gender, profession, or geographic location.
- Establish the sample size : Determine the number of participants that your study will involve. This will help you to establish the number of people you need to recruit for your study.
- Determine the variables: Identify the variables that will be measured in your study. This could include demographic information, attitudes, behaviors, or other factors.
- Explain the limitations : Clearly state the limitations of your study. This could include limitations related to time, resources, sample size, or other factors that may impact the validity of your research.
- Justify the limitations : Explain why these limitations are necessary for your research. This will help readers understand why certain factors were excluded from the study.
When to Write Delimitations in Research
Here are some situations when you may need to write delimitations in research:
- When defining the scope of the study: Delimitations help to define the boundaries of your research by specifying what is and what is not included in your study. For instance, you may delimit your study by focusing on a specific population, geographic region, time period, or research methodology.
- When addressing limitations: Delimitations can also be used to address the limitations of your research. For example, if your data is limited to a certain timeframe or geographic area, you can include this information in your delimitations to help readers understand the limitations of your findings.
- When justifying the relevance of the study : Delimitations can also help you to justify the relevance of your research. For instance, if you are conducting a study on a specific population or region, you can explain why this group or area is important and how your research will contribute to the understanding of this topic.
- When clarifying the research question or hypothesis : Delimitations can also be used to clarify your research question or hypothesis. By specifying the boundaries of your study, you can ensure that your research question or hypothesis is focused and specific.
- When establishing the context of the study : Finally, delimitations can help you to establish the context of your research. By providing information about the scope and limitations of your study, you can help readers to understand the context in which your research was conducted and the implications of your findings.
Examples of Delimitations in Research
Examples of Delimitations in Research are as follows:
Research Title : “Impact of Artificial Intelligence on Cybersecurity Threat Detection”
Delimitations :
- The study will focus solely on the use of artificial intelligence in detecting and mitigating cybersecurity threats.
- The study will only consider the impact of AI on threat detection and not on other aspects of cybersecurity such as prevention, response, or recovery.
- The research will be limited to a specific type of cybersecurity threats, such as malware or phishing attacks, rather than all types of cyber threats.
- The study will only consider the use of AI in a specific industry, such as finance or healthcare, rather than examining its impact across all industries.
- The research will only consider AI-based threat detection tools that are currently available and widely used, rather than including experimental or theoretical AI models.
Research Title: “The Effects of Social Media on Academic Performance: A Case Study of College Students”
Delimitations:
- The study will focus only on college students enrolled in a particular university.
- The study will only consider social media platforms such as Facebook, Twitter, and Instagram.
- The study will only analyze the academic performance of students based on their GPA and course grades.
- The study will not consider the impact of other factors such as student demographics, socioeconomic status, or other factors that may affect academic performance.
- The study will only use self-reported data from students, rather than objective measures of their social media usage or academic performance.
Purpose of Delimitations
Some Purposes of Delimitations are as follows:
- Focusing the research : By defining the scope of the study, delimitations help researchers to narrow down their research questions and focus on specific aspects of the topic. This allows for a more targeted and meaningful study.
- Clarifying the research scope : Delimitations help to clarify the boundaries of the research, which helps readers to understand what is and is not included in the study.
- Avoiding scope creep : Delimitations help researchers to stay focused on their research objectives and avoid being sidetracked by tangential issues or data.
- Enhancing the validity of the study : By setting clear boundaries, delimitations help to ensure that the study is valid and reliable.
- Improving the feasibility of the study : Delimitations help researchers to ensure that their study is feasible and can be conducted within the time and resources available.
Applications of Delimitations
Here are some common applications of delimitations:
- Geographic delimitations : Researchers may limit their study to a specific geographic area, such as a particular city, state, or country. This helps to narrow the focus of the study and makes it more manageable.
- Time delimitations : Researchers may limit their study to a specific time period, such as a decade, a year, or a specific date range. This can be useful for studying trends over time or for comparing data from different time periods.
- Population delimitations : Researchers may limit their study to a specific population, such as a particular age group, gender, or ethnic group. This can help to ensure that the study is relevant to the population being studied.
- Data delimitations : Researchers may limit their study to specific types of data, such as survey responses, interviews, or archival records. This can help to ensure that the study is based on reliable and relevant data.
- Conceptual delimitations : Researchers may limit their study to specific concepts or variables, such as only studying the effects of a particular treatment on a specific outcome. This can help to ensure that the study is focused and clear.
Advantages of Delimitations
Some Advantages of Delimitations are as follows:
- Helps to focus the study: Delimitations help to narrow down the scope of the research and identify specific areas that need to be investigated. This helps to focus the study and ensures that the research is not too broad or too narrow.
- Defines the study population: Delimitations can help to define the population that will be studied. This can include age range, gender, geographical location, or any other factors that are relevant to the research. This helps to ensure that the study is more specific and targeted.
- Provides clarity: Delimitations help to provide clarity about the research study. By identifying the boundaries and limitations of the research, it helps to avoid confusion and ensures that the research is more understandable.
- Improves validity: Delimitations can help to improve the validity of the research by ensuring that the study is more focused and specific. This can help to ensure that the research is more accurate and reliable.
- Reduces bias: Delimitations can help to reduce bias by limiting the scope of the research. This can help to ensure that the research is more objective and unbiased.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Research Findings – Types Examples and Writing...

What is a Hypothesis – Types, Examples and...

Research Techniques – Methods, Types and Examples

Chapter Summary & Overview – Writing Guide...

APA Research Paper Format – Example, Sample and...

Research Paper Title – Writing Guide and Example
A step-by-step guide to causal study design using real-world data
- Open access
- Published: 19 June 2024
Cite this article
You have full access to this open access article

- Sarah Ruth Hoffman 1 ,
- Nilesh Gangan 1 ,
- Xiaoxue Chen 2 ,
- Joseph L. Smith 1 ,
- Arlene Tave 1 ,
- Yiling Yang 1 ,
- Christopher L. Crowe 1 ,
- Susan dosReis 3 &
- Michael Grabner 1
166 Accesses
Explore all metrics
Due to the need for generalizable and rapidly delivered evidence to inform healthcare decision-making, real-world data have grown increasingly important to answer causal questions. However, causal inference using observational data poses numerous challenges, and relevant methodological literature is vast. We endeavored to identify underlying unifying themes of causal inference using real-world healthcare data and connect them into a single schema to aid in observational study design, and to demonstrate this schema using a previously published research example. A multidisciplinary team (epidemiology, biostatistics, health economics) reviewed the literature related to causal inference and observational data to identify key concepts. A visual guide to causal study design was developed to concisely and clearly illustrate how the concepts are conceptually related to one another. A case study was selected to demonstrate an application of the guide. An eight-step guide to causal study design was created, integrating essential concepts from the literature, anchored into conceptual groupings according to natural steps in the study design process. The steps include defining the causal research question and the estimand; creating a directed acyclic graph; identifying biases and design and analytic techniques to mitigate their effect, and techniques to examine the robustness of findings. The cardiovascular case study demonstrates the applicability of the steps to developing a research plan. This paper used an existing study to demonstrate the relevance of the guide. We encourage researchers to incorporate this guide at the study design stage in order to elevate the quality of future real-world evidence.
Similar content being viewed by others

Examples of Applying Causal-Inference Roadmap to Real-World Studies

Selection Mechanisms and Their Consequences: Understanding and Addressing Selection Bias

Assessing causality in epidemiology: revisiting Bradford Hill to incorporate developments in causal thinking
Avoid common mistakes on your manuscript.
1 Introduction
Approximately 50 new drugs are approved each year in the United States (Mullard 2022 ). For all new drugs, randomized controlled trials (RCTs) are the gold-standard by which potential effectiveness (“efficacy”) and safety are established. However, RCTs cannot guarantee how a drug will perform in a less controlled context. For this reason, regulators frequently require observational, post-approval studies using “real-world” data, sometimes even as a condition of drug approval. The “real-world” data requested by regulators is often derived from insurance claims databases and/or healthcare records. Importantly, these data are recorded during routine clinical care without concern for potential use in research. Yet, in recent years, there has been increasing use of such data for causal inference and regulatory decision making, presenting a variety of methodologic challenges for researchers and stakeholders to consider (Arlett et al. 2022 ; Berger et al. 2017 ; Concato and ElZarrad 2022 ; Cox et al. 2009 ; European Medicines Agency 2023 ; Franklin and Schneeweiss 2017 ; Girman et al. 2014 ; Hernán and Robins 2016 ; International Society for Pharmacoeconomics and Outcomes Research (ISPOR) 2022 ; International Society for Pharmacoepidemiology (ISPE) 2020 ; Stuart et al. 2013 ; U.S. Food and Drug Administration 2018 ; Velentgas et al. 2013 ).
Current guidance for causal inference using observational healthcare data articulates the need for careful study design (Berger et al. 2017 ; Cox et al. 2009 ; European Medicines Agency 2023 ; Girman et al. 2014 ; Hernán and Robins 2016 ; Stuart et al. 2013 ; Velentgas et al. 2013 ). In 2009, Cox et al. described common sources of bias in observational data and recommended specific strategies to mitigate these biases (Cox et al. 2009 ). In 2013, Stuart et al. emphasized counterfactual theory and trial emulation, offered several approaches to address unmeasured confounding, and provided guidance on the use of propensity scores to balance confounding covariates (Stuart et al. 2013 ). In 2013, the Agency for Healthcare Research and Quality (AHRQ) released an extensive, 200-page guide to developing a protocol for comparative effectiveness research using observational data (Velentgas et al. 2013 ). The guide emphasized development of the research question, with additional chapters on study design, comparator selection, sensitivity analyses, and directed acyclic graphs (Velentgas et al. 2013 ). In 2014, Girman et al. provided a clear set of steps for assessing study feasibility including examination of the appropriateness of the data for the research question (i.e., ‘fit-for-purpose’), empirical equipoise, and interpretability, stating that comparative effectiveness research using observational data “should be designed with the goal of drawing a causal inference” (Girman et al. 2014 ). In 2017 , Berger et al. described aspects of “study hygiene,” focusing on procedural practices to enhance confidence in, and credibility of, real-world data studies (Berger et al. 2017 ). Currently, the European Network of Centres for Pharmacoepidemiology and Pharmacovigilance (ENCePP) maintains a guide on methodological standards in pharmacoepidemiology which discusses causal inference using observational data and includes an overview of study designs, a chapter on methods to address bias and confounding, and guidance on writing statistical analysis plans (European Medicines Agency 2023 ). In addition to these resources, the “target trial framework” provides a structured approach to planning studies for causal inferences from observational databases (Hernán and Robins 2016 ; Wang et al. 2023b ). This framework, published in 2016, encourages researchers to first imagine a clinical trial for the study question of interest and then to subsequently design the observational study to reflect the hypothetical trial (Hernán and Robins 2016 ).
While the literature addresses critical issues collectively, there remains a need for a framework that puts key components, including the target trial approach, into a simple, overarching schema (Loveless 2022 ) so they can be more easily remembered, and communicated to all stakeholders including (new) researchers, peer-reviewers, and other users of the research findings (e.g., practicing providers, professional clinical societies, regulators). For this reason, we created a step-by-step guide for causal inference using administrative health data, which aims to integrate these various best practices at a high level and complements existing, more specific guidance, including those from the International Society for Pharmacoeconomics and Outcomes Research (ISPOR) and the International Society for Pharmacoepidemiology (ISPE) (Berger et al. 2017 ; Cox et al. 2009 ; Girman et al. 2014 ). We demonstrate the application of this schema using a previously published paper in cardiovascular research.
This work involved a formative phase and an implementation phase to evaluate the utility of the causal guide. In the formative phase, a multidisciplinary team with research expertise in epidemiology, biostatistics, and health economics reviewed selected literature (peer-reviewed publications, including those mentioned in the introduction, as well as graduate-level textbooks) related to causal inference and observational healthcare data from the pharmacoepidemiologic and pharmacoeconomic perspectives. The potential outcomes framework served as the foundation for our conception of causal inference (Rubin 2005 ). Information was grouped into the following four concepts: (1) Defining the Research Question; (2) Defining the Estimand; (3) Identifying and Mitigating Biases; (4) Sensitivity Analysis. A step-by-step guide to causal study design was developed to distill the essential elements of each concept, organizing them into a single schema so that the concepts are clearly related to one another. References for each step of the schema are included in the Supplemental Table.
In the implementation phase we tested the application of the causal guide to previously published work (Dondo et al. 2017 ). The previously published work utilized data from the Myocardial Ischaemia National Audit Project (MINAP), the United Kingdom’s national heart attack register. The goal of the study was to assess the effect of β-blockers on all-cause mortality among patients hospitalized for acute myocardial infarction without heart failure or left ventricular systolic dysfunction. We selected this paper for the case study because of its clear descriptions of the research goal and methods, and the explicit and methodical consideration of potential biases and use of sensitivity analyses to examine the robustness of the main findings.
3.1 Overview of the eight steps
The step-by-step guide to causal inference comprises eight distinct steps (Fig. 1 ) across the four concepts. As scientific inquiry and study design are iterative processes, the various steps may be completed in a different order than shown, and steps may be revisited.

A step-by-step guide for causal study design
Abbreviations: GEE: generalized estimating equations; IPC/TW: inverse probability of censoring/treatment weighting; ITR: individual treatment response; MSM: marginal structural model; TE: treatment effect
Please refer to the Supplemental Table for references providing more in-depth information.
1 Ensure that the exposure and outcome are well-defined based on literature and expert opinion.
2 More specifically, measures of association are not affected by issues such as confounding and selection bias because they do not intend to isolate and quantify a single causal pathway. However, information bias (e.g., variable misclassification) can negatively affect association estimates, and association estimates remain subject to random variability (and are hence reported with confidence intervals).
3 This list is not exhaustive; it focuses on frequently encountered biases.
4 To assess bias in a nonrandomized study following the target trial framework, use of the ROBINS-I tool is recommended ( https://www.bmj.com/content/355/bmj.i4919 ).
5 Only a selection of the most popular approaches is presented here. Other methods exist; e.g., g-computation and g-estimation for both time-invariant and time-varying analysis; instrumental variables; and doubly-robust estimation methods. There are also program evaluation methods (e.g., difference-in-differences, regression discontinuities) that can be applied to pharmacoepidemiologic questions. Conventional outcome regression analysis is not recommended for causal estimation due to issues determining covariate balance, correct model specification, and interpretability of effect estimates.
6 Online tools include, among others, an E-value calculator for unmeasured confounding ( https://www.evalue-calculator.com /) and the P95 outcome misclassification estimator ( http://apps.p-95.com/ISPE /).
3.2 Defining the Research question (step 1)
The process of designing a study begins with defining the research question. Research questions typically center on whether a causal relationship exists between an exposure and an outcome. This contrasts with associative questions, which, by their nature, do not require causal study design elements because they do not attempt to isolate a causal pathway from a single exposure to an outcome under study. It is important to note that the phrasing of the question itself should clarify whether an association or a causal relationship is of interest. The study question “Does statin use reduce the risk of future cardiovascular events?” is explicitly causal and requires that the study design addresses biases such as confounding. In contrast, the study question “Is statin use associated with a reduced risk of future cardiovascular events?” can be answered without control of confounding since the word “association” implies correlation. Too often, however, researchers use the word “association” to describe their findings when their methods were created to address explicitly causal questions (Hernán 2018 ). For example, a study that uses propensity score-based methods to balance risk factors between treatment groups is explicitly attempting to isolate a causal pathway by removing confounding factors. This is different from a study that intends only to measure an association. In fact, some journals may require that the word “association” be used when causal language would be more appropriate; however, this is beginning to change (Flanagin et al. 2024 ).
3.3 Defining the estimand (steps 2, 3, 4)
The estimand is the causal effect of research interest and is described in terms of required design elements: the target population for the counterfactual contrast, the kind of effect, and the effect/outcome measure.
In Step 2, the study team determines the target population of interest, which depends on the research question of interest. For example, we may want to estimate the effect of the treatment in the entire study population, i.e., the hypothetical contrast between all study patients taking the drug of interest versus all study patients taking the comparator (the average treatment effect; ATE). Other effects can be examined, including the average treatment effect in the treated or untreated (ATT or ATU).When covariate distributions are the same across the treated and untreated populations and there is no effect modification by covariates, these effects are generally the same (Wang et al. 2017 ). In RCTs, this occurs naturally due to randomization, but in non-randomized data, careful study design and statistical methods must be used to mitigate confounding bias.
In Step 3, the study team decides whether to measure the intention-to-treat (ITT), per-protocol, or as-treated effect. The ITT approach is also known as “first-treatment-carried-forward” in the observational literature (Lund et al. 2015 ). In trials, the ITT measures the effect of treatment assignment rather than the treatment itself, and in observational data the ITT can be conceptualized as measuring the effect of treatment as started . To compute the ITT effect from observational data, patients are placed into the exposure group corresponding to the treatment that they initiate, and treatment switching or discontinuation are purposely ignored in the analysis. Alternatively, a per-protocol effect can be measured from observational data by classifying patients according to the treatment that they initiated but censoring them when they stop, switch, or otherwise change treatment (Danaei et al. 2013 ; Yang et al. 2014 ). Finally, “as-treated” effects are estimated from observational data by classifying patients according to their actual treatment exposure during follow-up, for example by using multiple time windows to measure exposure changes (Danaei et al. 2013 ; Yang et al. 2014 ).
Step 4 is the final step in specifying the estimand in which the research team determines the effect measure of interest. Answering this question has two parts. First, the team must consider how the outcome of interest will be measured. Risks, rates, hazards, odds, and costs are common ways of measuring outcomes, but each measure may be best suited to a particular scenario. For example, risks assume patients across comparison groups have equal follow-up time, while rates allow for variable follow-up time (Rothman et al. 2008 ). Costs may be of interest in studies focused on economic outcomes, including as inputs to cost-effectiveness analyses. After deciding how the outcome will be measured, it is necessary to consider whether the resulting quantity will be compared across groups using a ratio or a difference. Ratios convey the effect of exposure in a way that is easy to understand, but they do not provide an estimate of how many patients will be affected. On the other hand, differences provide a clearer estimate of the potential public health impact of exposure; for example, by allowing the calculation of the number of patients that must be treated to cause or prevent one instance of the outcome of interest (Tripepi et al. 2007 ).
3.4 Identifying and mitigating biases (steps 5, 6, 7)
Observational, real-world studies can be subject to multiple potential sources of bias, which can be grouped into confounding, selection, measurement, and time-related biases (Prada-Ramallal et al. 2019 ).
In Step 5, as a practical first approach in developing strategies to address threats to causal inference, researchers should create a visual mapping of factors that may be related to the exposure, outcome, or both (also called a directed acyclic graph or DAG) (Pearl 1995 ). While creating a high-quality DAG can be challenging, guidance is increasingly available to facilitate the process (Ferguson et al. 2020 ; Gatto et al. 2022 ; Hernán and Robins 2020 ; Rodrigues et al. 2022 ; Sauer 2013 ). The types of inter-variable relationships depicted by DAGs include confounders, colliders, and mediators. Confounders are variables that affect both exposure and outcome, and it is necessary to control for them in order to isolate the causal pathway of interest. Colliders represent variables affected by two other variables, such as exposure and outcome (Griffith et al. 2020 ). Colliders should not be conditioned on since by doing so, the association between exposure and outcome will become distorted. Mediators are variables that are affected by the exposure and go on to affect the outcome. As such, mediators are on the causal pathway between exposure and outcome and should also not be conditioned on, otherwise a path between exposure and outcome will be closed and the total effect of the exposure on the outcome cannot be estimated. Mediation analysis is a separate type of analysis aiming to distinguish between direct and indirect (mediated) effects between exposure and outcome and may be applied in certain cases (Richiardi et al. 2013 ). Overall, the process of creating a DAG can create valuable insights about the nature of the hypothesized underlying data generating process and the biases that are likely to be encountered (Digitale et al. 2022 ). Finally, an extension to DAGs which incorporates counterfactual theory is available in the form of Single World Intervention Graphs (SWIGs) as described in a 2013 primer (Richardson and Robins 2013 ).
In Step 6, researchers comprehensively assess the possibility of different types of bias in their study, above and beyond what the creation of the DAG reveals. Many potential biases have been identified and summarized in the literature (Berger et al. 2017 ; Cox et al. 2009 ; European Medicines Agency 2023 ; Girman et al. 2014 ; Stuart et al. 2013 ; Velentgas et al. 2013 ). Every study can be subject to one or more biases, each of which can be addressed using one or more methods. The study team should thoroughly and explicitly identify all possible biases with consideration for the specifics of the available data and the nuances of the population and health care system(s) from which the data arise. Once the potential biases are identified and listed, the team can consider potential solutions using a variety of study design and analytic techniques.
In Step 7, the study team considers solutions to the biases identified in Step 6. “Target trial” thinking serves as the basis for many of these solutions by requiring researchers to consider how observational studies can be designed to ensure comparison groups are similar and produce valid inferences by emulating RCTs (Labrecque and Swanson 2017 ; Wang et al. 2023b ). Designing studies to include only new users of a drug and an active comparator group is one way of increasing the similarity of patients across both groups, particularly in terms of treatment history. Careful consideration must be paid to the specification of the time periods and their relationship to inclusion/exclusion criteria (Suissa and Dell’Aniello 2020 ). For instance, if a drug is used intermittently, a longer wash-out period is needed to ensure adequate capture of prior use in order to avoid bias (Riis et al. 2015 ). The study team should consider how to approach confounding adjustment, and whether both time-invariant and time-varying confounding may be present. Many potential biases exist, and many methods have been developed to address them in order to improve causal estimation from observational data. Many of these methods, such as propensity score estimation, can be enhanced by machine learning (Athey and Imbens 2019 ; Belthangady et al. 2021 ; Mai et al. 2022 ; Onasanya et al. 2024 ; Schuler and Rose 2017 ; Westreich et al. 2010 ). Machine learning has many potential applications in the causal inference discipline, and like other tools, must be used with careful planning and intentionality. To aid in the assessment of potential biases, especially time-related ones, and the development of a plan to address them, the study design should be visualized (Gatto et al. 2022 ; Schneeweiss et al. 2019 ). Additionally, we note the opportunity for collaboration across research disciplines (e.g., the application of difference-in-difference methods (Zhou et al. 2016 ) to the estimation of comparative drug effectiveness and safety).
3.5 Quality Control & sensitivity analyses (step 8)
Causal study design concludes with Step 8, which includes planning quality control and sensitivity analyses to improve the internal validity of the study. Quality control begins with reviewing study output for prima facie validity. Patient characteristics (e.g., distributions of age, sex, region) should align with expected values from the researchers’ intuition and the literature, and researchers should assess reasons for any discrepancies. Sensitivity analyses should be conducted to determine the robustness of study findings. Researchers can test the stability of study estimates using a different estimand or type of model than was used in the primary analysis. Sensitivity analysis estimates that are similar to those of the primary analysis might confirm that the primary analysis estimates are appropriate. The research team may be interested in how changes to study inclusion/exclusion criteria may affect study findings or wish to address uncertainties related to measuring the exposure or outcome in the administrative data by modifying the algorithms used to identify exposure or outcome (e.g., requiring hospitalization with a diagnosis code in a principal position rather than counting any claim with the diagnosis code in any position). As feasible, existing validation studies for the exposure and outcome should be referenced, or new validation efforts undertaken. The results of such validation studies can inform study estimates via quantitative bias analyses (Lanes and Beachler 2023 ). The study team may also consider biases arising from unmeasured confounding and plan quantitative bias analyses to explore how unmeasured confounding may impact estimates. Quantitative bias analysis can assess the directionality, magnitude, and uncertainty of errors arising from a variety of limitations (Brenner and Gefeller 1993 ; Lash et al. 2009 , 2014 ; Leahy et al. 2022 ).
3.6 Illustration using a previously published research study
In order to demonstrate how the guide can be used to plan a research study utilizing causal methods, we turn to a previously published study (Dondo et al. 2017 ) that assessed the causal relationship between the use of 𝛽-blockers and mortality after acute myocardial infarction in patients without heart failure or left ventricular systolic dysfunction. The investigators sought to answer a causal research question (Step 1), and so we proceed to Step 2. Use (or no use) of 𝛽-blockers was determined after discharge without taking into consideration discontinuation or future treatment changes (i.e., intention-to-treat). Considering treatment for whom (Step 3), both ATE and ATT were evaluated. Since survival was the primary outcome, an absolute difference in survival time was chosen as the effect measure (Step 4). While there was no explicit directed acyclic graph provided, the investigators specified a list of confounders.
Robust methodologies were established by consideration of possible sources of biases and addressing them using viable solutions (Steps 6 and 7). Table 1 offers a list of the identified potential biases and their corresponding solutions as implemented. For example, to minimize potential biases including prevalent-user bias and selection bias, the sample was restricted to patients with no previous use of 𝛽-blockers, no contraindication for 𝛽-blockers, and no prescription of loop diuretics. To improve balance across the comparator groups in terms of baseline confounders, i.e., those that could influence both exposure (𝛽-blocker use) and outcome (mortality), propensity score-based inverse probability of treatment weighting (IPTW) was employed. However, we noted that the baseline look-back period to assess measured covariates was not explicitly listed in the paper.
Quality control and sensitivity analysis (Step 8) is described extensively. The overlap of propensity score distributions between comparator groups was tested and confounder balance was assessed. Since observations in the tail-end of the propensity score distribution may violate the positivity assumption (Crump et al. 2009 ), a sensitivity analysis was conducted including only cases within 0.1 to 0.9 of the propensity score distribution. While not mentioned by the authors, the PS tails can be influenced by unmeasured confounders (Sturmer et al. 2021 ), and the findings were robust with and without trimming. An assessment of extreme IPTW weights, while not included, would further help increase confidence in the robustness of the analysis. An instrumental variable approach was employed to assess potential selection bias due to unmeasured confounding, using hospital rates of guideline-indicated prescribing as the instrument. Additionally, potential bias caused by missing data was attenuated through the use of multiple imputation, and separate models were built for complete cases only and imputed/complete cases.
4 Discussion
We have described a conceptual schema for designing observational real-world studies to estimate causal effects. The application of this schema to a previously published study illuminates the methodologic structure of the study, revealing how each structural element is related to a potential bias which it is meant to address. Real-world evidence is increasingly accepted by healthcare stakeholders, including the FDA (Concato and Corrigan-Curay 2022 ; Concato and ElZarrad 2022 ), and its use for comparative effectiveness and safety assessments requires appropriate causal study design; our guide is meant to facilitate this design process and complement existing, more specific, guidance.
Existing guidance for causal inference using observational data includes components that can be clearly mapped onto the schema that we have developed. For example, in 2009 Cox et al. described common sources of bias in observational data and recommended specific strategies to mitigate these biases, corresponding to steps 6–8 of our step-by-step guide (Cox et al. 2009 ). In 2013, the AHRQ emphasized development of the research question, corresponding to steps 1–4 of our guide, with additional chapters on study design, comparator selection, sensitivity analyses, and directed acyclic graphs which correspond to steps 7 and 5, respectively (Velentgas et al. 2013 ). Much of Girman et al.’s manuscript (Girman et al. 2014 ) corresponds with steps 1–4 of our guide, and the matter of equipoise and interpretability specifically correspond to steps 3 and 7–8. The current ENCePP guide on methodological standards in pharmacoepidemiology contains a section on formulating a meaningful research question, corresponding to step 1, and describes strategies to mitigate specific sources of bias, corresponding to steps 6–8 (European Medicines Agency 2023 ). Recent works by the FDA Sentinel Innovation Center (Desai et al. 2024 ) and the Joint Initiative for Causal Inference (Dang et al. 2023 ) provide more advanced exposition of many of the steps in our guide. The target trial framework contains guidance on developing seven components of the study protocol, including eligibility criteria, treatment strategies, assignment procedures, follow-up period, outcome, causal contrast of interest, and analysis plan (Hernán and Robins 2016 ). Our work places the target trial framework into a larger context illustrating its relationship with other important study planning considerations, including the creation of a directed acyclic graph and incorporation of prespecified sensitivity and quantitative bias analyses.
Ultimately, the feasibility of estimating causal effects relies on the capabilities of the available data. Real-world data sources are complex, and the investigator must carefully consider whether the data on hand are sufficient to answer the research question. For example, a study that relies solely on claims data for outcome ascertainment may suffer from outcome misclassification bias (Lanes and Beachler 2023 ). This bias can be addressed through medical record validation for a random subset of patients, followed by quantitative bias analysis (Lanes and Beachler 2023 ). If instead, the investigator wishes to apply a previously published, claims-based algorithm validated in a different database, they must carefully consider the transportability of that algorithm to their own study population. In this way, causal inference from real-world data requires the ability to think creatively and resourcefully about how various data sources and elements can be leveraged, with consideration for the strengths and limitations of each source. The heart of causal inference is in the pairing of humility and creativity: the humility to acknowledge what the data cannot do, and the creativity to address those limitations as best as one can at the time.
4.1 Limitations
As with any attempt to synthesize a broad array of information into a single, simplified schema, there are several limitations to our work. Space and useability constraints necessitated simplification of the complex source material and selections among many available methodologies, and information about the relative importance of each step is not currently included. Additionally, it is important to consider the context of our work. This step-by-step guide emphasizes analytic techniques (e.g., propensity scores) that are used most frequently within our own research environment and may not include less familiar study designs and analytic techniques. However, one strength of the guide is that additional designs and techniques or concepts can easily be incorporated into the existing schema. The benefit of a schema is that new information can be added and is more readily accessed due to its association with previously sorted information (Loveless 2022 ). It is also important to note that causal inference was approached as a broad overarching concept defined by the totality of the research, from start to finish, rather than focusing on a particular analytic technique, however we view this as a strength rather than a limitation.
Finally, the focus of this guide was on the methodologic aspects of study planning. As a result, we did not include steps for drafting or registering the study protocol in a public database or for communicating results. We strongly encourage researchers to register their study protocols and communicate their findings with transparency. A protocol template endorsed by ISPOR and ISPE for studies using real-world data to evaluate treatment effects is available (Wang et al. 2023a ). Additionally, the steps described above are intended to illustrate an order of thinking in the study planning process, and these steps are often iterative. The guide is not intended to reflect the order of study execution; specifically, quality control procedures and sensitivity analyses should also be formulated up-front at the protocol stage.
5 Conclusion
We outlined steps and described key conceptual issues of importance in designing real-world studies to answer causal questions, and created a visually appealing, user-friendly resource to help researchers clearly define and navigate these issues. We hope this guide serves to enhance the quality, and thus the impact, of real-world evidence.
Data availability
No datasets were generated or analysed during the current study.
Arlett, P., Kjaer, J., Broich, K., Cooke, E.: Real-world evidence in EU Medicines Regulation: Enabling Use and establishing value. Clin. Pharmacol. Ther. 111 (1), 21–23 (2022)
Article PubMed Google Scholar
Athey, S., Imbens, G.W.: Machine Learning Methods That Economists Should Know About. Annual Review of Economics 11(Volume 11, 2019): 685–725. (2019)
Belthangady, C., Stedden, W., Norgeot, B.: Minimizing bias in massive multi-arm observational studies with BCAUS: Balancing covariates automatically using supervision. BMC Med. Res. Methodol. 21 (1), 190 (2021)
Article PubMed PubMed Central Google Scholar
Berger, M.L., Sox, H., Willke, R.J., Brixner, D.L., Eichler, H.G., Goettsch, W., Madigan, D., Makady, A., Schneeweiss, S., Tarricone, R., Wang, S.V., Watkins, J.: and C. Daniel Mullins. 2017. Good practices for real-world data studies of treatment and/or comparative effectiveness: Recommendations from the joint ISPOR-ISPE Special Task Force on real-world evidence in health care decision making. Pharmacoepidemiol Drug Saf. 26 (9): 1033–1039
Brenner, H., Gefeller, O.: Use of the positive predictive value to correct for disease misclassification in epidemiologic studies. Am. J. Epidemiol. 138 (11), 1007–1015 (1993)
Article CAS PubMed Google Scholar
Concato, J., Corrigan-Curay, J.: Real-world evidence - where are we now? N Engl. J. Med. 386 (18), 1680–1682 (2022)
Concato, J., ElZarrad, M.: FDA Issues Draft Guidances on Real-World Evidence, Prepares to Publish More in Future [accessed on 2022]. (2022). https://www.fda.gov/drugs/news-events-human-drugs/fda-issues-draft-guidances-real-world-evidence-prepares-publish-more-future
Cox, E., Martin, B.C., Van Staa, T., Garbe, E., Siebert, U., Johnson, M.L.: Good research practices for comparative effectiveness research: Approaches to mitigate bias and confounding in the design of nonrandomized studies of treatment effects using secondary data sources: The International Society for Pharmacoeconomics and Outcomes Research Good Research Practices for Retrospective Database Analysis Task Force Report–Part II. Value Health. 12 (8), 1053–1061 (2009)
Crump, R.K., Hotz, V.J., Imbens, G.W., Mitnik, O.A.: Dealing with limited overlap in estimation of average treatment effects. Biometrika. 96 (1), 187–199 (2009)
Article Google Scholar
Danaei, G., Rodriguez, L.A., Cantero, O.F., Logan, R., Hernan, M.A.: Observational data for comparative effectiveness research: An emulation of randomised trials of statins and primary prevention of coronary heart disease. Stat. Methods Med. Res. 22 (1), 70–96 (2013)
Dang, L.E., Gruber, S., Lee, H., Dahabreh, I.J., Stuart, E.A., Williamson, B.D., Wyss, R., Diaz, I., Ghosh, D., Kiciman, E., Alemayehu, D., Hoffman, K.L., Vossen, C.Y., Huml, R.A., Ravn, H., Kvist, K., Pratley, R., Shih, M.C., Pennello, G., Martin, D., Waddy, S.P., Barr, C.E., Akacha, M., Buse, J.B., van der Laan, M., Petersen, M.: A causal roadmap for generating high-quality real-world evidence. J. Clin. Transl Sci. 7 (1), e212 (2023)
Desai, R.J., Wang, S.V., Sreedhara, S.K., Zabotka, L., Khosrow-Khavar, F., Nelson, J.C., Shi, X., Toh, S., Wyss, R., Patorno, E., Dutcher, S., Li, J., Lee, H., Ball, R., Dal Pan, G., Segal, J.B., Suissa, S., Rothman, K.J., Greenland, S., Hernan, M.A., Heagerty, P.J., Schneeweiss, S.: Process guide for inferential studies using healthcare data from routine clinical practice to evaluate causal effects of drugs (PRINCIPLED): Considerations from the FDA Sentinel Innovation Center. BMJ. 384 , e076460 (2024)
Digitale, J.C., Martin, J.N., Glymour, M.M.: Tutorial on directed acyclic graphs. J. Clin. Epidemiol. 142 , 264–267 (2022)
Dondo, T.B., Hall, M., West, R.M., Jernberg, T., Lindahl, B., Bueno, H., Danchin, N., Deanfield, J.E., Hemingway, H., Fox, K.A.A., Timmis, A.D., Gale, C.P.: beta-blockers and Mortality after Acute myocardial infarction in patients without heart failure or ventricular dysfunction. J. Am. Coll. Cardiol. 69 (22), 2710–2720 (2017)
Article CAS PubMed PubMed Central Google Scholar
European Medicines Agency: ENCePP Guide on Methodological Standards in Pharmacoepidemiology [accessed on 2023]. (2023). https://www.encepp.eu/standards_and_guidances/methodologicalGuide.shtml
Ferguson, K.D., McCann, M., Katikireddi, S.V., Thomson, H., Green, M.J., Smith, D.J., Lewsey, J.D.: Evidence synthesis for constructing directed acyclic graphs (ESC-DAGs): A novel and systematic method for building directed acyclic graphs. Int. J. Epidemiol. 49 (1), 322–329 (2020)
Flanagin, A., Lewis, R.J., Muth, C.C., Curfman, G.: What does the proposed causal inference Framework for Observational studies Mean for JAMA and the JAMA Network Journals? JAMA (2024)
U.S. Food and Drug Administration: Framework for FDA’s Real-World Evidence Program [accessed on 2018]. (2018). https://www.fda.gov/media/120060/download
Franklin, J.M., Schneeweiss, S.: When and how can Real World Data analyses substitute for randomized controlled trials? Clin. Pharmacol. Ther. 102 (6), 924–933 (2017)
Gatto, N.M., Wang, S.V., Murk, W., Mattox, P., Brookhart, M.A., Bate, A., Schneeweiss, S., Rassen, J.A.: Visualizations throughout pharmacoepidemiology study planning, implementation, and reporting. Pharmacoepidemiol Drug Saf. 31 (11), 1140–1152 (2022)
Girman, C.J., Faries, D., Ryan, P., Rotelli, M., Belger, M., Binkowitz, B., O’Neill, R.: and C. E. R. S. W. G. Drug Information Association. 2014. Pre-study feasibility and identifying sensitivity analyses for protocol pre-specification in comparative effectiveness research. J. Comp. Eff. Res. 3 (3): 259–270
Griffith, G.J., Morris, T.T., Tudball, M.J., Herbert, A., Mancano, G., Pike, L., Sharp, G.C., Sterne, J., Palmer, T.M., Davey Smith, G., Tilling, K., Zuccolo, L., Davies, N.M., Hemani, G.: Collider bias undermines our understanding of COVID-19 disease risk and severity. Nat. Commun. 11 (1), 5749 (2020)
Hernán, M.A.: The C-Word: Scientific euphemisms do not improve causal inference from Observational Data. Am. J. Public Health. 108 (5), 616–619 (2018)
Hernán, M.A., Robins, J.M.: Using Big Data to emulate a target Trial when a Randomized Trial is not available. Am. J. Epidemiol. 183 (8), 758–764 (2016)
Hernán, M., Robins, J.: Causal Inference: What if. Chapman & Hall/CRC, Boca Raton (2020)
Google Scholar
International Society for Pharmacoeconomics and Outcomes Research (ISPOR): Strategic Initiatives: Real-World Evidence [accessed on 2022]. (2022). https://www.ispor.org/strategic-initiatives/real-world-evidence
International Society for Pharmacoepidemiology (ISPE): Position on Real-World Evidence [accessed on 2020]. (2020). https://pharmacoepi.org/pub/?id=136DECF1-C559-BA4F-92C4-CF6E3ED16BB6
Labrecque, J.A., Swanson, S.A.: Target trial emulation: Teaching epidemiology and beyond. Eur. J. Epidemiol. 32 (6), 473–475 (2017)
Lanes, S., Beachler, D.C.: Validation to correct for outcome misclassification bias. Pharmacoepidemiol Drug Saf. (2023)
Lash, T.L., Fox, M.P., Fink, A.K.: Applying Quantitative bias Analysis to Epidemiologic data. Springer (2009)
Lash, T.L., Fox, M.P., MacLehose, R.F., Maldonado, G., McCandless, L.C., Greenland, S.: Good practices for quantitative bias analysis. Int. J. Epidemiol. 43 (6), 1969–1985 (2014)
Leahy, T.P., Kent, S., Sammon, C., Groenwold, R.H., Grieve, R., Ramagopalan, S., Gomes, M.: Unmeasured confounding in nonrandomized studies: Quantitative bias analysis in health technology assessment. J. Comp. Eff. Res. 11 (12), 851–859 (2022)
Loveless, B.: A Complete Guide to Schema Theory and its Role in Education [accessed on 2022]. (2022). https://www.educationcorner.com/schema-theory/
Lund, J.L., Richardson, D.B., Sturmer, T.: The active comparator, new user study design in pharmacoepidemiology: Historical foundations and contemporary application. Curr. Epidemiol. Rep. 2 (4), 221–228 (2015)
Mai, X., Teng, C., Gao, Y., Governor, S., He, X., Kalloo, G., Hoffman, S., Mbiydzenyuy, D., Beachler, D.: A pragmatic comparison of logistic regression versus machine learning methods for propensity score estimation. Supplement: Abstracts of the 38th International Conference on Pharmacoepidemiology: Advancing Pharmacoepidemiology and Real-World Evidence for the Global Community, August 26–28, 2022, Copenhagen, Denmark. Pharmacoepidemiology and Drug Safety 31(S2). (2022)
Mullard, A.: 2021 FDA approvals. Nat. Rev. Drug Discov. 21 (2), 83–88 (2022)
Onasanya, O., Hoffman, S., Harris, K., Dixon, R., Grabner, M.: Current applications of machine learning for causal inference in healthcare research using observational data. International Society for Pharmacoeconomics and Outcomes Research (ISPOR) Atlanta, GA. (2024)
Pearl, J.: Causal diagrams for empirical research. Biometrika. 82 (4), 669–688 (1995)
Prada-Ramallal, G., Takkouche, B., Figueiras, A.: Bias in pharmacoepidemiologic studies using secondary health care databases: A scoping review. BMC Med. Res. Methodol. 19 (1), 53 (2019)
Richardson, T.S., Robins, J.M.: Single World Intervention Graphs: A Primer [accessed on 2013]. (2013). https://www.stats.ox.ac.uk/~evans/uai13/Richardson.pdf
Richiardi, L., Bellocco, R., Zugna, D.: Mediation analysis in epidemiology: Methods, interpretation and bias. Int. J. Epidemiol. 42 (5), 1511–1519 (2013)
Riis, A.H., Johansen, M.B., Jacobsen, J.B., Brookhart, M.A., Sturmer, T., Stovring, H.: Short look-back periods in pharmacoepidemiologic studies of new users of antibiotics and asthma medications introduce severe misclassification. Pharmacoepidemiol Drug Saf. 24 (5), 478–485 (2015)
Rodrigues, D., Kreif, N., Lawrence-Jones, A., Barahona, M., Mayer, E.: Reflection on modern methods: Constructing directed acyclic graphs (DAGs) with domain experts for health services research. Int. J. Epidemiol. 51 (4), 1339–1348 (2022)
Rothman, K.J., Greenland, S., Lash, T.L.: Modern Epidemiology. Wolters Kluwer Health/Lippincott Williams & Wilkins, Philadelphia (2008)
Rubin, D.B.: Causal inference using potential outcomes. J. Am. Stat. Assoc. 100 (469), 322–331 (2005)
Article CAS Google Scholar
Sauer, B.V.: TJ. Use of Directed Acyclic Graphs. In Developing a Protocol for Observational Comparative Effectiveness Research: A User’s Guide , edited by P. Velentgas, N. Dreyer, and P. Nourjah: Agency for Healthcare Research and Quality (US) (2013)
Schneeweiss, S., Rassen, J.A., Brown, J.S., Rothman, K.J., Happe, L., Arlett, P., Dal Pan, G., Goettsch, W., Murk, W., Wang, S.V.: Graphical depiction of longitudinal study designs in Health Care databases. Ann. Intern. Med. 170 (6), 398–406 (2019)
Schuler, M.S., Rose, S.: Targeted maximum likelihood estimation for causal inference in Observational studies. Am. J. Epidemiol. 185 (1), 65–73 (2017)
Stuart, E.A., DuGoff, E., Abrams, M., Salkever, D., Steinwachs, D.: Estimating causal effects in observational studies using Electronic Health data: Challenges and (some) solutions. EGEMS (Wash DC) 1 (3). (2013)
Sturmer, T., Webster-Clark, M., Lund, J.L., Wyss, R., Ellis, A.R., Lunt, M., Rothman, K.J., Glynn, R.J.: Propensity score weighting and trimming strategies for reducing Variance and Bias of Treatment Effect estimates: A Simulation Study. Am. J. Epidemiol. 190 (8), 1659–1670 (2021)
Suissa, S., Dell’Aniello, S.: Time-related biases in pharmacoepidemiology. Pharmacoepidemiol Drug Saf. 29 (9), 1101–1110 (2020)
Tripepi, G., Jager, K.J., Dekker, F.W., Wanner, C., Zoccali, C.: Measures of effect: Relative risks, odds ratios, risk difference, and ‘number needed to treat’. Kidney Int. 72 (7), 789–791 (2007)
Velentgas, P., Dreyer, N., Nourjah, P., Smith, S., Torchia, M.: Developing a Protocol for Observational Comparative Effectiveness Research: A User’s Guide. Agency for Healthcare Research and Quality (AHRQ) Publication 12(13). (2013)
Wang, A., Nianogo, R.A., Arah, O.A.: G-computation of average treatment effects on the treated and the untreated. BMC Med. Res. Methodol. 17 (1), 3 (2017)
Wang, S.V., Pottegard, A., Crown, W., Arlett, P., Ashcroft, D.M., Benchimol, E.I., Berger, M.L., Crane, G., Goettsch, W., Hua, W., Kabadi, S., Kern, D.M., Kurz, X., Langan, S., Nonaka, T., Orsini, L., Perez-Gutthann, S., Pinheiro, S., Pratt, N., Schneeweiss, S., Toussi, M., Williams, R.J.: HARmonized Protocol Template to enhance reproducibility of hypothesis evaluating real-world evidence studies on treatment effects: A good practices report of a joint ISPE/ISPOR task force. Pharmacoepidemiol Drug Saf. 32 (1), 44–55 (2023a)
Wang, S.V., Schneeweiss, S., Initiative, R.-D., Franklin, J.M., Desai, R.J., Feldman, W., Garry, E.M., Glynn, R.J., Lin, K.J., Paik, J., Patorno, E., Suissa, S., D’Andrea, E., Jawaid, D., Lee, H., Pawar, A., Sreedhara, S.K., Tesfaye, H., Bessette, L.G., Zabotka, L., Lee, S.B., Gautam, N., York, C., Zakoul, H., Concato, J., Martin, D., Paraoan, D.: and K. Quinto. Emulation of Randomized Clinical Trials With Nonrandomized Database Analyses: Results of 32 Clinical Trials. JAMA 329(16): 1376-85. (2023b)
Westreich, D., Lessler, J., Funk, M.J.: Propensity score estimation: Neural networks, support vector machines, decision trees (CART), and meta-classifiers as alternatives to logistic regression. J. Clin. Epidemiol. 63 (8), 826–833 (2010)
Yang, S., Eaton, C.B., Lu, J., Lapane, K.L.: Application of marginal structural models in pharmacoepidemiologic studies: A systematic review. Pharmacoepidemiol Drug Saf. 23 (6), 560–571 (2014)
Zhou, H., Taber, C., Arcona, S., Li, Y.: Difference-in-differences method in comparative Effectiveness Research: Utility with unbalanced groups. Appl. Health Econ. Health Policy. 14 (4), 419–429 (2016)
Download references
The authors received no financial support for this research.
Author information
Authors and affiliations.
Carelon Research, Wilmington, DE, USA
Sarah Ruth Hoffman, Nilesh Gangan, Joseph L. Smith, Arlene Tave, Yiling Yang, Christopher L. Crowe & Michael Grabner
Elevance Health, Indianapolis, IN, USA
Xiaoxue Chen
University of Maryland School of Pharmacy, Baltimore, MD, USA
Susan dosReis
You can also search for this author in PubMed Google Scholar
Contributions
SH, NG, JS, AT, CC, MG are employees of Carelon Research, a wholly owned subsidiary of Elevance Health, which conducts health outcomes research with both internal and external funding, including a variety of private and public entities. XC was an employee of Elevance Health at the time of study conduct. YY was an employee of Carelon Research at the time of study conduct. SH, MG, and JLS are shareholders of Elevance Health. SdR receives funding from GlaxoSmithKline for a project unrelated to the content of this manuscript and conducts research that is funded by state and federal agencies.
Corresponding author
Correspondence to Sarah Ruth Hoffman .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary material 2, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Hoffman, S.R., Gangan, N., Chen, X. et al. A step-by-step guide to causal study design using real-world data. Health Serv Outcomes Res Method (2024). https://doi.org/10.1007/s10742-024-00333-6
Download citation
Received : 07 December 2023
Revised : 31 May 2024
Accepted : 10 June 2024
Published : 19 June 2024
DOI : https://doi.org/10.1007/s10742-024-00333-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Causal inference
- Real-world data
- Confounding
- Non-randomized data
- Bias in pharmacoepidemiology
- Find a journal
- Publish with us
- Track your research

May 5-8, 2024
- Past Conferences
Validating the Utility of Synthetic Data Generation for Clinical Research
Wilson A 1 , Krikov S 2 , Crockett D 3 1 Parexel International, Waltham, MA, USA, 2 Parexel International, Lexington, MA, USA, 3 Intermountain Health, Salt Lake City, UT, USA
Presentation Documents
- ISPOR US Poster 2024 Synthetic Data RWD39 v.1.0139780.pdf
OBJECTIVES: Clinical research often requires collaboration and data sharing. Collaborative research can speed up research and improve findings, but using sensitive data like patient info raises privacy concerns. These challenges can negate any potential time savings and, in fact, be entirely prohibitive. One emerging solution to data sharing comes from the emerging field of synthetic data generation (SDG).
METHODS: In this study, we established an evaluation framework to assess synthetic data quality by comparing target causal effect estimates across different estimation methods. Successful synthetic data was defined as preserving both effect relationships and confounding structures necessary for accurate causal inference.
RESULTS: The results {illustrated in Figure 2} indicate that advanced SDG methods are successful in obtaining accurate causal estimates and maintaining confounding structures in a kidney disease progression case study.
CONCLUSIONS: Synthetic data offers a pragmatic balance between data utility and privacy protection. It also enables broader data accessibility and collaboration while allowing for the inclusion of rare or underrepresented conditions in research, enhancing the scope and depth of studies.
Methodological & Statistical Research, Real World Data & Information Systems
Topic Subcategory
Data Protection, Integrity, & Quality Assurance
No Additional Disease & Conditions/Specialized Treatment Areas, Urinary/Kidney Disorders
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 24 June 2024
Transfer learned deep feature based crack detection using support vector machine: a comparative study
- K. S. Bhalaji Kharthik 1 ,
- Edeh Michael Onyema ORCID: orcid.org/0000-0002-4067-3256 2 , 3 ,
- Saurav Mallik ORCID: orcid.org/0000-0003-4107-6784 4 ,
- B. V. V. Siva Prasad ORCID: orcid.org/0000-0001-8650-3984 5 ,
- Hong Qin 6 ,
- C. Selvi 7 &
- O. K. Sikha 1 , 8
Scientific Reports volume 14 , Article number: 14517 ( 2024 ) Cite this article
Metrics details
- Engineering
- Environmental sciences
- Mathematics and computing
Technology offers a lot of potential that is being used to improve the integrity and efficiency of infrastructures. Crack is one of the major concerns that can affect the integrity or usability of any structure. Oftentimes, the use of manual inspection methods leads to delays which can worsen the situation. Automated crack detection has become very necessary for efficient management and inspection of critical infrastructures. Previous research in crack detection employed classification and localization-based models using Deep Convolutional Neural Networks (DCNNs). This study suggests and compares the effectiveness of transfer learned DCNNs for crack detection as a classification model and as a feature extractor to overcome this restriction. The main objective of this paper is to present various methods of crack detection on surfaces and compare their performance over 3 different datasets. Experiments conducted in this work are threefold: initially, the effectiveness of 12 transfer learned DCNN models for crack detection is analyzed on three publicly available datasets: SDNET, CCIC and BSD. With an accuracy of 53.40%, ResNet101 outperformed other models on the SDNET dataset. EfficientNetB0 was the most accurate (98.8%) model on the BSD dataset, and ResNet50 performed better with an accuracy of 99.8% on the CCIC dataset. Secondly, two image enhancement methods are employed to enhance the images and are transferred learned on the 12 DCNNs in pursuance of improving the performance of the SDNET dataset. The results from the experiments show that the enhanced images improved the accuracy of transfer-learned crack detection models significantly. Furthermore, deep features extracted from the last fully connected layer of the DCNNs are used to train the Support Vector Machine (SVM). The integration of deep features with SVM enhanced the detection accuracy across all the DCNN-dataset combinations, according to analysis in terms of accuracy, precision, recall, and F1-score.
Introduction
Cracks in concrete structures, resulting from factors like rust, chemical degradation, and unfavorable loading, serve as warning signs for tension, fragility, and wear. The length, width, depth, and position of these cracks impact their significance 1 . To ensure the long-term serviceability of infrastructures, monitoring structural health and performance is crucial 2 . Traditional manual inspection methods relying on eyesight are time-consuming, labor-intensive, and prone to subjective conclusions. The high cost of labor and potential human error makes frequent manual inspections impractical. Efficiently identifying surface cracks within a specific timeframe is crucial for enhancing the maintenance protocols of buildings. This swift detection allows for timely interventions, preventing the deterioration of structural issues and minimizing repair costs. By promptly addressing these cracks, potential safety hazards can be mitigated, ensuring the longevity and structural integrity of the building. Recent advancements in science and technology have led to the development of automatic crack detection models, employing image processing and machine learning (ML) techniques 3 , 4 , 5 , 6 .
Image processing-based techniques use statistical features from structural images to detect and locate cracks, treating them as regions with sudden pixel intensity changes. Machine Learning (ML)-based models utilize hand-crafted features, such as edge, texture, and color, for automatic crack detection 7 , 8 . With the availability of massive datasets, researchers have turned to Deep Learning (DL), particularly Convolutional Neural Networks (CNN), for more effective crack detection. The success of DL-based models, especially neural networks with multiple layers, has significantly improved feature learning. CNNs, with varied filters highlighting crucial features, extract basic image features in initial layers and advanced, crack-specific features in deeper layers. These features are then passed to a multi-layer perceptron classifier for crack detection. The accessibility of powerful computing resources and continuous advancements in training techniques on readily available datasets propel the rapid development of deep learning. Despite the success in feature extraction, there’s a need to enhance the accuracy of these models in detecting concrete cracks.
In this research, we put forth a method of transfer learning-based deep convolutional neural networks (DCNN) with the pre-trained weights as a classifier and feature extractor, which exhibits a considerable increase in terms of performance, unavailability of large dataset and training time. This paper also investigates the impact of ML classifiers learned over deep features for crack detection. Three publicly available datasets were used for the study SDNET2018 9 , Concrete Crack Images for Classification (CCIC) 10 , and Bridge Crack Dataset (BCD) 11 . Experiments conducted in this work are threefold (1) Crack detection based on transfer learned deep CNNs: 12 state-of-the-art CNN models transfer learned on ImageNet were used to classify the crack images (2) Crack detection using transfer learned CNNs on enhanced crack images (3) Examining DCNN’s performance as a feature extractor.
The obtained features from deep CNNs’ fully connected layers (final FC layers) are classified and compared using ML algorithms. The major contributions of the proposed work are:
Classification of crack images using 12 transfer-learned DCNNs including VGG16, VGG19, Xception, ResNet50, ResNet101, ResNet152, InceptionV3, InceptionResNetV2, MobileNet, MobileNetV2, DenseNet121 and EfficientNetB0.
Analysis of the effectiveness of image enhancement techniques such as contrast enhancement and Local Binary Pattern (LBP) pre-processing on transfer learned DCNN models for crack detection.
Development of Support Vector Machine (SVM)-ML-based classification model on deep features extracted from the aforementioned DCNN models.
The following is how the paper is organized: The related crack detection research is covered in Section “ Literature review ” of this paper. The proposed system and the experiments carried out to categorize the images are described in Section “ Proposed Methodology ”. A description of the various datasets used is provided in Section “ Dataset ”. The outcomes and conclusions of the experiment are described in Section “ Experimental Result and Analysis ”. The paper is concluded in Section “ Conclusion and Future Scope ”.
Literature review
A thorough description of the most recent crack detection models is provided in this section. Crack detection models found in the literature can be divided into three major categories based on their workflow: (1) Models based on traditional image processing algorithms (2) Models based on machine learning models (3) Models based on deep learning models.
Classical image processing-based models
Crack detection using image processing methods have three major steps: image acquisition, pre-processing, and crack detection 12 . The target component is first photographed in high quality with a camera or any other imaging instrument. The next step in the pre-processing is to eliminate noise and shadows from the images by applying filters, segmentation, and other techniques. If necessary for the particular crack detection technique being used, the image may be transformed to gray-scale or binary format. The generated image is then put through crack detection, which emphasizes or segments the image’s cracked area using image processing techniques like edge detection, segmentation, or pixel analysis. 13 . Lins et al. 14 , developed a method to identify cracks using several color models like HSV (Hue-Saturation-Value) and RGB (Red–Green–Blue). They proposed a color feature extraction model, which searches for certain color compositions in an image in comparison to a standard query color. Further, the authors have used their crack measurement algorithm to measure the length and width of the detected cracks. Shahrokhinasab et al. 15 , analyzed various image processing methods like edge detection, and thresholding, to classify cracks. Munawar et al. 16 , analyzed different methods of fissure detection including genetic programming, beamlet transformation, Unmanned Aerial System based approach, and the Shi Tomasi algorithm. Zou et al. 17 , introduced an automated crack detection system titled as CrackTree which uses a geodesic shadow removal algorithm to eliminate shadows from pavement images.
A crack probability map is produced using tensor voting, and a graph model is built by choosing crack seeds from the crack probability map. Recursive edge pruning in the graph’s Minimum Spanning Tree (MST) is used to find the final crack curves. Gabor Filters were employed by Salman et al. 18 , for crack detection. Niu et al. 19 , introduced a method to find cracks in tunnels that involve a series of image processing, image filtering, and image feature extraction methods. They have used uniform light processing for the crack to appear better, used median and bilateral filtering to filter out the noise, and used a combination of Gabor filter and EMAP to extract required features. The features were then fed into the CEM algorithm to detect the cracks. Oliviera et al. 20 , used a group of pixel-based and block-based image processing algorithms. The image processing techniques used were anisotropic diffusion, Perona and Malik’s algorithm, morphological smoothening, alternative sequential filtering, a combination of morphological erosion and dilation operators, Symlet decomposition filters, and UINTA and R- UINTA. Baltazart et al. 21 , presented an improved version of the Minimum Spanning Tree algorithm to identify cracks called the MPS– VI and analyzed the computational time of each model. An ACDS architecture was proposed by Jo et al. 22 , which had an image acquisition block, a pre-processing block and the classification block. In the pre-processing block, they used the Hessian-based method, Gabor filter, Otsu, Retinex filter, and Median filter to extract features and use these features to train and classify the deep belief network. Classical image processing-based models for crack detection depend on the quality of images.
Machine learning-based models
ML-based models for crack detection follow five steps: dataset collection, pre-processing of images, feature extraction, model training on the extracted features, and testing. Landstrom and Thurley 23 employed morphological operators to slice the cracks from the image and logistic regression is used to distinguish the crack/non-crack images using the segmented images. Prasanna et al. 24 , put forth a crack detection method called spatially tuned robust multi-feature (STRUM), in which the authors have explored classifiers including SVM, AdaBoost, and Random Forest. Lin et al. 25 , used hidden Markov random field-expectation–maximization (HMRF–EM) for automatic pavement crack detection, with 2 major modules. Firstly, the hidden Markov random field model and its expectation–maximization are combined with the adaptive line detector to increase detecting accuracy. Secondly, the integrity and continuity of the detected cracks are improved by the quantitative description of the crack region’s credibility and conditional connection. FG Pratico et al. 26 , provided a method for classifying the structural health condition of several vibro-acoustically different road pavement cracks (concealed bottom-up cracks) using supervised machine learning techniques. The technique intends to gather the signatures (using roadside acoustic sensors) and categorize the structural health status of the pavement using ML models. They compared various ML classifiers, including the random forest classifier (RFC), support vector classifier (SVC) and multi-layer perceptron (MLP). Results indicate the SVC is the best-performing ML model with an accuracy of 99.1%. Zhang et al. 27 , suggested a new method for identifying surface fractures in coal mining sites using Unmanned Aerial Vehicle(UAV) imagery and ML.
The overall accuracy was increased to 88.99% by applying the V-SVM classifier. The authors also used Laplace sharpening to improve the color of the images and Principal Component Analysis (PCA) to minimize the entire set of features to 95% of the initial variance. A ML-computer vision pipeline was proposed by Zhang et al. 28 for detecting the formation of fatigue cracks. Cracks were detected using an ML model, and vision-based algorithms were further utilized to examine the growth direction and length of the fatigue crack. The primary problem with ML-based models for crack detection is the selection and extraction of relevant features for the classifier’s training.
Deep learning-based models
Numerous crack detection models have been developed in the literature as a result of recent developments in deep learning (DL), particularly the evolution of convolutional neural networks (CNNs) 29 . DL-based models for crack detection follow steps analogous to ML-based models described above. The major difference is that DL models do feature extraction implicitly. A dataset of surface cracks must be gathered first to train the DL model. To minimize noise, eliminate shadows, and modify other features like image size and brightness, the images are then pre-processed using image processing techniques. These images are then subjected to pixel-by-pixel annotation, or labeling, where the pixels corresponding to cracks are annotated either manually or by using annotation tools. One example of labeling is making the remaining pixels in the image black or “0” and the crack pixels white or “1” in the image. Following this, a DL architecture CNNS must be chosen to be applied to crack detection. Li et al. 30 , proposed a deep neural architecture with a convolutional block, four dense connections, five deep supervision modules, three conversion modules and one fusion module to identify cracked surfaces. Zhang et al. 31 , introduced a CNN architecture with four convolutional layers and two fully connected layers. Their convolution network achieved a precision of 0.869 and a recall of 0.925 for crack detection. Meng et al. 32 , proposed a deep residual neural network-based concrete crack identification method that identified concrete crack images at the pixel level. Transfer learned EfficientNetB0 was employed by C.Su and W. Wang 33 for crack detection. They reported an accuracy better than that of a fully convolutional network proposed by Ye et al. 34 , which gave an accuracy of 93.6%. Feng et al. 35 , used transfer learning on the InceptionV3 model to classify cracks which included crack, intact, spalling, seepage and rebar exposure as the classes. A custom convolutional neural network with three convolutional layers was introduced by Kim et al. 36 for crack detection. The images were pre-processed using morphological filters and contrast enhancement operators, which in turn were used to train the CNN model for the identification of cracks. Cao et al. 37 , used object-detecting paradigms such as faster RCNN and SSD models along with MobileNet, Inception, Resnet, and Inception Resnet to detect road cracks. They used mAP(mean average precision) as the performance metric to test the combinations of Object detecting paradigms and DCNNs. Among all the combinations, Faster RCNN paired with Inception V2 gave the best results with mAP at 53.06%. A two-stage detection model including a DCNN and a segmentation module was proposed by NHT Nguyen et al. 38 . The authors proved that the segmentation of cracks at the pixel level improves detection accuracy significantly. In a study presented by SE Park et al. 39 , cracks on concrete structure surfaces have been identified using DL and structured light technologies, which combine two laser sensors with vision.
The YOLO model was used to identify the cracks and the size of all cracks were calculated using the positions of the laser beams on the structural surface. Huyan et al. 40 , presented a model named CrackU-net which detects pavement cracks with a precision of 0.986. Kim et al. 41 , proposed a crack detection technique using shallow CNN architecture. They optimized the LeNet-5 model’s hyper-parameters to obtain maximum accuracy of 99.8% with fewer parameters. Even though some of these models performed pretty well in feature extraction and classification on various applications, their accuracy needs to be increased to detect concrete fractures. In this paper, we are evaluating the effectiveness of transfer-learned deep features for crack detection using raw and enhanced crack images, which shows a significant boost in terms of performance.
Proposed methodology
This section introduces DCNNs and their application for crack detection in detail.DCNNs, which were first developed in the 1980s, is the most well-known, advanced, and popular DL algorithm 42 . Earlier the researchers were not drawn to DCNNs due to the availability of minimum computational resources, powerful processors, and huge storage devices. But when computers’ processing capacity for computing, database retrieval, and storage expanded, the idea gained popularity 43 . Later in 44 , CNN’s were successfully applied in classification problems and outperformed mostly in solving computer vision problems. Figure 1 depicts a typical CNN structure. The initial layers of DCNN extract basic image features such as edges, patterns, and textures. The middle layers extract object-level information like shape and color, whereas the deeper levels extract class-level features like the whole object. The feature extraction layer’s final output is passed into either a fully connected neural network 45 for classification or a bounding box and pixel classification layer for segmentation.

CNN Architecture.
CNN has emerged as the most widely used and successful DL architecture for various input data types including images, videos and texts, with several cutting-edge architectures reported in the literature. VGG16, VGG19 46 , Xception 47 , ResNet50, ResNet101, ResNet152 48 , InceptionV3 49 , InceptionResNetV2 50 , MobileNet 51 , MobileNetV2 52 , DenseNet121 53 , EfficientNetB0 54 are some of the well-known and leading-edge DCNN architectures for classification. DCNN varieties for classification, segmentation, or localization can be used to detect cracks in the input image.
This paper proposes transfer learning-based DL models for crack identification through classification. This work carried out three experiments: (1) Transfer Learning for Crack Detection Without Image Enhancement (2) Transfer Learning for Crack Detection with Image Enhancement (3) Crack detection using SVM on deep features. Figure 2 depicts the experiments carried out in the proposed model.

Proposed Transfer Learning Architecture for Crack Detection with Pre-trained CNN Models on ImageNet Weights.
Transfer learning for crack detection without image enhancement
A model created for one job is utilized as the basis for another task in transfer learning, a machine learning technique 55 , 56 , 57 . The use of pre-trained models as the foundation for computer vision and natural language processing tasks is a common strategy in DL research due to the massive computing time and resources required to develop neural network models 58 . The benefits of using a transfer learned model over an end-to-end neural network include significant time and computation savings. Recent research reveals that transfer-learned models outperform traditional neural networks and can work with smaller amounts of data. Generally, for computer vision applications, the features extracted by the first and middle layers of a neural network are similar for similar inputs. The latter layers that extract high-level features make the difference. The proposed model freezes the first and middle layers and makes the final layers trainable. We retain the weights from the old model trained on a comparatively large dataset and only train a few parameters.
Figure 3 illustrates the process of transfer learning applied to a Deep Convolutional Neural Network (DCNN) using pre-trained ImageNet weights. In this experiment, we adapted the DCNN model for crack detection by leveraging the weights learned from the ImageNet dataset.

Transfer Learning Pipeline used in the proposed model.
To accomplish this, we first removed the final layers of the pre-trained models. These layers were then replaced with a new architecture consisting of several components: a flattened layer to convert the 2D feature maps into a 1D feature vector, a batch normalization layer to stabilize and accelerate the training process, a dropout layer to prevent overfitting by randomly setting a fraction of input units to zero during training, and a dense layer with two neurons, each using a sigmoid activation function to output the probability of the presence or absence of cracks.
Before training the model, the necessary datasets were collected. These datasets were then preprocessed by resizing the images to 224 × 224 pixels, a standard input size for many CNN architectures pre-trained on ImageNet. The resized dataset was subsequently split into three subsets: training, validation, and test sets. This division ensures that the model can be trained, validated, and tested on separate data to evaluate its performance accurately.After preparing the data, we loaded it into the pre-trained CNN model. As mentioned earlier, the model’s original final layers were replaced with a new set of custom layers. This new architecture was specifically designed to refine the pre-trained model’s capacity to detect cracks in images.
The transfer learning model was then trained, but with a specific focus on optimizing only a subset of parameters. Specifically, most parameters from the pre-trained layers were frozen, meaning they were not updated during training. Only the parameters from the newly added custom layers were fine-tuned. This approach allows the model to retain the general features learned from the ImageNet dataset while adapting its final layers to the specific task of crack detection with a smaller amount of data and computational resources.
Transfer learning for crack detection with image enhancement
Two image enhancement methods: Local Binary Pattern and contrast enhancement were employed to pre-process the input image to train the DCNN models. Image enhancement modules were introduced with the assumption that when trained on enhanced input images, Convnets would easily converge, lowering computational costs and improving accuracy. The assumption was supported further by various benchmark evaluation metrics, as shown in the following sections. The selection of image enhancement algorithms was done based on the literature as proposed by Wang et al. 59 , and Chen et al. 60 .
Contrast enhancement
Contrast enhancement in the image makes dark areas darker and light areas lighter, making cracks appear darker than other surfaces. This creates a significant difference between the dark and light areas, which will aid in subsequent classification 59 .
Algorithm 1 details the steps followed for contrast enhancement and Fig. 4 shows the results of contrast enhancement on crack images selected randomly from the dataset. Figure plots the histograms corresponding to the original images and the contrast-enhanced images. From the figure, it is evident that the histograms of original crack images are not uniform (skewed towards the right) whereas that of enhanced images are uniform.

Contrast enhancement on the crack images. ( a ) Original image ( b ) Histograms of original images ( c ) Contrast-enhanced image ( d ) Histograms of Contrast-enhanced image.
Local binary pattern (LBP)
LBP is a primitive texture operator that labels pixels in an image by thresholding each pixel’s vicinity based on the current pixel 61 . It is considered an efficient descriptor due to its resistance to changes in illumination, computational simplicity, and reliability in image classification. The LBP Algorithm divides the image into smaller cells and uses the intensity of the center pixel as a threshold for the remaining pixels in the cell. When neighboring pixels are greater than the threshold value, they are thresholded to 1; otherwise, they are thresholded to 0. The binary number is generated by circularly visiting the matrix. As a result, the formed binary number is converted to a decimal and used to update the value of the center pixel.
Algorithm 1: Contrast Enhancement Algorithm | |
1 | Take an input image, brightness value and contrast value |
2 | Check if brightness is equal to 0, if yes go to step 3 else go to step 5 |
3 | If the brightness value is greater than 0 then assign brightness value to shadow and highlight to 255, else assign shadow to 0 and highlight to 255 + brightness value. Calculate the and values using the highlight and shadow values using the below formulas = = |
4 | Using , and as inputs blend the images using add weighted function |
5 | Create an extra copy of the image |
6 | Check if the contrast value is not 0, if yes assign the variables and using the below formulas = 131*(contrast + 127) / (127*(131 – contrast)) gamma_c = 127*(1 – alpha_c) |
7 | Using , and as inputs blend the images using add weighted function |
Algorithm 2: Local Binary Pattern (LBP) | |
1 | Take a center pixel from the given image |
2 | Compare the value of the central pixel to the values of the 8 pixels in the vicinity |
3 | If the neighboring pixel’s value is greater than that of the center pixel then that particular pixel is assigned the value 1, else it is assigned 0 |
4 | Replace the center pixel’s value using the neighboring 8 pixels as shown below: C = Σ (p )*(2 ), where 0 ≤ i ≤ 7 |
5 | For each pixel in the provided image, repeat the preceding instructions |
The LBP feature descriptor is mathematically represented as follows:
where R is the radius and P denotes the pixels adjacent to it. c p is the center pixel’s grayscale value, and n p is the grayscale value of the neighboring pixel. The LBP algorithm is detailed in Algorithm 2. Figure 5 compares results obtained from the image enhancement module (Contrast enhancement and LBP pre-processing) for random images from SDNET 8 . From Fig. 5 , it is evident that the crack regions are more highly visible in the contrast-enhanced images than in the original and LBP pre-processed images.

Image enhancement results on random images from SDNET 1 . ( a ) Original image ( b ) Contrast-enhanced images ( c ) LBP-processed Images.
Although the LBP operator attempted to get hold of the underlying texture of the input image, it was unable to highlight the cracked regions. The same is demonstrated by experimental results in terms of model accuracy on contrast-enhanced images and LBP pre-processed images as shown in Section “ Transfer Learning for Crack Detection with Image Enhancement ” .
Crack detection using ML models based on deep features from DCNNs
The effectiveness of deep features extracted from DCNN for classification is described in this section. The generic CNN architecture comprises a wide range of filters, pooling operators (Max pooling, Average Pooling), and nonlinear activations (ReLu, Sigmoid, Softmax). The filters are learned in either a supervised or unsupervised manner and extract relevant information from the input image. The pooling layers reduce the spatial dimension of the intermediate feature maps from convolution layers, and the activations introduce nonlinearity. Initial layers of DCNNs extract basic image features such as edges, textures, color etc. whereas the deeper layers extract complex class-specific features such as weights. This work proposes to use the weights learned by the deep layers of CNN as the feature representation for the input images, also known as Deep Features. Pre-trained CNN models including VGG16, VGG19, ResNet50, MobileNet, etc. were employed to extract the deep feature vectors to model the high-level representation of inputs. The extracted deep feature vectors are then fed into an ML algorithm like SVM for further classification as depicted in Fig. 6 .

Crack Detection using ML models Based on Deep Features from DCNNs pipeline.
The choice of using deep feature representation for the classification using ML models is based on the assumption that ML models can produce accurate results when trained on good feature representation, and deep features extracted from the final layers of DCNNs can generate high-level representations, implying a symbiotic relationship.
This section details the dataset used for the experiment. Three publicly available datasets were used for the study SDNET2018 9 , Concrete Crack Images for Classification (CCIC) 10 and Bridge Crack Dataset (BCD) 11 . We have formatted the dataset to have equal data points in all classes. However, class imbalance [ 69 ] can result in different results.
SDNET dataset
The SDNET dataset includes 56,092 images of cracked and non-cracked bridges, pavement, and wall surfaces. Images of bridge decks were obtained from the Systems, Materials, and Structural Health (SMASH) Laboratory at Utah State University, which houses a variety of full-scale bridge deck sections. Images of walls and pavements were taken on the premises of the Utah State University campus. All of the images are 256 × 256 pixels in size and in.jpg format. Table 1 summarizes the number of crack and non-crack images in each subclass of the SDNET dataset (bridge decks, walls, pavement).
CCIC dataset
The CCIC dataset includes images of concrete cracks and non-cracks. It includes more than 40,000 pictures gathered from different METU campus buildings. This dataset is balanced with only one type of surface concrete. It has 20,000 images in each class, crack and non-crack respectively. The images are of size 227 × 227.
Bridge crack dataset (BCD)
Over 6070 images of cracked and uncracked bridge surfaces are included in the Bridge Crack Dataset (BCD). The crack images were captured using the Phantom 4 Pro’s 1024 1024 CMOS surface array camera. The images were later reduced to 224 × 224 dimensions to create the dataset. This dataset contains 4056 cracked images and 14 non-cracked images. The details of the count of crack and non-crack images of the 3 datasets are provided in Table 2 .
Since all these datasets are quite large, we conducted the experiments with a smaller number of images from each of them. Table 3 summarizes the train and validation split of the images used for experiments for the three datasets and Fig. 7 shows sample images from the three datasets.

Sample crack and non-crack images from the three datasets. ( a ) Crack images from SDNET ( b ) non-crack images from SDNET ( c ) Crack images from CCIC ( d ) non-crack images from CCIC ( e ) Crack images from BCD ( f ) non-crack images from BCD.
Experimental result and analysis
This section details the obtained results and their analysis using benchmark evaluation metrics. The performance of classification models for crack detection with 12 image classification models (VGG16, VGG19, Xception, ResNet50, ResNet101, ResNet152, InceptionV3, InceptionResNetV2, MobileNet, MobileNetV2, DenseNet121 and EfficientNetB0) on 3 different datasets (SDNET, CCIC, BCD) were experimented.
Hardware and software specifications
The models were implemented on Google Colaboratory and Jupyter notebook with the Machine Learning and Deep Learning packages. The hardware specifications used for the experiments are listed in Table 4 .
Performance measures
Accuracy, sensitivity, specificity, precision, recall, F1-score, and training duration were used to assess each model’s performance. The confusion matrix, which is used to determine the model’s overall performance and is displayed in Table 5 , is utilized to calculate the performance metrics shown below.
Number of predictions made correctly by the model concerning the total predictions made.
Measure of quality of how good the model is at predicting a particular category.
Recall or sensitivity
The proportion of Positive samples that were correctly identified as Positive to all of the Positive samples.
The harmonic mean of precision and recall are given by:
Transfer learning on 3 datasets without image pre-processing
The study and findings of transfer learning without image enhancement are covered in this subsection. Using the ImageNet weights from the pre-trained model reduced the number of parameters that needed to be trained in this experiment. A flattened layer, batch normalization layer, dropout layer, and a dense layer with two neurons and a sigmoid as an activation function were added instead of the top layers of all the pre-trained models to achieve this. The transfer learning method’s fine-tuned hyper-parameters are tabulated in Table 6 .
Figures 8 , 9 and 10 show the performance comparison (precision (%), recall (%), accuracy (%)) of state-of-the-art transfer learned DCNNs on SDNET, CCIC and BCD datasets, respectively.

Performance comparison of transfer learned DCNNs on SDNET without image pre-processing.

Performance of transfer learned DCNNS on CCIC without image pre-processing.

Performance of transfer learned DCNNS on BCD without image pre-processing.
From Fig. 8 , it is observed that the ResNet101 is the best model on the SDNET dataset concerning test accuracy. In 34.45 min of training, the model achieved an accuracy of 53.40 percent. The model that performs the poorest concerning test accuracy is MobileNetV2, with a test accuracy of 42.7%. The best model on the BCD dataset from Fig. 9 , EfficientNetB0, has a test accuracy of 98.8% and a training time of 30.15 min. InceptionV3 has the lowest test accuracy of 47.8% on the BCD dataset.The best model for the CCIC dataset is ResNet50 (refer to Fig. 9 ), which achieved a test accuracy of 99.8% after 25.18 min of training. InceptionV3 has the lowest test accuracy compared to other DCNNs on this dataset, with 38.6%.
Table 7 summarizes the precision, recall and F1 score obtained for the transfer of learned DCNNs on three publicly available datasets under study. From Table 7 , it is evident that all the transfer-learned DCNNs perform poorly on the SDNET dataset compared to CCIC and BCD in terms of the three benchmark evaluation metrics under consideration. Based on this observation SDNET dataset was considered for the second experiment on transfer learned DCNNs using enhanced crack images.
Images from the SDNET dataset were pre-processed using image enhancement algorithms, and the improved images were used to transfer and learn the DCNNs. Contrast enhancement and texture feature analysis using the LBP operator were employed to enhance the crack images. The transfer learnt models were then trained using the improved images. EfficientNetB0 achieved the highest test accuracy of 65.10% on contrast-enhanced images (an improvement of 16.8%), whereas a test accuracy of 41.20% was achieved by MobileNetV2. The model that fared the best among those trained using LBP-added images was Xception, with a test accuracy of 60.80% (an improvement of 15.6%), whereas ResNet152 underperformed with a test accuracy of 42.40%. Figure 11 and Fig. 12 compare the performance of transfer learned DCNNs on contrast-enhanced images and LBP pre-processed images respectively.

Performance of transfer learned DCNNS on SDNET with Contrast enhancement.

Performance of transfer learned DCNNS on SDNET with LBP pre-processing.
Table 8 compares the improvement without and with image enhancement on SDNET images. Highlighted improvements include those in recall, precision, and F1 score. It is evident from the table that contrast enhancement improved the performance of most of the deep CNN architecture under consideration for crack detection since the enhanced images were able to highlight the cracked regions better than that of normal images.
Experiment 3: Crack detection using ML models based on deep features from DCNNs
Deep features extracted from the final fully connected layers of DCNNs and Support Vector Machine (SVM) are employed in this subsection to categorize the images into crack and non-crack classes. SVM is the most appropriate model to handle datasets with fewer samples of high-dimensional features because the deep features extracted from the fully connected layers of DCNNs will be high-dimension in nature 62 . Deep features and SVM increased the overall accuracy of the models for classification as tabulated in Table 9 . From Fig. 13 , it is understood that the MobileNet produced an accuracy of 83.16% (best model) on the SDNET dataset with deep features and SVM, while VGG16 has an accuracy of 77.16%. All the 12 deep CNN models were able to achieve an accuracy greater than 99% on the CCIC dataset which is shown in Fig. 14 . The models VGG16, ResNet152, MobileNet, MobileNetV2, and EfficientNetB0 continue to be the most accurate in this category with a 99.83% accuracy. Among the aforementioned top 5 DCNNs in terms of accuracy, MobileNetV2 has the fewest training parameters (2,223,872). From the observations, it can be inferred that MobileNetV2 demonstrated the optimum trade-off between accuracy and trainable parameters on the CCIC dataset.

Performance of SDNET with deep features.

Performance of CCIC with deep features.
From Fig. 15 , it is observed that the best models on the BCD dataset are ResNet101 and EfficientNetB0, both of which have an accuracy of 99.83%. EfficientNetB0 is preferred over ResNet101 as it has a smaller number of trainable parameters—nearly ten times fewer.

Performance of BCD with deep features.
Table 9 compares the improved ML models based on deep features for all three datasets. MobileNet was the model that performed the best among the SDNET models, which witnessed an increase in accuracy of between 20 to 30%. For the CCIC dataset accuracy enhancement is 10% and for the BCD dataset 11%.
Overall inference
The proposed study employed 12 pre-trained CNN models to get the best performance for identifying crack and non-crack surfaces. InceptionV3, InceptionResNetV2, MobileNet, MobileNetV2, DenseNet121, and EfficientNetB0 deep models were used to assess the performance of deep feature extraction and transfer learning. It can be shown from the 3 datasets (SDNET, CCIC, and BCD) that the models did exceptionally well on the CCIC and BCD datasets. This is because each of these datasets has a consistent dataset with just one type of surface. The SDNET dataset, on the other hand, has many cracks and non-crack images of various surfaces. This makes it challenging for the models to achieve the necessary accuracy on the SDNET dataset. Transfer learning models performed well on the SDNET dataset, with ResNet101 outperforming the others. ResNet50 and EfficientNetB0 were the best-performing models on the CCIC and BCD datasets, respectively. Even though some models did well on the CCIC and BCD datasets, their accuracy could yet be improved. The findings of the following experiment, in which deep features were extracted and SVM was used to classify data, were better than those of the prior one. MobileNet was the model that performed the best among the SDNET models, which witnessed an increase in accuracy of between 20 to 30%. On the CCIC and BCD datasets, each model’s accuracy was close to 99%. The model’s accuracy significantly improves when extracted deep features are fed to the SVM classifier. The accuracy of models on the SDNET dataset could yet be increased. In other words, performance measures were assessed after all of these models underwent training using images that had previously experienced some processing. While the texture operator LBP did not significantly affect model accuracy, increasing contrast proved to be a helpful pre-processing strategy that led to greater accuracy. This experiment outperformed the prior transfer learning models, but not the accuracy attained by deep features fed into the SVM classifier. From Table 10 and Table 11 it is inferred that, out of the three experiments, classifying images as crack or non-crack using deep features provided to the SVM classifier was successful and produced superior accuracies across all datasets (SDNET: MobileNet; CCIC: MobileNetV2; BCD: EfficientNetB0).
Conclusion and future scope
The proposed study compared the effectiveness of Deep Convolutional Neural Networks as a classifier and as a feature extractor for crack detection.
The performance of 12 different transfer-learned DCNN models for crack detection was evaluated and analyzed on three publicly available datasets: SDNET, CCIC and BCD. The effectiveness of image enhancement and deep features extracted from the final fully connected layers of CNN models for classification was also analyzed in terms of benchmark evaluation metrics.
ResNet101(Accuracy: 53.40%), EfficientNetB0 (Accuracy:98.8%) and ResNet50(Accuracy:99.8%) produced best accuracy with normal images from SDNET, BCD and CCIC dataset respectively. Since the effectiveness of transfer learned deep models were minimal on the SDNET images, two image enhancement methods (contrast enhancement and Local Binary Pattern) were employed on the images.
The experimental results show that the enhanced images improved the accuracy of transfer-learned crack detection models significantly.
The effectiveness of Deep features extracted from the final fully connected layers of DCNNs was analyzed in terms of classification accuracy. The extracted deep feature was fed into SVM for classification and the analysis in terms of accuracy, precision, recall, and F1-score revealed that the integration of deep features with SVM improved the detection accuracy across all the DCNN-dataset combinations.
Among the SDNET models, MobileNet was the finest model, with an improvement in accuracy of between 20 and 30%. Each model’s accuracy on the CCIC and BCD datasets was close to 99% for MobileNetV2 and EfficientNetB0 respectively.
The main takeaway is that we can enhance the efficiency, accuracy and decision-making processes in civil engineering applications using these models. By using ML/DL models, the task of structural health monitoring becomes so easy and efficient. It identifies potential structural issues in early stages, contributing to faster maintenance and better safety. A custom ensemble model by combining the best DCNNs for crack detection could be considered as the future scope of this study. There has been substantial research to deal with problems like security 63 and resource allocation 64 with ML and DL models. As a future scope, with enough models to accurately detect cracks we can form so many use cases to bring it to the consumers.
Data availability
The datasets generated and/or analysed during the current study are available in the SDNET2018 repository, https://digitalcommons.usu.edu/cgi/viewcontent.cgi?article=4611&context=cee_facpub 9 , Concrete Crack Images for Classification (CCIC) repository, https://www.kaggle.com/datasets/arnavr10880/concrete-crack-images-for-classification 10 and Bridge Crack Dataset (BCD) repository, https://www.mdpi.com/2076-3417/9/14/2867 11 .
Yi, Y., Zhu, D., Guo, S., Zhang, Z. & Shi, C. A review on the deterioration and approaches to enhance the durability of concrete in the marine environment. Cement Concr. Compos. 113 , 103695 (2020).
Article CAS Google Scholar
Ham, Y., Han, K. K., Lin, J. J. & Golparvar-Fard, M. Visual monitoring of civil infrastructure systems via camera-equipped unmanned aerial vehicles (UAVs): A review of related works. Vis. Eng. 4 (1), 1–8 (2016).
Article Google Scholar
Sharma, K. V. et al. Prognostic modeling of polydisperse SiO2/Aqueous glycerol nanofluids’ thermophysical profile using an explainable artificial intelligence (XAI) approach. Eng. Appl. Artif. Intell. 126 , 106967 (2023).
Kanti, P. K. et al. Thermophysical profile of graphene oxide and MXene hybrid nanofluids for sustainable energy applications: Model prediction with a Bayesian optimized neural network with K-cross fold validation. FlatChem 39 , 100501 (2023).
Kanti, P. et al. Properties of water-based fly ash-copper hybrid nanofluid for solar energy applications: Application of RBF model. Sol. Energy Mater. Sol. Cells 234 , 111423 (2022).
Kanti, P. K. et al. The stability and thermophysical properties of Al2O3-graphene oxide hybrid nanofluids for solar energy applications: application of robust autoregressive modern machine learning technique. Sol. Energy Mater. Sol. Cells 253 , 112207 (2023).
Hsieh, Y. A. & Tsai, Y. J. Machine learning for crack detection: Review and model performance comparison. J. Comput. Civ. Eng. 34 (5), 04020038 (2020).
Munawar, H. S., Hammad, A. W. A., Haddad, A., Soares, C. A. P. & Waller, S. T. Image-based crack detection methods: A review. Infrastructures 6 , 115. https://doi.org/10.3390/infrastructures6080115 (2021).
Dorafshan, S., Thomas, R. J. & Maguire, M. Sdnet 2018: An annotated image dataset for non-contact concrete crack detection using deep convolutional neural networks. Data Brief 21 , 1664–1668 (2018).
Article PubMed PubMed Central Google Scholar
C¸ a˘glar, F., O ¨ zgenel, R.: Concrete crack images for classification. Mendeley Data 2 (2019)
Xu, H. et al. Automatic bridge crack detection using a convolutional neural network. Appl. Sci. 9 (14), 2867 (2019).
Harinath Reddy, C., Mini, K., Radhika, N.: Structural health monitor- ing—an integrated approach for vibration analysis with wireless sensors to steel structure using image processing. In: International Conference on ISMAC in Computational Vision and Bio-Engineering, pp. 1595–1610 (2018). Springer
Pauly, L., Hogg, D., Fuentes, R., Peel, H.: Deeper networks for pavement crack detection. In: Proceedings of the 34th ISARC, pp. 479–485 (2017). IAARC
Lins, R. G. & Givigi, S. N. Automatic crack detection and measurement based on image analysis. IEEE Trans. Instrum. Meas. 65 (3), 583–590. https://doi.org/10.1109/TIM.2015.2509278 (2016).
Shahrokhinasab, E., Hosseinzadeh, N., Monirabbasi, A. & Torkaman, S. Performance of image-based crack detection systems in concrete structures. J. Soft Comput. Civ. Eng. 4 (1), 127–139 (2020).
Google Scholar
Munawar, H. S., Hammad, A. W., Haddad, A., Soares, C. A. P. & Waller, S. T. Image-based crack detection methods: A review. Infrastructures 6 (8), 115 (2021).
Zou, Q., Cao, Y., Li, Q., Mao, Q. & Wang, S. Cracktree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 33 (3), 227–238 (2012).
Salman, M., Mathavan, S., Kamal, K. & Rahman, M. Pavement crack detection using the Gabor filter. In 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013) (eds Salman, M. et al. ) 2039–2044 (IEEE, 2013).
Chapter Google Scholar
Niu, B., Wu, H. & Meng, Y. Application of cem algorithm in the field of tunnel crack identification. In 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC) (eds Niu, B. et al. ) 232–236 (IEEE, 2020).
Chhabra, G. et al. Human emotions recognition, analysis and transformation by the bioenergy field in smart grid using image processing. Electronics 11 , 4059. https://doi.org/10.3390/electronics11234059 (2022).
Baltazart, V., Nicolle, P. & Yang, L. Ongoing tests and improvements of the mps algorithm for the automatic crack detection within grey level pavement images. In 2017 25th European Signal Processing Conference (EUSIPCO) (eds Baltazart, V. et al. ) 2016–2020 (IEEE, 2017).
Jo, J. & Jadidi, Z. A high precision crack classification system using multi-layered image processing and deep belief learning. Struct. Infrastruct. Eng. 16 (2), 297–305 (2020).
Landstrom, A. & Thurley, M. J. Morphology-based crack detection for steel slabs. IEEE J. Sel. Top. Signal Process. 6 (7), 866–875 (2012).
Prasanna, P. et al. Automated crack detection on concrete bridges. IEEE Trans. Autom. Sci. Eng. 13 (2), 591–599 (2014).
Lin, M., Zhou, R., Yan, Q. & Xu, X. Automatic pavement crack detection using hmrf-em algorithm. In 2019 International Conference on Computer, Information and Telecommunication Systems (CITS) (eds Lin, M. et al. ) 1–5 (IEEE, 2019).
Pratico, F. G., Fedele, R., Naumov, V. & Sauer, T. Detection and monitoring of bottom-up cracks in road pavement using a machine-learning approach. Algorithms 13 (4), 81 (2020).
Zhang, F. et al. A new identification method for surface cracks from uav images based on machine learning in coal mining areas. Remote Sens. 12 (10), 1571 (2020).
Zhang, L. et al. Machine learning-based real-time visible fatigue crack growth detection. Digit. Commun. Netw. 7 (4), 551–558 (2021).
Dharneeshkar, J. et al. Deep learning based detection of potholes in indian roads using yolo. In 2020 International Conference on Inventive Computation Technologies (ICICT) (eds Dharneeshkar, J. et al. ) 381–385 (IEEE, 2020).
Li, H., Zong, J., Nie, J., Wu, Z. & Han, H. Pavement crack detection algorithm based on densely connected and deeply supervised network. IEEE Access 9 , 11835–11842 (2021).
Zhang, L., Yang, F., Zhang, Y. D. & Zhu, Y. J. Road crack detection using deep convolutional neural network. In 2016 IEEE International Conference on Image Processing (ICIP) (eds Zhang, L. et al. ) 3708–3712 (IEEE, 2016).
Meng, X. Concrete crack detection algorithm based on deep residual neural networks. Sci. Program. 2021 , 1–7 (2021).
CAS Google Scholar
Su, C. & Wang, W. Concrete cracks detection using convolutional neural- network based on transfer learning. Math. Problems Eng. 2020 , 1–10 (2020).
Ye, X.-W., Jin, T. & Chen, P.-Y. Structural crack detection using deep learning–based fully convolutional networks. Adv. Struct. Eng. 22 (16), 3412–3419 (2019).
Feng, C. et al. Structural damage detection using deep convolutional neural network and transfer learning. KSCE J. Civ. Eng. 23 (10), 4493–4502 (2019).
Kim, C. N., Kawamura, K., Nakamura, H. & Tarighat, A. Automatic crack detection for concrete infrastructures using image processing and deep learning. In IOP Conference Series: Materials Science and Engineering Vol. 829 (eds Kim, C. N. et al. ) 012027 (IOP Publishing, 2020).
Cao, M.-T., Tran, Q.-V., Nguyen, N.-M. & Chang, K.-T. Survey on performance of deep learning models for detecting road damages using multiple dashcam image resources. Adv. Eng. Inform. 46 , 101182 (2020).
Nguyen, N. H. T., Perry, S., Bone, D., Le, H. T. & Nguyen, T. T. Two-stage convolutional neural network for road crack detection and segmentation. Expert Syst. Appl. 186 , 115718 (2021).
Park, S. E., Eem, S.-H. & Jeon, H. Concrete crack detection and quantifica- tion using deep learning and structured light. Constr. Build. Mater. 252 , 119096 (2020).
Huyan, J., Li, W., Tighe, S., Xu, Z. & Zhai, J. Cracku-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control Health Monit. 27 (8), 2551 (2020).
Kim, B., Yuvaraj, N., Sri Preethaa, K. & Arun Pandian, R. Surface crack detection using deep learning with shallow cnn architecture for enhanced computation. Neural Computing Appl. 33 (15), 9289–9305 (2021).
GI, K.F.: A hierarchical neural network capable of visual pattern recognition. Neural Network 1 (1989).
Russakovsky, O. et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 115 (3), 211–252 (2015).
Article MathSciNet Google Scholar
LeCun, Y. et al. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process. Syst. 2 , 396–404 (1989).
Arel, I., Rose, D. C. & Karnowski, T. P. Deep machine learning-a new frontier in artificial intelligence research [research frontier]. IEEE comput. Intel. Mag. 5 (4), 13–18 (2010).
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large- scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
Chollet, F.: Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1251–1258 (2017).
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2818–2826 (2016).
Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A.A.: Inception-v4, inception-resnet and the impact of residual connections on learning. In: Thirty-first AAAI Conference on Artificial Intelligence (2017).
Andrew, G. et al. Efficient convolutional neural networks for mobile vision applications. Mobilenets. Available: http://arxiv.org/abs/1704.04861 (2017).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.-C.: Mobilenetv2: Inverted residuals and linear bottlenecks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4510–4520 (2018).
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4700–4708 (2017).
Tan, M. & Le, Q. Efficient Net: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning (eds Tan, M. & Le, Q.) 6105–6114 (PMLR, 2019).
Sikha, O. & Bharath, B. Vgg16-random fourier hybrid model for masked face recognition. Soft Comput. 26 , 1–16 (2022).
Srihari, K. & Sikha, O. Partially supervised image captioning model for urban road views. In Intelligent Data Communication Technologies and Internet of Things (eds Srihari, K. & Sikha, O.) 59–73 (Springer, 2022).
Krishnan, G. & Sikha, O. Analysis on the Effectiveness of Transfer Learned Features for x-ray Image Retrieval. In Innovative Data Communication Technologies and Application (eds Krishnan, G. & Sikha, O.) 251–265 (Springer, 2022).
Brownlee, J. A Gentle Introduction to Transfer Learning for Deep Learning (Machine Learning Mastery, 2017).
Wang, Y. et al. Research on crack detection algorithm of the concrete bridge based on image processing. Proced. Comput. Sci. 154 , 610–616 (2019).
Chen, C., Seo, H., Jun, C. H. & Zhao, Y. Pavement crack detection and classification based on fusion feature of LBP and pca with SVM. Int. J. Pavement Eng. 23 (9), 3274–3283 (2022).
Ojala, T., Pietikainen, M. & Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 29 (1), 51–59 (1996).
Sari, Y., Prakoso, P. B. & Baskara, A. R. Road crack detection using support vector machine (svm) and otsu algorithm. In 2019 6th International Conference on Electric Vehicular Technology (ICEVT) (eds Sari, Y. et al. ) 349–354 (IEEE, 2019).
Shafiq, M., Yadav, R., Javed, A. R. & Mohsin, S. A. H. CoopGBFS: A Federated Learning and Game-Theoretic Based Approach for Personalized Security, Recommendation in 5G Beyond IoT Environments for Consumer Electronics (IEEE, 2023).
Shafiq, M., Tian, Z., Liu, Y., Aljuhani, A. & Li, Y. ESC&RAO: Enabling seamless connectivity resource allocation in tactile IoT for consumer electronics. IEEE Trans. Consum. Electron. https://doi.org/10.1109/TCE.2023.3327136 (2023).
Download references
Acknowledgements
We thank everyone that supported the study in one way or the other.
HQ thanks the support of NSF award 1761839 and 2200138.
Author information
Authors and affiliations.
Department of Computer Science and Engineering, Amrita School of Computing, Amrita Vishwa Vidyapeetham, Coimbatore, Tamil Nadu, 641112, India
K. S. Bhalaji Kharthik & O. K. Sikha
Department of Mathematics and Computer Science, Coal City University, Enugu, Nigeria
Edeh Michael Onyema
Adjunct Faculty, Saveetha School of Engineering, Saveetha Institute of Medical and Technical Sciences, Chennai, India
Department of Environmental Health, Harvard T H Chan School of Public Health, Boston, MA, 02115, USA
Saurav Mallik
School of Engineering (CSE), Anurag University, Hyderabad, India
B. V. V. Siva Prasad
Department of Computer Science and Engineering, The University of Tennessee at Chattanooga, Chattanooga, TN, USA
Department of Computer Science and Engineering, Indian Institute of Information Technology, Kottayam, Kerala, 686635, India
Dept. of Information and Communication Technologies, BCN Medtech, Universitat Pompeu Fabra, Barcelona, Spain
O. K. Sikha
You can also search for this author in PubMed Google Scholar
Contributions
B.K.K.S., E.M.O., S.M. developed the idea and implemented, B.V.V.S.P. wrote the manuscript, H.Q., S.C., S.O.K. reviewed and revised the manuscript. All authors consented to the publication of this paper.
Corresponding authors
Correspondence to Edeh Michael Onyema , Saurav Mallik or Hong Qin .
Ethics declarations
Competing interests.
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Bhalaji Kharthik, K.S., Onyema, E.M., Mallik, S. et al. Transfer learned deep feature based crack detection using support vector machine: a comparative study. Sci Rep 14 , 14517 (2024). https://doi.org/10.1038/s41598-024-63767-5
Download citation
Received : 07 March 2024
Accepted : 31 May 2024
Published : 24 June 2024
DOI : https://doi.org/10.1038/s41598-024-63767-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Convolutional neural networks
- Crack detection
- Support vector machine (SVM)
- Transfer learning
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Anthropocene newsletter — what matters in anthropocene research, free to your inbox weekly.

IMAGES
VIDEO
COMMENTS
Scope of research refers to the range of topics, areas, and subjects that a research project intends to cover. It is the extent and limitations of the study, defining what is included and excluded in the research. The scope of a research project depends on various factors, such as the research questions, objectives, methodology, and available ...
In order to write the scope of the study that you plan to perform, you must be clear on the research parameters that you will and won't consider. These parameters usually consist of the sample size, the duration, inclusion and exclusion criteria, the methodology and any geographical or monetary constraints. Each of these parameters will have ...
Any study that describes or analyzes methods (design, conduct, analysis or reporting) in published (or unpublished) literature is a methodological study. Consequently, the scope of methodological studies is quite extensive and includes, but is not limited to, topics as diverse as: research question formulation ; adherence to reporting ...
Your study's scope and delimitations are the sections where you define the broader parameters and boundaries of your research. The scope details what your study will explore, such as the target population, extent, or study duration. Delimitations are factors and variables not included in the study. Scope and delimitations are not methodological ...
Example 1. Research question: What are the effects of social media on mental health? Scope: The scope of the study will focus on the impact of social media on the mental health of young adults aged 18-24 in the United States. Delimitation: The study will specifically examine the following aspects of social media: frequency of use, types of social media platforms used, and the impact of social ...
Case Study Research Methodology. This is a research methodology that involves in-depth examination of a single case or a small number of cases. Case studies are often used in psychology, sociology, and anthropology to gain a detailed understanding of a particular individual or group. ... Scope for innovation: Research methodology provides scope ...
What is scope and delimitation in research. The scope of a research paper explains the context and framework for the study, outlines the extent, variables, or dimensions that will be investigated, and provides details of the parameters within which the study is conducted.Delimitations in research, on the other hand, refer to the limitations imposed on the study.
A good research methodology always explains the procedure, data collection methods and techniques, aim, and scope of the research. In a research study, it leads to a well-organized, rationality-based approach, while the paper lacking it is often observed as messy or disorganized.
Consider the feasibility of your work before you write down the scope. Again, if the scope is too narrow, the findings might not be generalizable. Typically, the information that you need to include in the scope would cover the following: 1. General purpose of the study. 2. The population or sample that you are studying. 3. The duration of the ...
The scope of your project sets clear parameters for your research.. A scope statement will give basic information about the depth and breadth of the project. It tells your reader exactly what you want to find out, how you will conduct your study, the reports and deliverables that will be part of the outcome of the study, and the responsibilities of the researchers involved in the study.
Methodological studies - studies that evaluate the design, analysis or reporting of other research-related reports - play an important role in health research. They help to highlight issues in the conduct of research with the aim of improving health research methodology, and ultimately reducing research waste. We provide an overview of some of the key aspects of methodological studies such ...
Definition, Types, and Examples. Research methodology 1,2 is a structured and scientific approach used to collect, analyze, and interpret quantitative or qualitative data to answer research questions or test hypotheses. A research methodology is like a plan for carrying out research and helps keep researchers on track by limiting the scope of ...
Step 1: Explain your methodological approach. Step 2: Describe your data collection methods. Step 3: Describe your analysis method. Step 4: Evaluate and justify the methodological choices you made. Tips for writing a strong methodology chapter. Other interesting articles.
A scope is needed for all types of research: quantitative, qualitative, and mixed methods. To define your scope of research, consider the following: Budget constraints or any specifics of grant funding; Your proposed timeline and duration; Specifics about your population of study, your proposed sample size, and the research methodology you'll ...
INTRODUCTION. Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses.1,2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results.3,4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the ...
As we mentioned, research methodology refers to the collection of practical decisions regarding what data you'll collect, from who, how you'll collect it and how you'll analyse it. Research design, on the other hand, is more about the overall strategy you'll adopt in your study. For example, whether you'll use an experimental design ...
The four purposes of scoping studies lack clarity. 1. Clearly articulate the research question that will guide the scope of inquiry. Consider the concept, target population, and health outcomes of interest to clarify the focus of the scoping study and establish an effective search strategy. 2.
A research methodology encompasses the way in which you intend to carry out your research. This includes how you plan to tackle things like collection methods, statistical analysis, participant observations, and more. You can think of your research methodology as being a formula. One part will be how you plan on putting your research into ...
Answer: Scope and delimitations are two elements of a research paper or thesis. The scope of a study explains the extent to which the research area will be explored in the work and specifies the parameters within which the study will be operating. For example, let's say a researcher wants to study the impact of mobile phones on behavior ...
Delimitations refer to the specific boundaries or limitations that are set in a research study in order to narrow its scope and focus. Delimitations may be related to a variety of factors, including the population being studied, the geographical location, the time period, the research design, and the methods or tools being used to collect data.
2.4.1 Research Approach . In view of the key research questions and the specific objectives outlined above, it is clear that this study needs to deploy a mixed method research approach, which can generate the theoretical framework that can explain how different components of the ENRICH programme are impacting on 'freedom of choice' of the programme participants (who were previously denied ...
CHAPTER 1: SCOPE AND NATURE OF THE STUDY [The BOP offers] a massive opportunity for private sector firms to engage in ways that improve poor peoples' lives. ... This research proposes to develop a methodology, through theoretical research as well as making use of a case study, which can be used in determining areas that offer the greatest ...
1 Answer to this question. Answer: The scope of a study explains the extent to which the research area will be explored in the study and specifies the parameters within which the study will be operating. Thus, the scope of a study will define the purpose of the study, the population size and characteristics, geographical location, the time ...
In order to demonstrate how the guide can be used to plan a research study utilizing causal methods, we turn to a previously published study (Dondo et al. 2017) that assessed the causal relationship between the use of 𝛽-blockers and mortality after acute myocardial infarction in patients without heart failure or left ventricular systolic ...
Cancer Medicine is an open access, broad-scope oncology journal covering clinical cancer research, cancer biology, cancer prevention, & bioinformatics. ... Materials and Methods. In this study, we conducted a retrospective data collection of HER2-Mutated advanced LUAD who received first-line treatment and pyrotinib between May 2014 and June ...
The current study explores two promising SDG methods - an open-source method and a proprietary method - and evaluates them on a specific causal effect estimation task. METHODS: In this study, we established an evaluation framework to assess synthetic data quality by comparing target causal effect estimates across different estimation methods.
A custom ensemble model by combining the best DCNNs for crack detection could be considered as the future scope of this study. There has been substantial research to deal with problems like ...