- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case AskWhy Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research

Sample: Definition, Types, Formula & Examples

How often do researchers look for the right survey respondents, either for a market research study or an existing survey in the field? The sample or the respondents of this research may be selected from a set of customers or users that are known or unknown.
You may often know your typical respondent profile but don’t have access to the respondents to complete your research study. At such times, researchers and research teams reach out to specialized organizations to access their panel of respondents or buy respondents from them to complete research studies and surveys.
These could be general population respondents that match demographic criteria or respondents based on specific criteria. Such respondents are imperative to the success of research studies.
This article discusses in detail the different types of samples, sampling methods, and examples of each. It also mentions the steps to calculate the size, the details of an online sample, and the advantages of using them.
Content Index
- What is a sample?
Probability sampling methodologies with examples
Non-probability sampling methodologies with examples.
- How to determine a sample size
- Calculating sample size
- Sampling advantages
What is a Sample?
A sample is a smaller set of data that a researcher chooses or selects from a larger population using a pre-defined selection bias method. These elements are known as sample points, sampling units, or observations.
Creating a sample is an efficient method of conducting research . Researching the whole population is often impossible, costly, and time-consuming. Hence, examining the sample provides insights the researcher can apply to the entire population.
For example, if a cell phone manufacturer wants to conduct a feature research study among students in US Universities. An in-depth research study must be conducted if the researcher is looking for features that the students use, features they would like to see, and the price they are willing to pay.
This step is imperative to understand the features that need development, the features that require an upgrade, the device’s pricing, and the go-to-market strategy.
In 2016/17 alone, there were 24.7 million students enrolled in universities across the US. It is impossible to research all these students; the time spent would make the new device redundant, and the money spent on development would render the study useless.
Creating a sample of universities by geographical location and further creating a sample of these students from these universities provides a large enough number of students for research.
Typically, the population for market research is enormous. Making an enumeration of the whole population is practically impossible. The sample usually represents a manageable size of this population. Researchers then collect data from these samples through surveys, polls, and questionnaires and extrapolate this data analysis to the broader community.
LEARN ABOUT: Survey Sampling
Types of Samples: Selection methodologies with examples
The process of deriving a sample is called a sampling method. Sampling forms an integral part of the research design as this method derives the quantitative and qualitative data that can be collected as part of a research study. Sampling methods are characterized into two distinct approaches: probability sampling and non-probability sampling.
Probability sampling is a method of deriving a sample where the objects are selected from a population-based on probability theory. This method includes everyone in the population, and everyone has an equal chance of being selected. Hence, there is no bias whatsoever in this type of sample.
Each person in the population can subsequently be a part of the research. The selection criteria are decided at the outset of the market research study and form an important component of research.
LEARN ABOUT: Action Research

Probability sampling can be further classified into four distinct types of samples. They are:
- Simple random sampling: The most straightforward way of selecting a sample is simple random sampling . In this method, each member has an equal chance of participating in the study. The objects in this sample population are chosen randomly, and each member has the same probability of being selected. For example, if a university dean would like to collect feedback from students about their perception of the teachers and level of education, all 1000 students in the University could be a part of this sample. Any 100 students can be selected randomly to be a part of this sample.
- Cluster sampling: Cluster sampling is a type of sampling method where the respondent population is divided into equal clusters. Clusters are identified and included in a sample based on defining demographic parameters such as age, location, sex, etc. This makes it extremely easy for a survey creator to derive practical inferences from the feedback. For example, if the FDA wants to collect data about adverse side effects from drugs, they can divide the mainland US into distinctive cluster analysis , like states. Research studies are then administered to respondents in these clusters. This type of generating a sample makes the data collection in-depth and provides easy-to-consume and act-upon, insights.
- Systematic sampling: Systematic sampling is a sampling method where the researcher chooses respondents at equal intervals from a population. The approach to selecting the sample is to pick a starting point and then pick respondents at a pre-defined sample interval. For example, while selecting 1,000 volunteers for the Olympics from an application list of 10,000 people, each applicant is given a count of 1 to 10,000. Then starting from 1 and selecting each respondent with an interval of 10, a sample of 1,000 volunteers can be obtained.
- Stratified random sampling: Stratified random sampling is a method of dividing the respondent population into distinctive but pre-defined parameters in the research design phase. In this method, the respondents don’t overlap but collectively represent the whole population. For example, a researcher looking to analyze people from different socioeconomic backgrounds can distinguish respondents by their annual salaries. This forms smaller groups of people or samples, and then some objects from these samples can be used for the research study.
LEARN ABOUT: Purposive Sampling
The non-probability sampling method uses the researcher’s discretion to select a sample. This type of sample is derived mostly from the researcher’s or statistician’s ability to get to this sample.
This type of sampling is used for preliminary research where the primary objective is to derive a hypothesis about the topic in research. Here each member does not have an equal chance of being a part of the sample population, and those parameters are known only post-selection to the sample.

We can classify non-probability sampling into four distinct types of samples. They are:
- Convenience sampling: Convenience sampling , in easy terms, stands for the convenience of a researcher accessing a respondent. There is no scientific method for deriving this sample. Researchers have nearly no authority over selecting the sample elements, and it’s purely done based on proximity and not representativeness.
This non-probability sampling method is used when there is time and costs limitations in collecting feedback. For example, researchers that are conducting a mall-intercept survey to understand the probability of using a fragrance from a perfume manufacturer. In this sampling method, the sample respondents are chosen based on their proximity to the survey desk and willingness to participate in the research.
- Judgemental/purposive sampling: The judgemental or purposive sampling method is a method of developing a sample purely on the basis and discretion of the researcher purely, based on the nature of the study along with his/her understanding of the target audience. This sampling method selects people who only fit the research criteria and end objectives, and the remaining are kept out.
For example, if the research topic is understanding what University a student prefers for Masters, if the question asked is “Would you like to do your Masters?” anything other than a response, “Yes” to this question, everyone else is excluded from this study.
- Snowball sampling: Snowball sampling or chain-referral sampling is defined as a non-probability sampling technique in which the samples have rare traits. This is a sampling technique in which existing subjects provide referrals to recruit samples required for a research study.
For example, while collecting feedback about a sensitive topic like AIDS, respondents aren’t forthcoming with information. In this case, the researcher can recruit people with an understanding or knowledge of such people and collect information from them or ask them to collect information.
- Quota sampling: Quota sampling is a method of collecting a sample where the researcher has the liberty to select a sample based on their strata. The primary characteristic of this method is that two people cannot exist under two different conditions. For example, when a shoe manufacturer would like to understand millennials’ perception of the brand with other parameters like comfort, pricing, etc. It selects only females who are millennials for this study as the research objective is to collect feedback about women’s shoes.
How to determine a Sample Size
As we have learned above, the right sample size determination is essential for the success of data collection in a market research study. But is there a correct number for the sample size? What parameters decide the sample size? What are the distribution methods of the survey?
To understand all of this and make an informed calculation of the right sample size, it is first essential to understand four important variables that form the basic characteristics of a sample. They are:
- Population size: The population size is all the people that can be considered for the research study. This number, in most cases, runs into huge amounts. For example, the population of the United States is 327 million. But in market research, it is impossible to consider all of them for the research study.
- The margin of error (confidence interval): The margin of error is depicted by a percentage that is a statistical inference about the confidence of what number of the population depicts the actual views of the whole population. This percentage helps towards the statistical analysis in selecting a sample and how much sampling error in this would be acceptable.
LEARN ABOUT: Research Process Steps
- Confidence level: This metric measures where the actual mean falls within a confidence interval. The most common confidence intervals are 90%, 95%, and 99%.
- Standard deviation: This metric covers the variance in a survey. A safe number to consider is .5, which would mean that the sample size has to be that large.
Calculating Sample Size
To calculate the sample size, you need the following parameters.
- Z-score: The Z-score value can be found here .
- Standard deviation
- Margin of error
- Confidence level
To calculate use the sample size, use this formula:

Sample Size = (Z-score)2 * StdDev*(1-StdDev) / (margin of error)2
Consider the confidence level of 90%, standard deviation of .6 and margin of error, +/-4%
((1.64)2 x .6(.6)) / (.04)2
( 2.68x .0.36) / .0016
.9648 / .0016
603 respondents are needed and that becomes your sample size.
Try our sample size calculator to give population, margin of error calculator , and confidence level.
LEARN MORE: Population vs Sample
Sampling Advantages
As shown above, there are many advantages to sampling. Some of the most significant advantages are:

- Reduced cost & time: Since using a sample reduces the number of people that have to be reached out to, it reduces cost and time. Imagine the time saved between researching with a population of millions vs. conducting a research study using a sample.
- Reduced resource deployment: It is obvious that if the number of people involved in a research study is much lower due to the sample, the resources required are also much less. The workforce needed to research the sample is much less than the workforce needed to study the whole population .
- Accuracy of data: Since the sample indicates the population, the data collected is accurate. Also, since the respondent is willing to participate, the survey dropout rate is much lower, which increases the validity and accuracy of the data.
- Intensive & exhaustive data: Since there are lesser respondents, the data collected from a sample is intense and thorough. More time and effort are given to each respondent rather than collecting data from many people.
- Apply properties to a larger population: Since the sample is indicative of the broader population, it is safe to say that the data collected and analyzed from the sample can be applied to the larger population, which would hold true.
To collect accurate data for research, filter bad panelists, and eliminate sampling bias by applying different control measures. If you need any help arranging a sample audience for your next market research project, contact us at [email protected] . We have more than 22 million panelists across the world!
In conclusion, a sample is a subset of a population that is used to represent the characteristics of the entire population. Sampling is essential in research and data analysis to make inferences about a population based on a smaller group of individuals. There are different types of sampling, such as probability sampling, non-probability sampling, and others, each with its own advantages and disadvantages.
Choosing the right sampling method depends on the research question, budget, and resources is important. Furthermore, the sample size plays a crucial role in the accuracy and generalizability of the findings.
This article has provided a comprehensive overview of the definition, types, formula, and examples of sampling. By understanding the different types of sampling and the formulas used to calculate sample size, researchers and analysts can make more informed decisions when conducting research and data unit of analysis .
Sampling is an important tool that enables researchers to make inferences about a population based on a smaller group of individuals. With the right sampling method and sample size, researchers can ensure that their findings are accurate and generalizable to the population.
Utilize one of QuestionPro’s many survey questionnaire samples to help you complete your survey.
When creating online surveys for your customers, employees, or students, one of the biggest mistakes you can make is asking the wrong questions. Different businesses and organizations have different needs required for their surveys.
If you ask irrelevant questions to participants, they’re more likely to drop out before completing the survey. A questionnaire sample template will help set you up for a successful survey.
LEARN MORE SIGN UP FREE
MORE LIKE THIS

Closed-Loop Management: The Key to Customer Centricity
Sep 3, 2024

Net Trust Score: Tool for Measuring Trust in Organization
Sep 2, 2024

Why You Should Attend XDAY 2024
Aug 30, 2024

Alchemer vs Qualtrics: Find out which one you should choose
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Tuesday CX Thoughts (TCXT)
- Uncategorized
- What’s Coming Up
- Workforce Intelligence
- Form Builder
- Survey Maker
- AI Form Generator
- AI Survey Tool
- AI Quiz Maker
- Store Builder
- WordPress Plugin
HubSpot CRM
Google Sheets
Google Analytics
Microsoft Excel
- Popular Forms
- Job Application Form Template
- Rental Application Form Template
- Hotel Accommodation Form Template
- Online Registration Form Template
- Employment Application Form Template
- Application Forms
- Booking Forms
- Consent Forms
- Contact Forms
- Donation Forms
- Customer Satisfaction Surveys
- Employee Satisfaction Surveys
- Evaluation Surveys
- Feedback Surveys
- Market Research Surveys
- Personality Quiz Template
- Geography Quiz Template
- Math Quiz Template
- Science Quiz Template
- Vocabulary Quiz Template
Try without registration Quick Start
Read engaging stories, how-to guides, learn about forms.app features.
Inspirational ready-to-use templates for getting started fast and powerful.
Spot-on guides on how to use forms.app and make the most out of it.
See the technical measures we take and learn how we keep your data safe and secure.
- Integrations
- Help Center
- Sign In Sign Up Free
- What is a sample in research: Definition, examples & tips

Researchers can conduct studies on large populations. It is highly unusual for researchers to be able to get information from every member of a group of individuals they are studying. If you are researching a large population, you can pick a sample .
The population that will participate in the study is the sample. Using samples, researchers may perform their experiments more quickly and with more manageable data. This article will explain the definition of a sample in research, what a sample is in statistics with examples, how researchers choose a sample, and how to determine the correct sample size for your research with all details.
- What is a sample?
A sample is a condensed, controllable representation of a larger group . It is a subgroup of people with traits from a wider population . When the population size is too large for the test to include all potential participants or observations, samples are utilized in statistical testing.

The definition of a sample
To put it simply: a sample is a more manageable and compact version of a bigger group. A sampler population possesses the traits of a bigger group. A sample is utilized in statistical analysis when the population size is too big to include all individuals or observations in the test.
A sample is an analytical subset of a larger population in statistics . The sample should be representative of the population as a whole and should not show bias toward any particular characteristic. The researcher gains knowledge from the sample that can be applied to the entire population.
- How do researchers choose a sample?
Sampling is an essential component of the research design as it gathers information that can be used in a research study. Probability sampling and non probability sampling are the essential methodologies that define sampling techniques.

Sampling methodologies
Probability sampling
Probability sampling is a sampling technique that entails randomly picking a sample or a section of the population. It is also known as random sampling . When procedures are established to guarantee that each unit within a population has an equal probability of being picked , this is known as random selection. Here are 4 types of probability sampling designs that are frequently used.
1 - Simple random sampling
Simple random sampling takes a random selection from the whole population with an equal probability of selection for each unit. The most typical method of choosing a random sample is the one.
Consider creating a list of every person in the population and giving them a number. Using a random number table, random number table, or random number generator, you choose samples at random from this population.
2 - Stratified sampling
Stratified sampling randomly chooses a sample from one or more strata or population subgroups . Each group is distinguished from the others based on a shared trait, such as age, gender, color, and religion.
By doing this, you can ensure that your sample population sufficiently represents each subgroup of a particular community. For example, if you divide a student population by university majors, Architecture, Linguistics, and Teaching departments, students are three different tiers within that population.
3 - Cluster sampling
The cluster sampling method divides the population into clusters , which are smaller groupings. Then, you choose a sample of people at random from these clusters. Large or geographically distributed populations are frequently studied using cluster sampling.
For example, you may divide all cities into neighborhoods or clusters and then choose the areas with the most significant population while filtering by mobile device users to see how well your goods perform across a city.
4 - Systematic sampling
When using systematic sampling , units are chosen at regular intervals beginning at a random point , drawing a random sample from the target population. Every member of the population is assigned a number in systematic sampling , but rather than being a random selection procedure, people are picked out at predetermined intervals.
For example, while 1000 vaccine volunteers are selected from a list of 5000 applicants, each applicant is given a number from 1 to 5000. A sample of 1000 volunteers can then be obtained by starting at 1 and selecting each participant on 10 to an item scale.
Nonprobability sampling
When the number of units in the population is either unknown or difficult to identify individuals , nonprobability sampling approaches are utilized in quantitative and qualitative research. Additionally, it is employed when you wish to limit the results’ applicability to a particular group or organization rather than the broader populace.
Besides the advantages of non-probability sampling, the most significant disadvantage is the possibility of sampling bias. As the sample selection process unfairly favors some population members over others. Here are some types of nonprobability sampling:
1. Convenience sampling
Convenience sampling comprises those who are easiest to research by the researcher. Researchers selected these samples only because they are simple to compile , and they did not think to choose a sample representative of the total population.
For example, researchers conducted a shopping mall response survey to understand a product manufacturer's likelihood of customers using the products. In this sampling method, sample participants are selected based on their proximity to the survey table and their willingness to participate in the research.
2. Snowball sampling
Snowball sampling is used to recruit participants through other participants if the population is difficult to reach. As you interact with additional individuals, your network of contacts "snowballs" in size.
For example, you are looking into local homeless people's experiences. Since there is no list of every homeless person in the city, probability sampling is not an option. One of the persons you meet agrees to participate in the research, and the homeless person refers you to other local homeless people he knows.
3. Purposive sampling
Purposive sampling is frequently employed in qualitative research when the researcher prefers to learn in-depth information about a particular phenomenon versus drawing general conclusions from statistics or when the population is relatively tiny and focused.
For instance, a researcher wants to learn more about how people with persistent headaches live. In such instances, they can choose a sample of people diagnosed with persistent headaches using purposive sampling.
- How to determine the right sample size
The sample size is crucial for reliable, statistically meaningful results and a smooth research operation. You should learn the fundamentals of the statistics involved to select the appropriate sample size , considering a few distinct elements that may affect your study.
1. Population size
The population size is the total number of individuals that can be included in the study. To determine the appropriate population size, you should be clear about who belongs or doesn’t belong in your group.
2. The margin of error (confidence interval)
Errors are inevitable in research studies. The margin of error is represented by a percentage, which is a statistical inference about the confidence that the number of respondents accurately represents the opinions of the whole population.
3. Confidence level
The confidence level value measures your degree of certainty on how closely a sample reflects the total population within your chosen margin of error. The most prevalent are the 90%, 95%, and 99% confidence intervals.
4. Standard deviation
The standard deviation indicates how much variation you can expect in your responses. A safe value to use as a guide is 0.5 , which denotes that significant sample size is required.
Sample size formula
You may select the appropriate sample size by considering various factors affecting your study. You may compute the sample using an online calculator or read on to learn how to do it by hand.
1. Discover the Z-score
The Z-score displays how far a certain ratio deviates from the mean by standard deviation. You should translate your degree of confidence into a Z-score.
For the most typical confidence levels, the Z-scores are as follows:
- 90% Z-score = 1.645
- 95% Z-score = 1.96
- 99% Z-score = 2.576
2. Apply the formula for the sample size
Use the following formula to perform the calculation manually.

- N = population size
- e = Margin of error
- z = z-score
- p = standard of deviation
For example, you select a 95% confidence level. Let the population size be 1000, and the margin of level be 5. Based on these data, your sample size would be 370.
- Frequently asked questions about sample
A sample is a particular group from which you will gather data. You should employ a sample when your population is sizable , spread geographically , or challenging . The population, sample, and sample frame are different from each other. Here are the frequently asked questions about the sample.
Population vs. sample
Sample and population are closely related concepts, so they can often be confused. We will explain the differences between them so that you can distinguish between the sample and population.
Population refers to the entire group of individuals about which you want to draw conclusions. On the other hand, sample refers to the group of people you will collect data from.
A sample is more manageable, minor, and representative of a bigger group. The sample size is always less than the total population size. When a population is too vast for all the members or observations to be included in the test, a sample is employed in statistical analysis.
Sample vs. sample frame
A sample is a group of participants chosen from a broader population of interest; it is an essential component of the research. On the other hand, sample frames are crucial for researchers to maintain organization and guarantee that the most recent data for a population is being used. Here are the differences between sample and sample frame:
The sample is a smaller group of people or units chosen from a larger population for a survey or research project. In contrast, a sample frame is an exhaustive enumeration of all the elements or people that comprise the population from which the sample is taken.
The sample is a subset of the population's elements chosen for research, whereas the sample frame is a comprehensive list or inventory of all population items.
- Key points to takeaway
In conclusion, a sample is a group or subset of persons or things chosen from a broader population to study or assess particular traits or behaviors. To guarantee that every member of the population has an equal chance of being chosen, the sample should be representative of the people from which it is collected or selected using a random sampling procedure.
Selecting the appropriate sample technique based on the research topic , budget , and available resources . Additionally, the accuracy and generalizability of the results are greatly influenced by the sample size.
This article has explained what a sample is in research methodology, what sample is in research examples, and how to determine the correct sample size. You can learn more about the research by reading this article.
Sena is a content writer at forms.app. She likes to read and write articles on different topics. Sena also likes to learn about different cultures and travel. She likes to study and learn different languages. Her specialty is linguistics, surveys, survey questions, and sampling methods.
- Form Features
- Data Collection
Table of Contents
Related posts.

100+ Random questions to ask (+ Free templates)
Defne Çobanoğlu

10+ Must-have tools for HR to boost team productivity
Yulia Guseva

20 Excellent persona interview questions (+Free example)
Şeyma Beyazçiçek
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Sampling Methods | Types, Techniques, & Examples
Sampling Methods | Types, Techniques, & Examples
Published on 3 May 2022 by Shona McCombes . Revised on 10 October 2022.
When you conduct research about a group of people, it’s rarely possible to collect data from every person in that group. Instead, you select a sample. The sample is the group of individuals who will actually participate in the research.
To draw valid conclusions from your results, you have to carefully decide how you will select a sample that is representative of the group as a whole. There are two types of sampling methods:
- Probability sampling involves random selection, allowing you to make strong statistical inferences about the whole group. It minimises the risk of selection bias .
- Non-probability sampling involves non-random selection based on convenience or other criteria, allowing you to easily collect data.
You should clearly explain how you selected your sample in the methodology section of your paper or thesis.
Table of contents
Population vs sample, probability sampling methods, non-probability sampling methods, frequently asked questions about sampling.
First, you need to understand the difference between a population and a sample , and identify the target population of your research.
- The population is the entire group that you want to draw conclusions about.
- The sample is the specific group of individuals that you will collect data from.
The population can be defined in terms of geographical location, age, income, and many other characteristics.

It is important to carefully define your target population according to the purpose and practicalities of your project.
If the population is very large, demographically mixed, and geographically dispersed, it might be difficult to gain access to a representative sample.
Sampling frame
The sampling frame is the actual list of individuals that the sample will be drawn from. Ideally, it should include the entire target population (and nobody who is not part of that population).
You are doing research on working conditions at Company X. Your population is all 1,000 employees of the company. Your sampling frame is the company’s HR database, which lists the names and contact details of every employee.
Sample size
The number of individuals you should include in your sample depends on various factors, including the size and variability of the population and your research design. There are different sample size calculators and formulas depending on what you want to achieve with statistical analysis .
Prevent plagiarism, run a free check.
Probability sampling means that every member of the population has a chance of being selected. It is mainly used in quantitative research . If you want to produce results that are representative of the whole population, probability sampling techniques are the most valid choice.
There are four main types of probability sample.

1. Simple random sampling
In a simple random sample , every member of the population has an equal chance of being selected. Your sampling frame should include the whole population.
To conduct this type of sampling, you can use tools like random number generators or other techniques that are based entirely on chance.
You want to select a simple random sample of 100 employees of Company X. You assign a number to every employee in the company database from 1 to 1000, and use a random number generator to select 100 numbers.
2. Systematic sampling
Systematic sampling is similar to simple random sampling, but it is usually slightly easier to conduct. Every member of the population is listed with a number, but instead of randomly generating numbers, individuals are chosen at regular intervals.
All employees of the company are listed in alphabetical order. From the first 10 numbers, you randomly select a starting point: number 6. From number 6 onwards, every 10th person on the list is selected (6, 16, 26, 36, and so on), and you end up with a sample of 100 people.
If you use this technique, it is important to make sure that there is no hidden pattern in the list that might skew the sample. For example, if the HR database groups employees by team, and team members are listed in order of seniority, there is a risk that your interval might skip over people in junior roles, resulting in a sample that is skewed towards senior employees.
3. Stratified sampling
Stratified sampling involves dividing the population into subpopulations that may differ in important ways. It allows you draw more precise conclusions by ensuring that every subgroup is properly represented in the sample.
To use this sampling method, you divide the population into subgroups (called strata) based on the relevant characteristic (e.g., gender, age range, income bracket, job role).
Based on the overall proportions of the population, you calculate how many people should be sampled from each subgroup. Then you use random or systematic sampling to select a sample from each subgroup.
The company has 800 female employees and 200 male employees. You want to ensure that the sample reflects the gender balance of the company, so you sort the population into two strata based on gender. Then you use random sampling on each group, selecting 80 women and 20 men, which gives you a representative sample of 100 people.
4. Cluster sampling
Cluster sampling also involves dividing the population into subgroups, but each subgroup should have similar characteristics to the whole sample. Instead of sampling individuals from each subgroup, you randomly select entire subgroups.
If it is practically possible, you might include every individual from each sampled cluster. If the clusters themselves are large, you can also sample individuals from within each cluster using one of the techniques above. This is called multistage sampling .
This method is good for dealing with large and dispersed populations, but there is more risk of error in the sample, as there could be substantial differences between clusters. It’s difficult to guarantee that the sampled clusters are really representative of the whole population.
The company has offices in 10 cities across the country (all with roughly the same number of employees in similar roles). You don’t have the capacity to travel to every office to collect your data, so you use random sampling to select 3 offices – these are your clusters.
In a non-probability sample , individuals are selected based on non-random criteria, and not every individual has a chance of being included.
This type of sample is easier and cheaper to access, but it has a higher risk of sampling bias . That means the inferences you can make about the population are weaker than with probability samples, and your conclusions may be more limited. If you use a non-probability sample, you should still aim to make it as representative of the population as possible.
Non-probability sampling techniques are often used in exploratory and qualitative research . In these types of research, the aim is not to test a hypothesis about a broad population, but to develop an initial understanding of a small or under-researched population.

1. Convenience sampling
A convenience sample simply includes the individuals who happen to be most accessible to the researcher.
This is an easy and inexpensive way to gather initial data, but there is no way to tell if the sample is representative of the population, so it can’t produce generalisable results.
You are researching opinions about student support services in your university, so after each of your classes, you ask your fellow students to complete a survey on the topic. This is a convenient way to gather data, but as you only surveyed students taking the same classes as you at the same level, the sample is not representative of all the students at your university.
2. Voluntary response sampling
Similar to a convenience sample, a voluntary response sample is mainly based on ease of access. Instead of the researcher choosing participants and directly contacting them, people volunteer themselves (e.g., by responding to a public online survey).
Voluntary response samples are always at least somewhat biased, as some people will inherently be more likely to volunteer than others.
You send out the survey to all students at your university and many students decide to complete it. This can certainly give you some insight into the topic, but the people who responded are more likely to be those who have strong opinions about the student support services, so you can’t be sure that their opinions are representative of all students.
3. Purposive sampling
Purposive sampling , also known as judgement sampling, involves the researcher using their expertise to select a sample that is most useful to the purposes of the research.
It is often used in qualitative research , where the researcher wants to gain detailed knowledge about a specific phenomenon rather than make statistical inferences, or where the population is very small and specific. An effective purposive sample must have clear criteria and rationale for inclusion.
You want to know more about the opinions and experiences of students with a disability at your university, so you purposely select a number of students with different support needs in order to gather a varied range of data on their experiences with student services.
4. Snowball sampling
If the population is hard to access, snowball sampling can be used to recruit participants via other participants. The number of people you have access to ‘snowballs’ as you get in contact with more people.
You are researching experiences of homelessness in your city. Since there is no list of all homeless people in the city, probability sampling isn’t possible. You meet one person who agrees to participate in the research, and she puts you in contact with other homeless people she knows in the area.
A sample is a subset of individuals from a larger population. Sampling means selecting the group that you will actually collect data from in your research.
For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
Statistical sampling allows you to test a hypothesis about the characteristics of a population. There are various sampling methods you can use to ensure that your sample is representative of the population as a whole.
Samples are used to make inferences about populations . Samples are easier to collect data from because they are practical, cost-effective, convenient, and manageable.
Probability sampling means that every member of the target population has a known chance of being included in the sample.
Probability sampling methods include simple random sampling , systematic sampling , stratified sampling , and cluster sampling .
In non-probability sampling , the sample is selected based on non-random criteria, and not every member of the population has a chance of being included.
Common non-probability sampling methods include convenience sampling , voluntary response sampling, purposive sampling , snowball sampling , and quota sampling .
Sampling bias occurs when some members of a population are systematically more likely to be selected in a sample than others.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
McCombes, S. (2022, October 10). Sampling Methods | Types, Techniques, & Examples. Scribbr. Retrieved 3 September 2024, from https://www.scribbr.co.uk/research-methods/sampling/
Is this article helpful?

Shona McCombes
Other students also liked, what is quantitative research | definition & methods, a quick guide to experimental design | 5 steps & examples, controlled experiments | methods & examples of control.
Educational resources and simple solutions for your research journey

What are Sampling Methods? Techniques, Types, and Examples
Every type of research includes samples from which inferences are drawn. The sample could be biological specimens or a subset of a specific group or population selected for analysis. The goal is often to conclude the entire population based on the characteristics observed in the sample. Now, the question comes to mind: how does one collect the samples? Answer: Using sampling methods. Various sampling strategies are available to researchers to define and collect samples that will form the basis of their research study.
In a study focusing on individuals experiencing anxiety, gathering data from the entire population is practically impossible due to the widespread prevalence of anxiety. Consequently, a sample is carefully selected—a subset of individuals meant to represent (or not in some cases accurately) the demographics of those experiencing anxiety. The study’s outcomes hinge significantly on the chosen sample, emphasizing the critical importance of a thoughtful and precise selection process. The conclusions drawn about the broader population rely heavily on the selected sample’s characteristics and diversity.
Table of Contents
What is sampling?
Sampling involves the strategic selection of individuals or a subset from a population, aiming to derive statistical inferences and predict the characteristics of the entire population. It offers a pragmatic and practical approach to examining the features of the whole population, which would otherwise be difficult to achieve because studying the total population is expensive, time-consuming, and often impossible. Market researchers use various sampling methods to collect samples from a large population to acquire relevant insights. The best sampling strategy for research is determined by criteria such as the purpose of the study, available resources (time and money), and research hypothesis.
For example, if a pet food manufacturer wants to investigate the positive impact of a new cat food on feline growth, studying all the cats in the country is impractical. In such cases, employing an appropriate sampling technique from the extensive dataset allows the researcher to focus on a manageable subset. This enables the researcher to study the growth-promoting effects of the new pet food. This article will delve into the standard sampling methods and explore the situations in which each is most appropriately applied.

What are sampling methods or sampling techniques?
Sampling methods or sampling techniques in research are statistical methods for selecting a sample representative of the whole population to study the population’s characteristics. Sampling methods serve as invaluable tools for researchers, enabling the collection of meaningful data and facilitating analysis to identify distinctive features of the people. Different sampling strategies can be used based on the characteristics of the population, the study purpose, and the available resources. Now that we understand why sampling methods are essential in research, we review the various sample methods in the following sections.
Types of sampling methods
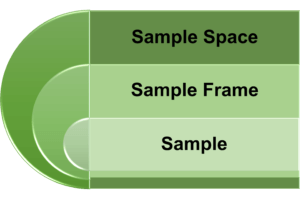
Before we go into the specifics of each sampling method, it’s vital to understand terms like sample, sample frame, and sample space. In probability theory, the sample space comprises all possible outcomes of a random experiment, while the sample frame is the list or source guiding sample selection in statistical research. The sample represents the group of individuals participating in the study, forming the basis for the research findings. Selecting the correct sample is critical to ensuring the validity and reliability of any research; the sample should be representative of the population.
There are two most common sampling methods:
- Probability sampling: A sampling method in which each unit or element in the population has an equal chance of being selected in the final sample. This is called random sampling, emphasizing the random and non-zero probability nature of selecting samples. Such a sampling technique ensures a more representative and unbiased sample, enabling robust inferences about the entire population.
- Non-probability sampling: Another sampling method is non-probability sampling, which involves collecting data conveniently through a non-random selection based on predefined criteria. This offers a straightforward way to gather data, although the resulting sample may or may not accurately represent the entire population.
Irrespective of the research method you opt for, it is essential to explicitly state the chosen sampling technique in the methodology section of your research article. Now, we will explore the different characteristics of both sampling methods, along with various subtypes falling under these categories.
What is probability sampling?
The probability sampling method is based on the probability theory, which means that the sample selection criteria involve some random selection. The probability sampling method provides an equal opportunity for all elements or units within the entire sample space to be chosen. While it can be labor-intensive and expensive, the advantage lies in its ability to offer a more accurate representation of the population, thereby enhancing confidence in the inferences drawn in the research.
Types of probability sampling
Various probability sampling methods exist, such as simple random sampling, systematic sampling, stratified sampling, and clustered sampling. Here, we provide detailed discussions and illustrative examples for each of these sampling methods:

- Simple random sampling: In simple random sampling, each individual has an equal probability of being chosen, and each selection is independent of the others. Because the choice is entirely based on chance, this is also known as the method of chance selection. In the simple random sampling method, the sample frame comprises the entire population.
For example, A fitness sports brand is launching a new protein drink and aims to select 20 individuals from a 200-person fitness center to try it. Employing a simple random sampling approach, each of the 200 people is assigned a unique identifier. Of these, 20 individuals are then chosen by generating random numbers between 1 and 200, either manually or through a computer program. Matching these numbers with the individuals creates a randomly selected group of 20 people. This method minimizes sampling bias and ensures a representative subset of the entire population under study.

- Systematic sampling: The systematic sampling approach involves selecting units or elements at regular intervals from an ordered list of the population. Because the starting point of this sampling method is chosen at random, it is more convenient than essential random sampling. For a better understanding, consider the following example.
For example, considering the previous model, individuals at the fitness facility are arranged alphabetically. The manufacturer then initiates the process by randomly selecting a starting point from the first ten positions, let’s say 8. Starting from the 8th position, every tenth person on the list is then chosen (e.g., 8, 18, 28, 38, and so forth) until a sample of 20 individuals is obtained.

- Stratified sampling: Stratified sampling divides the population into subgroups (strata), and random samples are drawn from each stratum in proportion to its size in the population. Stratified sampling provides improved representation because each subgroup that differs in significant ways is included in the final sample.
For example, Expanding on the previous simple random sampling example, suppose the manufacturer aims for a more comprehensive representation of genders in a sample of 200 people, consisting of 90 males, 80 females, and 30 others. The manufacturer categorizes the population into three gender strata (Male, Female, and Others). Within each group, random sampling is employed to select nine males, eight females, and three individuals from the others category, resulting in a well-rounded and representative sample of 200 individuals.
- Clustered sampling: In this sampling method, the population is divided into clusters, and then a random sample of clusters is included in the final sample. Clustered sampling, distinct from stratified sampling, involves subgroups (clusters) that exhibit characteristics similar to the whole sample. In the case of small clusters, all members can be included in the final sample, whereas for larger clusters, individuals within each cluster may be sampled using the sampling above methods. This approach is referred to as multistage sampling. This sampling method is well-suited for large and widely distributed populations; however, there is a potential risk of sample error because ensuring that the sampled clusters truly represent the entire population can be challenging.

For example, Researchers conducting a nationwide health study can select specific geographic clusters, like cities or regions, instead of trying to survey the entire population individually. Within each chosen cluster, they sample individuals, providing a representative subset without the logistical challenges of attempting a nationwide survey.
Use s of probability sampling
Probability sampling methods find widespread use across diverse research disciplines because of their ability to yield representative and unbiased samples. The advantages of employing probability sampling include the following:
- Representativeness
Probability sampling assures that every element in the population has a non-zero chance of being included in the sample, ensuring representativeness of the entire population and decreasing research bias to minimal to non-existent levels. The researcher can acquire higher-quality data via probability sampling, increasing confidence in the conclusions.
- Statistical inference
Statistical methods, like confidence intervals and hypothesis testing, depend on probability sampling to generalize findings from a sample to the broader population. Probability sampling methods ensure unbiased representation, allowing inferences about the population based on the characteristics of the sample.
- Precision and reliability
The use of probability sampling improves the precision and reliability of study results. Because the probability of selecting any single element/individual is known, the chance variations that may occur in non-probability sampling methods are reduced, resulting in more dependable and precise estimations.
- Generalizability
Probability sampling enables the researcher to generalize study findings to the entire population from which they were derived. The results produced through probability sampling methods are more likely to be applicable to the larger population, laying the foundation for making broad predictions or recommendations.
- Minimization of Selection Bias
By ensuring that each member of the population has an equal chance of being selected in the sample, probability sampling lowers the possibility of selection bias. This reduces the impact of systematic errors that may occur in non-probability sampling methods, where data may be skewed toward a specific demographic due to inadequate representation of each segment of the population.
What is non-probability sampling?
Non-probability sampling methods involve selecting individuals based on non-random criteria, often relying on the researcher’s judgment or predefined criteria. While it is easier and more economical, it tends to introduce sampling bias, resulting in weaker inferences compared to probability sampling techniques in research.
Types of Non-probability Sampling
Non-probability sampling methods are further classified as convenience sampling, consecutive sampling, quota sampling, purposive or judgmental sampling, and snowball sampling. Let’s explore these types of sampling methods in detail.
- Convenience sampling: In convenience sampling, individuals are recruited directly from the population based on the accessibility and proximity to the researcher. It is a simple, inexpensive, and practical method of sample selection, yet convenience sampling suffers from both sampling and selection bias due to a lack of appropriate population representation.

For example, imagine you’re a researcher investigating smartphone usage patterns in your city. The most convenient way to select participants is by approaching people in a shopping mall on a weekday afternoon. However, this convenience sampling method may not be an accurate representation of the city’s overall smartphone usage patterns as the sample is limited to individuals present at the mall during weekdays, excluding those who visit on other days or never visit the mall.
- Consecutive sampling: Participants in consecutive sampling (or sequential sampling) are chosen based on their availability and desire to participate in the study as they become available. This strategy entails sequentially recruiting individuals who fulfill the researcher’s requirements.
For example, In researching the prevalence of stroke in a hospital, instead of randomly selecting patients from the entire population, the researcher can opt to include all eligible patients admitted over three months. Participants are then consecutively recruited upon admission during that timeframe, forming the study sample.
- Quota sampling: The selection of individuals in quota sampling is based on non-random selection criteria in which only participants with certain traits or proportions that are representative of the population are included. Quota sampling involves setting predetermined quotas for specific subgroups based on key demographics or other relevant characteristics. This sampling method employs dividing the population into mutually exclusive subgroups and then selecting sample units until the set quota is reached.

For example, In a survey on a college campus to assess student interest in a new policy, the researcher should establish quotas aligned with the distribution of student majors, ensuring representation from various academic disciplines. If the campus has 20% biology majors, 30% engineering majors, 20% business majors, and 30% liberal arts majors, participants should be recruited to mirror these proportions.
- Purposive or judgmental sampling: In purposive sampling, the researcher leverages expertise to select a sample relevant to the study’s specific questions. This sampling method is commonly applied in qualitative research, mainly when aiming to understand a particular phenomenon, and is suitable for smaller population sizes.

For example, imagine a researcher who wants to study public policy issues for a focus group. The researcher might purposely select participants with expertise in economics, law, and public administration to take advantage of their knowledge and ensure a depth of understanding.
- Snowball sampling: This sampling method is used when accessing the population is challenging. It involves collecting the sample through a chain-referral process, where each recruited candidate aids in finding others. These candidates share common traits, representing the targeted population. This method is often used in qualitative research, particularly when studying phenomena related to stigmatized or hidden populations.

For example, In a study focusing on understanding the experiences and challenges of individuals in hidden or stigmatized communities (e.g., LGBTQ+ individuals in specific cultural contexts), the snowball sampling technique can be employed. The researcher initiates contact with one community member, who then assists in identifying additional candidates until the desired sample size is achieved.
Uses of non-probability sampling
Non-probability sampling approaches are employed in qualitative or exploratory research where the goal is to investigate underlying population traits rather than generalizability. Non-probability sampling methods are also helpful for the following purposes:
- Generating a hypothesis
In the initial stages of exploratory research, non-probability methods such as purposive or convenience allow researchers to quickly gather information and generate hypothesis that helps build a future research plan.
- Qualitative research
Qualitative research is usually focused on understanding the depth and complexity of human experiences, behaviors, and perspectives. Non-probability methods like purposive or snowball sampling are commonly used to select participants with specific traits that are relevant to the research question.
- Convenience and pragmatism
Non-probability sampling methods are valuable when resource and time are limited or when preliminary data is required to test the pilot study. For example, conducting a survey at a local shopping mall to gather opinions on a consumer product due to the ease of access to potential participants.
Probability vs Non-probability Sampling Methods
| Selection of participants | Random selection of participants from the population using randomization methods | Non-random selection of participants from the population based on convenience or criteria |
| Representativeness | Likely to yield a representative sample of the whole population allowing for generalizations | May not yield a representative sample of the whole population; poor generalizability |
| Precision and accuracy | Provides more precise and accurate estimates of population characteristics | May have less precision and accuracy due to non-random selection |
| Bias | Minimizes selection bias | May introduce selection bias if criteria are subjective and not well-defined |
| Statistical inference | Suited for statistical inference and hypothesis testing and for making generalization to the population | Less suited for statistical inference and hypothesis testing on the population |
| Application | Useful for quantitative research where generalizability is crucial | Commonly used in qualitative and exploratory research where in-depth insights are the goal |
Frequently asked questions
- What is multistage sampling ? Multistage sampling is a form of probability sampling approach that involves the progressive selection of samples in stages, going from larger clusters to a small number of participants, making it suited for large-scale research with enormous population lists.
- What are the methods of probability sampling? Probability sampling methods are simple random sampling, stratified random sampling, systematic sampling, cluster sampling, and multistage sampling.
- How to decide which type of sampling method to use? Choose a sampling method based on the goals, population, and resources. Probability for statistics and non-probability for efficiency or qualitative insights can be considered . Also, consider the population characteristics, size, and alignment with study objectives.
- What are the methods of non-probability sampling? Non-probability sampling methods are convenience sampling, consecutive sampling, purposive sampling, snowball sampling, and quota sampling.
- Why are sampling methods used in research? Sampling methods in research are employed to efficiently gather representative data from a subset of a larger population, enabling valid conclusions and generalizations while minimizing costs and time.
R Discovery is a literature search and research reading platform that accelerates your research discovery journey by keeping you updated on the latest, most relevant scholarly content. With 250M+ research articles sourced from trusted aggregators like CrossRef, Unpaywall, PubMed, PubMed Central, Open Alex and top publishing houses like Springer Nature, JAMA, IOP, Taylor & Francis, NEJM, BMJ, Karger, SAGE, Emerald Publishing and more, R Discovery puts a world of research at your fingertips.
Try R Discovery Prime FREE for 1 week or upgrade at just US$72 a year to access premium features that let you listen to research on the go, read in your language, collaborate with peers, auto sync with reference managers, and much more. Choose a simpler, smarter way to find and read research – Download the app and start your free 7-day trial today !
Related Posts

Research in Shorts: R Discovery’s New Feature Helps Academics Assess Relevant Papers in 2mins

Research Paper Appendix: Format and Examples
Chapter 5. Sampling
Introduction.
Most Americans will experience unemployment at some point in their lives. Sarah Damaske ( 2021 ) was interested in learning about how men and women experience unemployment differently. To answer this question, she interviewed unemployed people. After conducting a “pilot study” with twenty interviewees, she realized she was also interested in finding out how working-class and middle-class persons experienced unemployment differently. She found one hundred persons through local unemployment offices. She purposefully selected a roughly equal number of men and women and working-class and middle-class persons for the study. This would allow her to make the kinds of comparisons she was interested in. She further refined her selection of persons to interview:
I decided that I needed to be able to focus my attention on gender and class; therefore, I interviewed only people born between 1962 and 1987 (ages 28–52, the prime working and child-rearing years), those who worked full-time before their job loss, those who experienced an involuntary job loss during the past year, and those who did not lose a job for cause (e.g., were not fired because of their behavior at work). ( 244 )
The people she ultimately interviewed compose her sample. They represent (“sample”) the larger population of the involuntarily unemployed. This “theoretically informed stratified sampling design” allowed Damaske “to achieve relatively equal distribution of participation across gender and class,” but it came with some limitations. For one, the unemployment centers were located in primarily White areas of the country, so there were very few persons of color interviewed. Qualitative researchers must make these kinds of decisions all the time—who to include and who not to include. There is never an absolutely correct decision, as the choice is linked to the particular research question posed by the particular researcher, although some sampling choices are more compelling than others. In this case, Damaske made the choice to foreground both gender and class rather than compare all middle-class men and women or women of color from different class positions or just talk to White men. She leaves the door open for other researchers to sample differently. Because science is a collective enterprise, it is most likely someone will be inspired to conduct a similar study as Damaske’s but with an entirely different sample.
This chapter is all about sampling. After you have developed a research question and have a general idea of how you will collect data (observations or interviews), how do you go about actually finding people and sites to study? Although there is no “correct number” of people to interview, the sample should follow the research question and research design. You might remember studying sampling in a quantitative research course. Sampling is important here too, but it works a bit differently. Unlike quantitative research, qualitative research involves nonprobability sampling. This chapter explains why this is so and what qualities instead make a good sample for qualitative research.
Quick Terms Refresher
- The population is the entire group that you want to draw conclusions about.
- The sample is the specific group of individuals that you will collect data from.
- Sampling frame is the actual list of individuals that the sample will be drawn from. Ideally, it should include the entire target population (and nobody who is not part of that population).
- Sample size is how many individuals (or units) are included in your sample.
The “Who” of Your Research Study
After you have turned your general research interest into an actual research question and identified an approach you want to take to answer that question, you will need to specify the people you will be interviewing or observing. In most qualitative research, the objects of your study will indeed be people. In some cases, however, your objects might be content left by people (e.g., diaries, yearbooks, photographs) or documents (official or unofficial) or even institutions (e.g., schools, medical centers) and locations (e.g., nation-states, cities). Chances are, whatever “people, places, or things” are the objects of your study, you will not really be able to talk to, observe, or follow every single individual/object of the entire population of interest. You will need to create a sample of the population . Sampling in qualitative research has different purposes and goals than sampling in quantitative research. Sampling in both allows you to say something of interest about a population without having to include the entire population in your sample.
We begin this chapter with the case of a population of interest composed of actual people. After we have a better understanding of populations and samples that involve real people, we’ll discuss sampling in other types of qualitative research, such as archival research, content analysis, and case studies. We’ll then move to a larger discussion about the difference between sampling in qualitative research generally versus quantitative research, then we’ll move on to the idea of “theoretical” generalizability, and finally, we’ll conclude with some practical tips on the correct “number” to include in one’s sample.
Sampling People
To help think through samples, let’s imagine we want to know more about “vaccine hesitancy.” We’ve all lived through 2020 and 2021, and we know that a sizable number of people in the United States (and elsewhere) were slow to accept vaccines, even when these were freely available. By some accounts, about one-third of Americans initially refused vaccination. Why is this so? Well, as I write this in the summer of 2021, we know that some people actively refused the vaccination, thinking it was harmful or part of a government plot. Others were simply lazy or dismissed the necessity. And still others were worried about harmful side effects. The general population of interest here (all adult Americans who were not vaccinated by August 2021) may be as many as eighty million people. We clearly cannot talk to all of them. So we will have to narrow the number to something manageable. How can we do this?

First, we have to think about our actual research question and the form of research we are conducting. I am going to begin with a quantitative research question. Quantitative research questions tend to be simpler to visualize, at least when we are first starting out doing social science research. So let us say we want to know what percentage of each kind of resistance is out there and how race or class or gender affects vaccine hesitancy. Again, we don’t have the ability to talk to everyone. But harnessing what we know about normal probability distributions (see quantitative methods for more on this), we can find this out through a sample that represents the general population. We can’t really address these particular questions if we only talk to White women who go to college with us. And if you are really trying to generalize the specific findings of your sample to the larger population, you will have to employ probability sampling , a sampling technique where a researcher sets a selection of a few criteria and chooses members of a population randomly. Why randomly? If truly random, all the members have an equal opportunity to be a part of the sample, and thus we avoid the problem of having only our friends and neighbors (who may be very different from other people in the population) in the study. Mathematically, there is going to be a certain number that will be large enough to allow us to generalize our particular findings from our sample population to the population at large. It might surprise you how small that number can be. Election polls of no more than one thousand people are routinely used to predict actual election outcomes of millions of people. Below that number, however, you will not be able to make generalizations. Talking to five people at random is simply not enough people to predict a presidential election.
In order to answer quantitative research questions of causality, one must employ probability sampling. Quantitative researchers try to generalize their findings to a larger population. Samples are designed with that in mind. Qualitative researchers ask very different questions, though. Qualitative research questions are not about “how many” of a certain group do X (in this case, what percentage of the unvaccinated hesitate for concern about safety rather than reject vaccination on political grounds). Qualitative research employs nonprobability sampling . By definition, not everyone has an equal opportunity to be included in the sample. The researcher might select White women they go to college with to provide insight into racial and gender dynamics at play. Whatever is found by doing so will not be generalizable to everyone who has not been vaccinated, or even all White women who have not been vaccinated, or even all White women who have not been vaccinated who are in this particular college. That is not the point of qualitative research at all. This is a really important distinction, so I will repeat in bold: Qualitative researchers are not trying to statistically generalize specific findings to a larger population . They have not failed when their sample cannot be generalized, as that is not the point at all.
In the previous paragraph, I said it would be perfectly acceptable for a qualitative researcher to interview five White women with whom she goes to college about their vaccine hesitancy “to provide insight into racial and gender dynamics at play.” The key word here is “insight.” Rather than use a sample as a stand-in for the general population, as quantitative researchers do, the qualitative researcher uses the sample to gain insight into a process or phenomenon. The qualitative researcher is not going to be content with simply asking each of the women to state her reason for not being vaccinated and then draw conclusions that, because one in five of these women were concerned about their health, one in five of all people were also concerned about their health. That would be, frankly, a very poor study indeed. Rather, the qualitative researcher might sit down with each of the women and conduct a lengthy interview about what the vaccine means to her, why she is hesitant, how she manages her hesitancy (how she explains it to her friends), what she thinks about others who are unvaccinated, what she thinks of those who have been vaccinated, and what she knows or thinks she knows about COVID-19. The researcher might include specific interview questions about the college context, about their status as White women, about the political beliefs they hold about racism in the US, and about how their own political affiliations may or may not provide narrative scripts about “protective whiteness.” There are many interesting things to ask and learn about and many things to discover. Where a quantitative researcher begins with clear parameters to set their population and guide their sample selection process, the qualitative researcher is discovering new parameters, making it impossible to engage in probability sampling.
Looking at it this way, sampling for qualitative researchers needs to be more strategic. More theoretically informed. What persons can be interviewed or observed that would provide maximum insight into what is still unknown? In other words, qualitative researchers think through what cases they could learn the most from, and those are the cases selected to study: “What would be ‘bias’ in statistical sampling, and therefore a weakness, becomes intended focus in qualitative sampling, and therefore a strength. The logic and power of purposeful sampling like in selecting information-rich cases for study in depth. Information-rich cases are those from which one can learn a great deal about issues of central importance to the purpose of the inquiry, thus the term purposeful sampling” ( Patton 2002:230 ; emphases in the original).
Before selecting your sample, though, it is important to clearly identify the general population of interest. You need to know this before you can determine the sample. In our example case, it is “adult Americans who have not yet been vaccinated.” Depending on the specific qualitative research question, however, it might be “adult Americans who have been vaccinated for political reasons” or even “college students who have not been vaccinated.” What insights are you seeking? Do you want to know how politics is affecting vaccination? Or do you want to understand how people manage being an outlier in a particular setting (unvaccinated where vaccinations are heavily encouraged if not required)? More clearly stated, your population should align with your research question . Think back to the opening story about Damaske’s work studying the unemployed. She drew her sample narrowly to address the particular questions she was interested in pursuing. Knowing your questions or, at a minimum, why you are interested in the topic will allow you to draw the best sample possible to achieve insight.
Once you have your population in mind, how do you go about getting people to agree to be in your sample? In qualitative research, it is permissible to find people by convenience. Just ask for people who fit your sample criteria and see who shows up. Or reach out to friends and colleagues and see if they know anyone that fits. Don’t let the name convenience sampling mislead you; this is not exactly “easy,” and it is certainly a valid form of sampling in qualitative research. The more unknowns you have about what you will find, the more convenience sampling makes sense. If you don’t know how race or class or political affiliation might matter, and your population is unvaccinated college students, you can construct a sample of college students by placing an advertisement in the student paper or posting a flyer on a notice board. Whoever answers is your sample. That is what is meant by a convenience sample. A common variation of convenience sampling is snowball sampling . This is particularly useful if your target population is hard to find. Let’s say you posted a flyer about your study and only two college students responded. You could then ask those two students for referrals. They tell their friends, and those friends tell other friends, and, like a snowball, your sample gets bigger and bigger.
Researcher Note
Gaining Access: When Your Friend Is Your Research Subject
My early experience with qualitative research was rather unique. At that time, I needed to do a project that required me to interview first-generation college students, and my friends, with whom I had been sharing a dorm for two years, just perfectly fell into the sample category. Thus, I just asked them and easily “gained my access” to the research subject; I know them, we are friends, and I am part of them. I am an insider. I also thought, “Well, since I am part of the group, I can easily understand their language and norms, I can capture their honesty, read their nonverbal cues well, will get more information, as they will be more opened to me because they trust me.” All in all, easy access with rich information. But, gosh, I did not realize that my status as an insider came with a price! When structuring the interview questions, I began to realize that rather than focusing on the unique experiences of my friends, I mostly based the questions on my own experiences, assuming we have similar if not the same experiences. I began to struggle with my objectivity and even questioned my role; am I doing this as part of the group or as a researcher? I came to know later that my status as an insider or my “positionality” may impact my research. It not only shapes the process of data collection but might heavily influence my interpretation of the data. I came to realize that although my inside status came with a lot of benefits (especially for access), it could also bring some drawbacks.
—Dede Setiono, PhD student focusing on international development and environmental policy, Oregon State University
The more you know about what you might find, the more strategic you can be. If you wanted to compare how politically conservative and politically liberal college students explained their vaccine hesitancy, for example, you might construct a sample purposively, finding an equal number of both types of students so that you can make those comparisons in your analysis. This is what Damaske ( 2021 ) did. You could still use convenience or snowball sampling as a way of recruitment. Post a flyer at the conservative student club and then ask for referrals from the one student that agrees to be interviewed. As with convenience sampling, there are variations of purposive sampling as well as other names used (e.g., judgment, quota, stratified, criterion, theoretical). Try not to get bogged down in the nomenclature; instead, focus on identifying the general population that matches your research question and then using a sampling method that is most likely to provide insight, given the types of questions you have.
There are all kinds of ways of being strategic with sampling in qualitative research. Here are a few of my favorite techniques for maximizing insight:
- Consider using “extreme” or “deviant” cases. Maybe your college houses a prominent anti-vaxxer who has written about and demonstrated against the college’s policy on vaccines. You could learn a lot from that single case (depending on your research question, of course).
- Consider “intensity”: people and cases and circumstances where your questions are more likely to feature prominently (but not extremely or deviantly). For example, you could compare those who volunteer at local Republican and Democratic election headquarters during an election season in a study on why party matters. Those who volunteer are more likely to have something to say than those who are more apathetic.
- Maximize variation, as with the case of “politically liberal” versus “politically conservative,” or include an array of social locations (young vs. old; Northwest vs. Southeast region). This kind of heterogeneity sampling can capture and describe the central themes that cut across the variations: any common patterns that emerge, even in this wildly mismatched sample, are probably important to note!
- Rather than maximize the variation, you could select a small homogenous sample to describe some particular subgroup in depth. Focus groups are often the best form of data collection for homogeneity sampling.
- Think about which cases are “critical” or politically important—ones that “if it happens here, it would happen anywhere” or a case that is politically sensitive, as with the single “blue” (Democratic) county in a “red” (Republican) state. In both, you are choosing a site that would yield the most information and have the greatest impact on the development of knowledge.
- On the other hand, sometimes you want to select the “typical”—the typical college student, for example. You are trying to not generalize from the typical but illustrate aspects that may be typical of this case or group. When selecting for typicality, be clear with yourself about why the typical matches your research questions (and who might be excluded or marginalized in doing so).
- Finally, it is often a good idea to look for disconfirming cases : if you are at the stage where you have a hypothesis (of sorts), you might select those who do not fit your hypothesis—you will surely learn something important there. They may be “exceptions that prove the rule” or exceptions that force you to alter your findings in order to make sense of these additional cases.
In addition to all these sampling variations, there is the theoretical approach taken by grounded theorists in which the researcher samples comparative people (or events) on the basis of their potential to represent important theoretical constructs. The sample, one can say, is by definition representative of the phenomenon of interest. It accompanies the constant comparative method of analysis. In the words of the funders of Grounded Theory , “Theoretical sampling is sampling on the basis of the emerging concepts, with the aim being to explore the dimensional range or varied conditions along which the properties of the concepts vary” ( Strauss and Corbin 1998:73 ).
When Your Population is Not Composed of People
I think it is easiest for most people to think of populations and samples in terms of people, but sometimes our units of analysis are not actually people. They could be places or institutions. Even so, you might still want to talk to people or observe the actions of people to understand those places or institutions. Or not! In the case of content analyses (see chapter 17), you won’t even have people involved at all but rather documents or films or photographs or news clippings. Everything we have covered about sampling applies to other units of analysis too. Let’s work through some examples.
Case Studies
When constructing a case study, it is helpful to think of your cases as sample populations in the same way that we considered people above. If, for example, you are comparing campus climates for diversity, your overall population may be “four-year college campuses in the US,” and from there you might decide to study three college campuses as your sample. Which three? Will you use purposeful sampling (perhaps [1] selecting three colleges in Oregon that are different sizes or [2] selecting three colleges across the US located in different political cultures or [3] varying the three colleges by racial makeup of the student body)? Or will you select three colleges at random, out of convenience? There are justifiable reasons for all approaches.
As with people, there are different ways of maximizing insight in your sample selection. Think about the following rationales: typical, diverse, extreme, deviant, influential, crucial, or even embodying a particular “pathway” ( Gerring 2008 ). When choosing a case or particular research site, Rubin ( 2021 ) suggests you bear in mind, first, what you are leaving out by selecting this particular case/site; second, what you might be overemphasizing by studying this case/site and not another; and, finally, whether you truly need to worry about either of those things—“that is, what are the sources of bias and how bad are they for what you are trying to do?” ( 89 ).
Once you have selected your cases, you may still want to include interviews with specific people or observations at particular sites within those cases. Then you go through possible sampling approaches all over again to determine which people will be contacted.
Content: Documents, Narrative Accounts, And So On
Although not often discussed as sampling, your selection of documents and other units to use in various content/historical analyses is subject to similar considerations. When you are asking quantitative-type questions (percentages and proportionalities of a general population), you will want to follow probabilistic sampling. For example, I created a random sample of accounts posted on the website studentloanjustice.org to delineate the types of problems people were having with student debt ( Hurst 2007 ). Even though my data was qualitative (narratives of student debt), I was actually asking a quantitative-type research question, so it was important that my sample was representative of the larger population (debtors who posted on the website). On the other hand, when you are asking qualitative-type questions, the selection process should be very different. In that case, use nonprobabilistic techniques, either convenience (where you are really new to this data and do not have the ability to set comparative criteria or even know what a deviant case would be) or some variant of purposive sampling. Let’s say you were interested in the visual representation of women in media published in the 1950s. You could select a national magazine like Time for a “typical” representation (and for its convenience, as all issues are freely available on the web and easy to search). Or you could compare one magazine known for its feminist content versus one antifeminist. The point is, sample selection is important even when you are not interviewing or observing people.
Goals of Qualitative Sampling versus Goals of Quantitative Sampling
We have already discussed some of the differences in the goals of quantitative and qualitative sampling above, but it is worth further discussion. The quantitative researcher seeks a sample that is representative of the population of interest so that they may properly generalize the results (e.g., if 80 percent of first-gen students in the sample were concerned with costs of college, then we can say there is a strong likelihood that 80 percent of first-gen students nationally are concerned with costs of college). The qualitative researcher does not seek to generalize in this way . They may want a representative sample because they are interested in typical responses or behaviors of the population of interest, but they may very well not want a representative sample at all. They might want an “extreme” or deviant case to highlight what could go wrong with a particular situation, or maybe they want to examine just one case as a way of understanding what elements might be of interest in further research. When thinking of your sample, you will have to know why you are selecting the units, and this relates back to your research question or sets of questions. It has nothing to do with having a representative sample to generalize results. You may be tempted—or it may be suggested to you by a quantitatively minded member of your committee—to create as large and representative a sample as you possibly can to earn credibility from quantitative researchers. Ignore this temptation or suggestion. The only thing you should be considering is what sample will best bring insight into the questions guiding your research. This has implications for the number of people (or units) in your study as well, which is the topic of the next section.
What is the Correct “Number” to Sample?
Because we are not trying to create a generalizable representative sample, the guidelines for the “number” of people to interview or news stories to code are also a bit more nebulous. There are some brilliant insightful studies out there with an n of 1 (meaning one person or one account used as the entire set of data). This is particularly so in the case of autoethnography, a variation of ethnographic research that uses the researcher’s own subject position and experiences as the basis of data collection and analysis. But it is true for all forms of qualitative research. There are no hard-and-fast rules here. The number to include is what is relevant and insightful to your particular study.
That said, humans do not thrive well under such ambiguity, and there are a few helpful suggestions that can be made. First, many qualitative researchers talk about “saturation” as the end point for data collection. You stop adding participants when you are no longer getting any new information (or so very little that the cost of adding another interview subject or spending another day in the field exceeds any likely benefits to the research). The term saturation was first used here by Glaser and Strauss ( 1967 ), the founders of Grounded Theory. Here is their explanation: “The criterion for judging when to stop sampling the different groups pertinent to a category is the category’s theoretical saturation . Saturation means that no additional data are being found whereby the sociologist can develop properties of the category. As he [or she] sees similar instances over and over again, the researcher becomes empirically confident that a category is saturated. [They go] out of [their] way to look for groups that stretch diversity of data as far as possible, just to make certain that saturation is based on the widest possible range of data on the category” ( 61 ).
It makes sense that the term was developed by grounded theorists, since this approach is rather more open-ended than other approaches used by qualitative researchers. With so much left open, having a guideline of “stop collecting data when you don’t find anything new” is reasonable. However, saturation can’t help much when first setting out your sample. How do you know how many people to contact to interview? What number will you put down in your institutional review board (IRB) protocol (see chapter 8)? You may guess how many people or units it will take to reach saturation, but there really is no way to know in advance. The best you can do is think about your population and your questions and look at what others have done with similar populations and questions.
Here are some suggestions to use as a starting point: For phenomenological studies, try to interview at least ten people for each major category or group of people . If you are comparing male-identified, female-identified, and gender-neutral college students in a study on gender regimes in social clubs, that means you might want to design a sample of thirty students, ten from each group. This is the minimum suggested number. Damaske’s ( 2021 ) sample of one hundred allows room for up to twenty-five participants in each of four “buckets” (e.g., working-class*female, working-class*male, middle-class*female, middle-class*male). If there is more than one comparative group (e.g., you are comparing students attending three different colleges, and you are comparing White and Black students in each), you can sometimes reduce the number for each group in your sample to five for, in this case, thirty total students. But that is really a bare minimum you will want to go. A lot of people will not trust you with only “five” cases in a bucket. Lareau ( 2021:24 ) advises a minimum of seven or nine for each bucket (or “cell,” in her words). The point is to think about what your analyses might look like and how comfortable you will be with a certain number of persons fitting each category.
Because qualitative research takes so much time and effort, it is rare for a beginning researcher to include more than thirty to fifty people or units in the study. You may not be able to conduct all the comparisons you might want simply because you cannot manage a larger sample. In that case, the limits of who you can reach or what you can include may influence you to rethink an original overcomplicated research design. Rather than include students from every racial group on a campus, for example, you might want to sample strategically, thinking about the most contrast (insightful), possibly excluding majority-race (White) students entirely, and simply using previous literature to fill in gaps in our understanding. For example, one of my former students was interested in discovering how race and class worked at a predominantly White institution (PWI). Due to time constraints, she simplified her study from an original sample frame of middle-class and working-class domestic Black and international African students (four buckets) to a sample frame of domestic Black and international African students (two buckets), allowing the complexities of class to come through individual accounts rather than from part of the sample frame. She wisely decided not to include White students in the sample, as her focus was on how minoritized students navigated the PWI. She was able to successfully complete her project and develop insights from the data with fewer than twenty interviewees. [1]
But what if you had unlimited time and resources? Would it always be better to interview more people or include more accounts, documents, and units of analysis? No! Your sample size should reflect your research question and the goals you have set yourself. Larger numbers can sometimes work against your goals. If, for example, you want to help bring out individual stories of success against the odds, adding more people to the analysis can end up drowning out those individual stories. Sometimes, the perfect size really is one (or three, or five). It really depends on what you are trying to discover and achieve in your study. Furthermore, studies of one hundred or more (people, documents, accounts, etc.) can sometimes be mistaken for quantitative research. Inevitably, the large sample size will push the researcher into simplifying the data numerically. And readers will begin to expect generalizability from such a large sample.
To summarize, “There are no rules for sample size in qualitative inquiry. Sample size depends on what you want to know, the purpose of the inquiry, what’s at stake, what will be useful, what will have credibility, and what can be done with available time and resources” ( Patton 2002:244 ).
How did you find/construct a sample?
Since qualitative researchers work with comparatively small sample sizes, getting your sample right is rather important. Yet it is also difficult to accomplish. For instance, a key question you need to ask yourself is whether you want a homogeneous or heterogeneous sample. In other words, do you want to include people in your study who are by and large the same, or do you want to have diversity in your sample?
For many years, I have studied the experiences of students who were the first in their families to attend university. There is a rather large number of sampling decisions I need to consider before starting the study. (1) Should I only talk to first-in-family students, or should I have a comparison group of students who are not first-in-family? (2) Do I need to strive for a gender distribution that matches undergraduate enrollment patterns? (3) Should I include participants that reflect diversity in gender identity and sexuality? (4) How about racial diversity? First-in-family status is strongly related to some ethnic or racial identity. (5) And how about areas of study?
As you can see, if I wanted to accommodate all these differences and get enough study participants in each category, I would quickly end up with a sample size of hundreds, which is not feasible in most qualitative research. In the end, for me, the most important decision was to maximize the voices of first-in-family students, which meant that I only included them in my sample. As for the other categories, I figured it was going to be hard enough to find first-in-family students, so I started recruiting with an open mind and an understanding that I may have to accept a lack of gender, sexuality, or racial diversity and then not be able to say anything about these issues. But I would definitely be able to speak about the experiences of being first-in-family.
—Wolfgang Lehmann, author of “Habitus Transformation and Hidden Injuries”
Examples of “Sample” Sections in Journal Articles
Think about some of the studies you have read in college, especially those with rich stories and accounts about people’s lives. Do you know how the people were selected to be the focus of those stories? If the account was published by an academic press (e.g., University of California Press or Princeton University Press) or in an academic journal, chances are that the author included a description of their sample selection. You can usually find these in a methodological appendix (book) or a section on “research methods” (article).
Here are two examples from recent books and one example from a recent article:
Example 1 . In It’s Not like I’m Poor: How Working Families Make Ends Meet in a Post-welfare World , the research team employed a mixed methods approach to understand how parents use the earned income tax credit, a refundable tax credit designed to provide relief for low- to moderate-income working people ( Halpern-Meekin et al. 2015 ). At the end of their book, their first appendix is “Introduction to Boston and the Research Project.” After describing the context of the study, they include the following description of their sample selection:
In June 2007, we drew 120 names at random from the roughly 332 surveys we gathered between February and April. Within each racial and ethnic group, we aimed for one-third married couples with children and two-thirds unmarried parents. We sent each of these families a letter informing them of the opportunity to participate in the in-depth portion of our study and then began calling the home and cell phone numbers they provided us on the surveys and knocking on the doors of the addresses they provided.…In the end, we interviewed 115 of the 120 families originally selected for the in-depth interview sample (the remaining five families declined to participate). ( 22 )
Was their sample selection based on convenience or purpose? Why do you think it was important for them to tell you that five families declined to be interviewed? There is actually a trick here, as the names were pulled randomly from a survey whose sample design was probabilistic. Why is this important to know? What can we say about the representativeness or the uniqueness of whatever findings are reported here?
Example 2 . In When Diversity Drops , Park ( 2013 ) examines the impact of decreasing campus diversity on the lives of college students. She does this through a case study of one student club, the InterVarsity Christian Fellowship (IVCF), at one university (“California University,” a pseudonym). Here is her description:
I supplemented participant observation with individual in-depth interviews with sixty IVCF associates, including thirty-four current students, eight former and current staff members, eleven alumni, and seven regional or national staff members. The racial/ethnic breakdown was twenty-five Asian Americans (41.6 percent), one Armenian (1.6 percent), twelve people who were black (20.0 percent), eight Latino/as (13.3 percent), three South Asian Americans (5.0 percent), and eleven people who were white (18.3 percent). Twenty-nine were men, and thirty-one were women. Looking back, I note that the higher number of Asian Americans reflected both the group’s racial/ethnic composition and my relative ease about approaching them for interviews. ( 156 )
How can you tell this is a convenience sample? What else do you note about the sample selection from this description?
Example 3. The last example is taken from an article published in the journal Research in Higher Education . Published articles tend to be more formal than books, at least when it comes to the presentation of qualitative research. In this article, Lawson ( 2021 ) is seeking to understand why female-identified college students drop out of majors that are dominated by male-identified students (e.g., engineering, computer science, music theory). Here is the entire relevant section of the article:
Method Participants Data were collected as part of a larger study designed to better understand the daily experiences of women in MDMs [male-dominated majors].…Participants included 120 students from a midsize, Midwestern University. This sample included 40 women and 40 men from MDMs—defined as any major where at least 2/3 of students are men at both the university and nationally—and 40 women from GNMs—defined as any may where 40–60% of students are women at both the university and nationally.… Procedure A multi-faceted approach was used to recruit participants; participants were sent targeted emails (obtained based on participants’ reported gender and major listings), campus-wide emails sent through the University’s Communication Center, flyers, and in-class presentations. Recruitment materials stated that the research focused on the daily experiences of college students, including classroom experiences, stressors, positive experiences, departmental contexts, and career aspirations. Interested participants were directed to email the study coordinator to verify eligibility (at least 18 years old, man/woman in MDM or woman in GNM, access to a smartphone). Sixteen interested individuals were not eligible for the study due to the gender/major combination. ( 482ff .)
What method of sample selection was used by Lawson? Why is it important to define “MDM” at the outset? How does this definition relate to sampling? Why were interested participants directed to the study coordinator to verify eligibility?
Final Words
I have found that students often find it difficult to be specific enough when defining and choosing their sample. It might help to think about your sample design and sample recruitment like a cookbook. You want all the details there so that someone else can pick up your study and conduct it as you intended. That person could be yourself, but this analogy might work better if you have someone else in mind. When I am writing down recipes, I often think of my sister and try to convey the details she would need to duplicate the dish. We share a grandmother whose recipes are full of handwritten notes in the margins, in spidery ink, that tell us what bowl to use when or where things could go wrong. Describe your sample clearly, convey the steps required accurately, and then add any other details that will help keep you on track and remind you why you have chosen to limit possible interviewees to those of a certain age or class or location. Imagine actually going out and getting your sample (making your dish). Do you have all the necessary details to get started?
Table 5.1. Sampling Type and Strategies
| Type | Used primarily in... | Strategies | |
|---|---|---|---|
| Probabilistic | Quantitative research | ||
| Simple random | Each member of the population has an equal chance at being selected | ||
| Stratified | The sample is split into strata; members of each strata are selected in proportion to the population at large | ||
| Non-probabilistic | Qualitative research | ||
| Convenience | Simply includes the individuals who happen to be most accessible to the researcher | ||
| Snowball | Used to recruit participants via other participants. The number of people you have access to “snowballs” as you get in contact with more people | ||
| Purposive | Involves the researcher using their expertise to select a sample that is most useful to the purposes of the research; An effective purposive sample must have clear criteria and rationale for inclusion (e.g., ) | ||
| Quota | Set quotas to ensure that the sample you get represents certain characteristics in proportion to their prevalence in the population |
Further Readings
Fusch, Patricia I., and Lawrence R. Ness. 2015. “Are We There Yet? Data Saturation in Qualitative Research.” Qualitative Report 20(9):1408–1416.
Saunders, Benjamin, Julius Sim, Tom Kinstone, Shula Baker, Jackie Waterfield, Bernadette Bartlam, Heather Burroughs, and Clare Jinks. 2018. “Saturation in Qualitative Research: Exploring Its Conceptualization and Operationalization.” Quality & Quantity 52(4):1893–1907.
- Rubin ( 2021 ) suggests a minimum of twenty interviews (but safer with thirty) for an interview-based study and a minimum of three to six months in the field for ethnographic studies. For a content-based study, she suggests between five hundred and one thousand documents, although some will be “very small” ( 243–244 ). ↵
The process of selecting people or other units of analysis to represent a larger population. In quantitative research, this representation is taken quite literally, as statistically representative. In qualitative research, in contrast, sample selection is often made based on potential to generate insight about a particular topic or phenomenon.
The actual list of individuals that the sample will be drawn from. Ideally, it should include the entire target population (and nobody who is not part of that population). Sampling frames can differ from the larger population when specific exclusions are inherent, as in the case of pulling names randomly from voter registration rolls where not everyone is a registered voter. This difference in frame and population can undercut the generalizability of quantitative results.
The specific group of individuals that you will collect data from. Contrast population.
The large group of interest to the researcher. Although it will likely be impossible to design a study that incorporates or reaches all members of the population of interest, this should be clearly defined at the outset of a study so that a reasonable sample of the population can be taken. For example, if one is studying working-class college students, the sample may include twenty such students attending a particular college, while the population is “working-class college students.” In quantitative research, clearly defining the general population of interest is a necessary step in generalizing results from a sample. In qualitative research, defining the population is conceptually important for clarity.
A sampling strategy in which the sample is chosen to represent (numerically) the larger population from which it is drawn by random selection. Each person in the population has an equal chance of making it into the sample. This is often done through a lottery or other chance mechanisms (e.g., a random selection of every twelfth name on an alphabetical list of voters). Also known as random sampling .
The selection of research participants or other data sources based on availability or accessibility, in contrast to purposive sampling .
A sample generated non-randomly by asking participants to help recruit more participants the idea being that a person who fits your sampling criteria probably knows other people with similar criteria.
Broad codes that are assigned to the main issues emerging in the data; identifying themes is often part of initial coding .
A form of case selection focusing on examples that do not fit the emerging patterns. This allows the researcher to evaluate rival explanations or to define the limitations of their research findings. While disconfirming cases are found (not sought out), researchers should expand their analysis or rethink their theories to include/explain them.
A methodological tradition of inquiry and approach to analyzing qualitative data in which theories emerge from a rigorous and systematic process of induction. This approach was pioneered by the sociologists Glaser and Strauss (1967). The elements of theory generated from comparative analysis of data are, first, conceptual categories and their properties and, second, hypotheses or generalized relations among the categories and their properties – “The constant comparing of many groups draws the [researcher’s] attention to their many similarities and differences. Considering these leads [the researcher] to generate abstract categories and their properties, which, since they emerge from the data, will clearly be important to a theory explaining the kind of behavior under observation.” (36).
The result of probability sampling, in which a sample is chosen to represent (numerically) the larger population from which it is drawn by random selection. Each person in the population has an equal chance of making it into the random sample. This is often done through a lottery or other chance mechanisms (e.g., the random selection of every twelfth name on an alphabetical list of voters). This is typically not required in qualitative research but rather essential for the generalizability of quantitative research.
A form of case selection or purposeful sampling in which cases that are unusual or special in some way are chosen to highlight processes or to illuminate gaps in our knowledge of a phenomenon. See also extreme case .
The point at which you can conclude data collection because every person you are interviewing, the interaction you are observing, or content you are analyzing merely confirms what you have already noted. Achieving saturation is often used as the justification for the final sample size.
The accuracy with which results or findings can be transferred to situations or people other than those originally studied. Qualitative studies generally are unable to use (and are uninterested in) statistical generalizability where the sample population is said to be able to predict or stand in for a larger population of interest. Instead, qualitative researchers often discuss “theoretical generalizability,” in which the findings of a particular study can shed light on processes and mechanisms that may be at play in other settings. See also statistical generalization and theoretical generalization .
A term used by IRBs to denote all materials aimed at recruiting participants into a research study (including printed advertisements, scripts, audio or video tapes, or websites). Copies of this material are required in research protocols submitted to IRB.
Introduction to Qualitative Research Methods Copyright © 2023 by Allison Hurst is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License , except where otherwise noted.
Sampling Methods In Reseach: Types, Techniques, & Examples
Saul McLeod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul McLeod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
Sampling methods in psychology refer to strategies used to select a subset of individuals (a sample) from a larger population, to study and draw inferences about the entire population. Common methods include random sampling, stratified sampling, cluster sampling, and convenience sampling. Proper sampling ensures representative, generalizable, and valid research results.
- Sampling : the process of selecting a representative group from the population under study.
- Target population : the total group of individuals from which the sample might be drawn.
- Sample: a subset of individuals selected from a larger population for study or investigation. Those included in the sample are termed “participants.”
- Generalizability : the ability to apply research findings from a sample to the broader target population, contingent on the sample being representative of that population.
For instance, if the advert for volunteers is published in the New York Times, this limits how much the study’s findings can be generalized to the whole population, because NYT readers may not represent the entire population in certain respects (e.g., politically, socio-economically).
The Purpose of Sampling
We are interested in learning about large groups of people with something in common in psychological research. We call the group interested in studying our “target population.”
In some types of research, the target population might be as broad as all humans. Still, in other types of research, the target population might be a smaller group, such as teenagers, preschool children, or people who misuse drugs.

Studying every person in a target population is more or less impossible. Hence, psychologists select a sample or sub-group of the population that is likely to be representative of the target population we are interested in.
This is important because we want to generalize from the sample to the target population. The more representative the sample, the more confident the researcher can be that the results can be generalized to the target population.
One of the problems that can occur when selecting a sample from a target population is sampling bias. Sampling bias refers to situations where the sample does not reflect the characteristics of the target population.
Many psychology studies have a biased sample because they have used an opportunity sample that comprises university students as their participants (e.g., Asch ).
OK, so you’ve thought up this brilliant psychological study and designed it perfectly. But who will you try it out on, and how will you select your participants?
There are various sampling methods. The one chosen will depend on a number of factors (such as time, money, etc.).

Random Sampling
Random sampling is a type of probability sampling where everyone in the entire target population has an equal chance of being selected.
This is similar to the national lottery. If the “population” is everyone who bought a lottery ticket, then everyone has an equal chance of winning the lottery (assuming they all have one ticket each).
Random samples require naming or numbering the target population and then using some raffle method to choose those to make up the sample. Random samples are the best method of selecting your sample from the population of interest.
- The advantages are that your sample should represent the target population and eliminate sampling bias.
- The disadvantage is that it is very difficult to achieve (i.e., time, effort, and money).
Stratified Sampling
During stratified sampling , the researcher identifies the different types of people that make up the target population and works out the proportions needed for the sample to be representative.
A list is made of each variable (e.g., IQ, gender, etc.) that might have an effect on the research. For example, if we are interested in the money spent on books by undergraduates, then the main subject studied may be an important variable.
For example, students studying English Literature may spend more money on books than engineering students, so if we use a large percentage of English students or engineering students, our results will not be accurate.
We have to determine the relative percentage of each group at a university, e.g., Engineering 10%, Social Sciences 15%, English 20%, Sciences 25%, Languages 10%, Law 5%, and Medicine 15%. The sample must then contain all these groups in the same proportion as the target population (university students).
- The disadvantage of stratified sampling is that gathering such a sample would be extremely time-consuming and difficult to do. This method is rarely used in Psychology.
- However, the advantage is that the sample should be highly representative of the target population, and therefore we can generalize from the results obtained.
Opportunity Sampling
Opportunity sampling is a method in which participants are chosen based on their ease of availability and proximity to the researcher, rather than using random or systematic criteria. It’s a type of convenience sampling .
An opportunity sample is obtained by asking members of the population of interest if they would participate in your research. An example would be selecting a sample of students from those coming out of the library.
- This is a quick and easy way of choosing participants (advantage)
- It may not provide a representative sample and could be biased (disadvantage).
Systematic Sampling
Systematic sampling is a method where every nth individual is selected from a list or sequence to form a sample, ensuring even and regular intervals between chosen subjects.
Participants are systematically selected (i.e., orderly/logical) from the target population, like every nth participant on a list of names.
To take a systematic sample, you list all the population members and then decide upon a sample you would like. By dividing the number of people in the population by the number of people you want in your sample, you get a number we will call n.
If you take every nth name, you will get a systematic sample of the correct size. If, for example, you wanted to sample 150 children from a school of 1,500, you would take every 10th name.
- The advantage of this method is that it should provide a representative sample.
Sample size
The sample size is a critical factor in determining the reliability and validity of a study’s findings. While increasing the sample size can enhance the generalizability of results, it’s also essential to balance practical considerations, such as resource constraints and diminishing returns from ever-larger samples.
Reliability and Validity
Reliability refers to the consistency and reproducibility of research findings across different occasions, researchers, or instruments. A small sample size may lead to inconsistent results due to increased susceptibility to random error or the influence of outliers. In contrast, a larger sample minimizes these errors, promoting more reliable results.
Validity pertains to the accuracy and truthfulness of research findings. For a study to be valid, it should accurately measure what it intends to do. A small, unrepresentative sample can compromise external validity, meaning the results don’t generalize well to the larger population. A larger sample captures more variability, ensuring that specific subgroups or anomalies don’t overly influence results.
Practical Considerations
Resource Constraints : Larger samples demand more time, money, and resources. Data collection becomes more extensive, data analysis more complex, and logistics more challenging.
Diminishing Returns : While increasing the sample size generally leads to improved accuracy and precision, there’s a point where adding more participants yields only marginal benefits. For instance, going from 50 to 500 participants might significantly boost a study’s robustness, but jumping from 10,000 to 10,500 might not offer a comparable advantage, especially considering the added costs.
- Privacy Policy
Home » Sampling Methods – Types, Techniques and Examples
Sampling Methods – Types, Techniques and Examples
Table of Contents

Sampling refers to the process of selecting a subset of data from a larger population or dataset in order to analyze or make inferences about the whole population.
In other words, sampling involves taking a representative sample of data from a larger group or dataset in order to gain insights or draw conclusions about the entire group.
Sampling Methods
Sampling methods refer to the techniques used to select a subset of individuals or units from a larger population for the purpose of conducting statistical analysis or research.
Sampling is an essential part of the Research because it allows researchers to draw conclusions about a population without having to collect data from every member of that population, which can be time-consuming, expensive, or even impossible.
Types of Sampling Methods
Sampling can be broadly categorized into two main categories:
Probability Sampling
This type of sampling is based on the principles of random selection, and it involves selecting samples in a way that every member of the population has an equal chance of being included in the sample.. Probability sampling is commonly used in scientific research and statistical analysis, as it provides a representative sample that can be generalized to the larger population.
Type of Probability Sampling :
- Simple Random Sampling: In this method, every member of the population has an equal chance of being selected for the sample. This can be done using a random number generator or by drawing names out of a hat, for example.
- Systematic Sampling: In this method, the population is first divided into a list or sequence, and then every nth member is selected for the sample. For example, if every 10th person is selected from a list of 100 people, the sample would include 10 people.
- Stratified Sampling: In this method, the population is divided into subgroups or strata based on certain characteristics, and then a random sample is taken from each stratum. This is often used to ensure that the sample is representative of the population as a whole.
- Cluster Sampling: In this method, the population is divided into clusters or groups, and then a random sample of clusters is selected. Then, all members of the selected clusters are included in the sample.
- Multi-Stage Sampling : This method combines two or more sampling techniques. For example, a researcher may use stratified sampling to select clusters, and then use simple random sampling to select members within each cluster.
Non-probability Sampling
This type of sampling does not rely on random selection, and it involves selecting samples in a way that does not give every member of the population an equal chance of being included in the sample. Non-probability sampling is often used in qualitative research, where the aim is not to generalize findings to a larger population, but to gain an in-depth understanding of a particular phenomenon or group. Non-probability sampling methods can be quicker and more cost-effective than probability sampling methods, but they may also be subject to bias and may not be representative of the larger population.
Types of Non-probability Sampling :
- Convenience Sampling: In this method, participants are chosen based on their availability or willingness to participate. This method is easy and convenient but may not be representative of the population.
- Purposive Sampling: In this method, participants are selected based on specific criteria, such as their expertise or knowledge on a particular topic. This method is often used in qualitative research, but may not be representative of the population.
- Snowball Sampling: In this method, participants are recruited through referrals from other participants. This method is often used when the population is hard to reach, but may not be representative of the population.
- Quota Sampling: In this method, a predetermined number of participants are selected based on specific criteria, such as age or gender. This method is often used in market research, but may not be representative of the population.
- Volunteer Sampling: In this method, participants volunteer to participate in the study. This method is often used in research where participants are motivated by personal interest or altruism, but may not be representative of the population.
Applications of Sampling Methods
Applications of Sampling Methods from different fields:
- Psychology : Sampling methods are used in psychology research to study various aspects of human behavior and mental processes. For example, researchers may use stratified sampling to select a sample of participants that is representative of the population based on factors such as age, gender, and ethnicity. Random sampling may also be used to select participants for experimental studies.
- Sociology : Sampling methods are commonly used in sociological research to study social phenomena and relationships between individuals and groups. For example, researchers may use cluster sampling to select a sample of neighborhoods to study the effects of economic inequality on health outcomes. Stratified sampling may also be used to select a sample of participants that is representative of the population based on factors such as income, education, and occupation.
- Social sciences: Sampling methods are commonly used in social sciences to study human behavior and attitudes. For example, researchers may use stratified sampling to select a sample of participants that is representative of the population based on factors such as age, gender, and income.
- Marketing : Sampling methods are used in marketing research to collect data on consumer preferences, behavior, and attitudes. For example, researchers may use random sampling to select a sample of consumers to participate in a survey about a new product.
- Healthcare : Sampling methods are used in healthcare research to study the prevalence of diseases and risk factors, and to evaluate interventions. For example, researchers may use cluster sampling to select a sample of health clinics to participate in a study of the effectiveness of a new treatment.
- Environmental science: Sampling methods are used in environmental science to collect data on environmental variables such as water quality, air pollution, and soil composition. For example, researchers may use systematic sampling to collect soil samples at regular intervals across a field.
- Education : Sampling methods are used in education research to study student learning and achievement. For example, researchers may use stratified sampling to select a sample of schools that is representative of the population based on factors such as demographics and academic performance.
Examples of Sampling Methods
Probability Sampling Methods Examples:
- Simple random sampling Example : A researcher randomly selects participants from the population using a random number generator or drawing names from a hat.
- Stratified random sampling Example : A researcher divides the population into subgroups (strata) based on a characteristic of interest (e.g. age or income) and then randomly selects participants from each subgroup.
- Systematic sampling Example : A researcher selects participants at regular intervals from a list of the population.
Non-probability Sampling Methods Examples:
- Convenience sampling Example: A researcher selects participants who are conveniently available, such as students in a particular class or visitors to a shopping mall.
- Purposive sampling Example : A researcher selects participants who meet specific criteria, such as individuals who have been diagnosed with a particular medical condition.
- Snowball sampling Example : A researcher selects participants who are referred to them by other participants, such as friends or acquaintances.
How to Conduct Sampling Methods
some general steps to conduct sampling methods:
- Define the population: Identify the population of interest and clearly define its boundaries.
- Choose the sampling method: Select an appropriate sampling method based on the research question, characteristics of the population, and available resources.
- Determine the sample size: Determine the desired sample size based on statistical considerations such as margin of error, confidence level, or power analysis.
- Create a sampling frame: Develop a list of all individuals or elements in the population from which the sample will be drawn. The sampling frame should be comprehensive, accurate, and up-to-date.
- Select the sample: Use the chosen sampling method to select the sample from the sampling frame. The sample should be selected randomly, or if using a non-random method, every effort should be made to minimize bias and ensure that the sample is representative of the population.
- Collect data: Once the sample has been selected, collect data from each member of the sample using appropriate research methods (e.g., surveys, interviews, observations).
- Analyze the data: Analyze the data collected from the sample to draw conclusions about the population of interest.
When to use Sampling Methods
Sampling methods are used in research when it is not feasible or practical to study the entire population of interest. Sampling allows researchers to study a smaller group of individuals, known as a sample, and use the findings from the sample to make inferences about the larger population.
Sampling methods are particularly useful when:
- The population of interest is too large to study in its entirety.
- The cost and time required to study the entire population are prohibitive.
- The population is geographically dispersed or difficult to access.
- The research question requires specialized or hard-to-find individuals.
- The data collected is quantitative and statistical analyses are used to draw conclusions.
Purpose of Sampling Methods
The main purpose of sampling methods in research is to obtain a representative sample of individuals or elements from a larger population of interest, in order to make inferences about the population as a whole. By studying a smaller group of individuals, known as a sample, researchers can gather information about the population that would be difficult or impossible to obtain from studying the entire population.
Sampling methods allow researchers to:
- Study a smaller, more manageable group of individuals, which is typically less time-consuming and less expensive than studying the entire population.
- Reduce the potential for data collection errors and improve the accuracy of the results by minimizing sampling bias.
- Make inferences about the larger population with a certain degree of confidence, using statistical analyses of the data collected from the sample.
- Improve the generalizability and external validity of the findings by ensuring that the sample is representative of the population of interest.
Characteristics of Sampling Methods
Here are some characteristics of sampling methods:
- Randomness : Probability sampling methods are based on random selection, meaning that every member of the population has an equal chance of being selected. This helps to minimize bias and ensure that the sample is representative of the population.
- Representativeness : The goal of sampling is to obtain a sample that is representative of the larger population of interest. This means that the sample should reflect the characteristics of the population in terms of key demographic, behavioral, or other relevant variables.
- Size : The size of the sample should be large enough to provide sufficient statistical power for the research question at hand. The sample size should also be appropriate for the chosen sampling method and the level of precision desired.
- Efficiency : Sampling methods should be efficient in terms of time, cost, and resources required. The method chosen should be feasible given the available resources and time constraints.
- Bias : Sampling methods should aim to minimize bias and ensure that the sample is representative of the population of interest. Bias can be introduced through non-random selection or non-response, and can affect the validity and generalizability of the findings.
- Precision : Sampling methods should be precise in terms of providing estimates of the population parameters of interest. Precision is influenced by sample size, sampling method, and level of variability in the population.
- Validity : The validity of the sampling method is important for ensuring that the results obtained from the sample are accurate and can be generalized to the population of interest. Validity can be affected by sampling method, sample size, and the representativeness of the sample.
Advantages of Sampling Methods
Sampling methods have several advantages, including:
- Cost-Effective : Sampling methods are often much cheaper and less time-consuming than studying an entire population. By studying only a small subset of the population, researchers can gather valuable data without incurring the costs associated with studying the entire population.
- Convenience : Sampling methods are often more convenient than studying an entire population. For example, if a researcher wants to study the eating habits of people in a city, it would be very difficult and time-consuming to study every single person in the city. By using sampling methods, the researcher can obtain data from a smaller subset of people, making the study more feasible.
- Accuracy: When done correctly, sampling methods can be very accurate. By using appropriate sampling techniques, researchers can obtain a sample that is representative of the entire population. This allows them to make accurate generalizations about the population as a whole based on the data collected from the sample.
- Time-Saving: Sampling methods can save a lot of time compared to studying the entire population. By studying a smaller sample, researchers can collect data much more quickly than they could if they studied every single person in the population.
- Less Bias : Sampling methods can reduce bias in a study. If a researcher were to study the entire population, it would be very difficult to eliminate all sources of bias. However, by using appropriate sampling techniques, researchers can reduce bias and obtain a sample that is more representative of the entire population.
Limitations of Sampling Methods
- Sampling Error : Sampling error is the difference between the sample statistic and the population parameter. It is the result of selecting a sample rather than the entire population. The larger the sample, the lower the sampling error. However, no matter how large the sample size, there will always be some degree of sampling error.
- Selection Bias: Selection bias occurs when the sample is not representative of the population. This can happen if the sample is not selected randomly or if some groups are underrepresented in the sample. Selection bias can lead to inaccurate conclusions about the population.
- Non-response Bias : Non-response bias occurs when some members of the sample do not respond to the survey or study. This can result in a biased sample if the non-respondents differ from the respondents in important ways.
- Time and Cost : While sampling can be cost-effective, it can still be expensive and time-consuming to select a sample that is representative of the population. Depending on the sampling method used, it may take a long time to obtain a sample that is large enough and representative enough to be useful.
- Limited Information : Sampling can only provide information about the variables that are measured. It may not provide information about other variables that are relevant to the research question but were not measured.
- Generalization : The extent to which the findings from a sample can be generalized to the population depends on the representativeness of the sample. If the sample is not representative of the population, it may not be possible to generalize the findings to the population as a whole.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Stratified Random Sampling – Definition, Method...

Cluster Sampling – Types, Method and Examples

Quota Sampling – Types, Methods and Examples

Purposive Sampling – Methods, Types and Examples

Volunteer Sampling – Definition, Methods and...

Probability Sampling – Methods, Types and...
Sampling Methods & Strategies 101
Everything you need to know (including examples)
By: Derek Jansen (MBA) | Expert Reviewed By: Kerryn Warren (PhD) | January 2023
If you’re new to research, sooner or later you’re bound to wander into the intimidating world of sampling methods and strategies. If you find yourself on this page, chances are you’re feeling a little overwhelmed or confused. Fear not – in this post we’ll unpack sampling in straightforward language , along with loads of examples .
Overview: Sampling Methods & Strategies
- What is sampling in a research context?
- The two overarching approaches
Simple random sampling
Stratified random sampling, cluster sampling, systematic sampling, purposive sampling, convenience sampling, snowball sampling.
- How to choose the right sampling method
What (exactly) is sampling?
At the simplest level, sampling (within a research context) is the process of selecting a subset of participants from a larger group . For example, if your research involved assessing US consumers’ perceptions about a particular brand of laundry detergent, you wouldn’t be able to collect data from every single person that uses laundry detergent (good luck with that!) – but you could potentially collect data from a smaller subset of this group.
In technical terms, the larger group is referred to as the population , and the subset (the group you’ll actually engage with in your research) is called the sample . Put another way, you can look at the population as a full cake and the sample as a single slice of that cake. In an ideal world, you’d want your sample to be perfectly representative of the population, as that would allow you to generalise your findings to the entire population. In other words, you’d want to cut a perfect cross-sectional slice of cake, such that the slice reflects every layer of the cake in perfect proportion.
Achieving a truly representative sample is, unfortunately, a little trickier than slicing a cake, as there are many practical challenges and obstacles to achieving this in a real-world setting. Thankfully though, you don’t always need to have a perfectly representative sample – it all depends on the specific research aims of each study – so don’t stress yourself out about that just yet!
With the concept of sampling broadly defined, let’s look at the different approaches to sampling to get a better understanding of what it all looks like in practice.

The two overarching sampling approaches
At the highest level, there are two approaches to sampling: probability sampling and non-probability sampling . Within each of these, there are a variety of sampling methods , which we’ll explore a little later.
Probability sampling involves selecting participants (or any unit of interest) on a statistically random basis , which is why it’s also called “random sampling”. In other words, the selection of each individual participant is based on a pre-determined process (not the discretion of the researcher). As a result, this approach achieves a random sample.
Probability-based sampling methods are most commonly used in quantitative research , especially when it’s important to achieve a representative sample that allows the researcher to generalise their findings.
Non-probability sampling , on the other hand, refers to sampling methods in which the selection of participants is not statistically random . In other words, the selection of individual participants is based on the discretion and judgment of the researcher, rather than on a pre-determined process.
Non-probability sampling methods are commonly used in qualitative research , where the richness and depth of the data are more important than the generalisability of the findings.
If that all sounds a little too conceptual and fluffy, don’t worry. Let’s take a look at some actual sampling methods to make it more tangible.
Need a helping hand?
Probability-based sampling methods
First, we’ll look at four common probability-based (random) sampling methods:
Importantly, this is not a comprehensive list of all the probability sampling methods – these are just four of the most common ones. So, if you’re interested in adopting a probability-based sampling approach, be sure to explore all the options.
Simple random sampling involves selecting participants in a completely random fashion , where each participant has an equal chance of being selected. Basically, this sampling method is the equivalent of pulling names out of a hat , except that you can do it digitally. For example, if you had a list of 500 people, you could use a random number generator to draw a list of 50 numbers (each number, reflecting a participant) and then use that dataset as your sample.
Thanks to its simplicity, simple random sampling is easy to implement , and as a consequence, is typically quite cheap and efficient . Given that the selection process is completely random, the results can be generalised fairly reliably. However, this also means it can hide the impact of large subgroups within the data, which can result in minority subgroups having little representation in the results – if any at all. To address this, one needs to take a slightly different approach, which we’ll look at next.
Stratified random sampling is similar to simple random sampling, but it kicks things up a notch. As the name suggests, stratified sampling involves selecting participants randomly , but from within certain pre-defined subgroups (i.e., strata) that share a common trait . For example, you might divide the population into strata based on gender, ethnicity, age range or level of education, and then select randomly from each group.
The benefit of this sampling method is that it gives you more control over the impact of large subgroups (strata) within the population. For example, if a population comprises 80% males and 20% females, you may want to “balance” this skew out by selecting a random sample from an equal number of males and females. This would, of course, reduce the representativeness of the sample, but it would allow you to identify differences between subgroups. So, depending on your research aims, the stratified approach could work well.

Next on the list is cluster sampling. As the name suggests, this sampling method involves sampling from naturally occurring, mutually exclusive clusters within a population – for example, area codes within a city or cities within a country. Once the clusters are defined, a set of clusters are randomly selected and then a set of participants are randomly selected from each cluster.
Now, you’re probably wondering, “how is cluster sampling different from stratified random sampling?”. Well, let’s look at the previous example where each cluster reflects an area code in a given city.
With cluster sampling, you would collect data from clusters of participants in a handful of area codes (let’s say 5 neighbourhoods). Conversely, with stratified random sampling, you would need to collect data from all over the city (i.e., many more neighbourhoods). You’d still achieve the same sample size either way (let’s say 200 people, for example), but with stratified sampling, you’d need to do a lot more running around, as participants would be scattered across a vast geographic area. As a result, cluster sampling is often the more practical and economical option.
If that all sounds a little mind-bending, you can use the following general rule of thumb. If a population is relatively homogeneous , cluster sampling will often be adequate. Conversely, if a population is quite heterogeneous (i.e., diverse), stratified sampling will generally be more appropriate.
The last probability sampling method we’ll look at is systematic sampling. This method simply involves selecting participants at a set interval , starting from a random point .
For example, if you have a list of students that reflects the population of a university, you could systematically sample that population by selecting participants at an interval of 8 . In other words, you would randomly select a starting point – let’s say student number 40 – followed by student 48, 56, 64, etc.
What’s important with systematic sampling is that the population list you select from needs to be randomly ordered . If there are underlying patterns in the list (for example, if the list is ordered by gender, IQ, age, etc.), this will result in a non-random sample, which would defeat the purpose of adopting this sampling method. Of course, you could safeguard against this by “shuffling” your population list using a random number generator or similar tool.

Non-probability-based sampling methods
Right, now that we’ve looked at a few probability-based sampling methods, let’s look at three non-probability methods :
Again, this is not an exhaustive list of all possible sampling methods, so be sure to explore further if you’re interested in adopting a non-probability sampling approach.
First up, we’ve got purposive sampling – also known as judgment , selective or subjective sampling. Again, the name provides some clues, as this method involves the researcher selecting participants using his or her own judgement , based on the purpose of the study (i.e., the research aims).
For example, suppose your research aims were to understand the perceptions of hyper-loyal customers of a particular retail store. In that case, you could use your judgement to engage with frequent shoppers, as well as rare or occasional shoppers, to understand what judgements drive the two behavioural extremes .
Purposive sampling is often used in studies where the aim is to gather information from a small population (especially rare or hard-to-find populations), as it allows the researcher to target specific individuals who have unique knowledge or experience . Naturally, this sampling method is quite prone to researcher bias and judgement error, and it’s unlikely to produce generalisable results, so it’s best suited to studies where the aim is to go deep rather than broad .

Next up, we have convenience sampling. As the name suggests, with this method, participants are selected based on their availability or accessibility . In other words, the sample is selected based on how convenient it is for the researcher to access it, as opposed to using a defined and objective process.
Naturally, convenience sampling provides a quick and easy way to gather data, as the sample is selected based on the individuals who are readily available or willing to participate. This makes it an attractive option if you’re particularly tight on resources and/or time. However, as you’d expect, this sampling method is unlikely to produce a representative sample and will of course be vulnerable to researcher bias , so it’s important to approach it with caution.
Last but not least, we have the snowball sampling method. This method relies on referrals from initial participants to recruit additional participants. In other words, the initial subjects form the first (small) snowball and each additional subject recruited through referral is added to the snowball, making it larger as it rolls along .
Snowball sampling is often used in research contexts where it’s difficult to identify and access a particular population. For example, people with a rare medical condition or members of an exclusive group. It can also be useful in cases where the research topic is sensitive or taboo and people are unlikely to open up unless they’re referred by someone they trust.
Simply put, snowball sampling is ideal for research that involves reaching hard-to-access populations . But, keep in mind that, once again, it’s a sampling method that’s highly prone to researcher bias and is unlikely to produce a representative sample. So, make sure that it aligns with your research aims and questions before adopting this method.
How to choose a sampling method
Now that we’ve looked at a few popular sampling methods (both probability and non-probability based), the obvious question is, “ how do I choose the right sampling method for my study?”. When selecting a sampling method for your research project, you’ll need to consider two important factors: your research aims and your resources .
As with all research design and methodology choices, your sampling approach needs to be guided by and aligned with your research aims, objectives and research questions – in other words, your golden thread. Specifically, you need to consider whether your research aims are primarily concerned with producing generalisable findings (in which case, you’ll likely opt for a probability-based sampling method) or with achieving rich , deep insights (in which case, a non-probability-based approach could be more practical). Typically, quantitative studies lean toward the former, while qualitative studies aim for the latter, so be sure to consider your broader methodology as well.
The second factor you need to consider is your resources and, more generally, the practical constraints at play. If, for example, you have easy, free access to a large sample at your workplace or university and a healthy budget to help you attract participants, that will open up multiple options in terms of sampling methods. Conversely, if you’re cash-strapped, short on time and don’t have unfettered access to your population of interest, you may be restricted to convenience or referral-based methods.
In short, be ready for trade-offs – you won’t always be able to utilise the “perfect” sampling method for your study, and that’s okay. Much like all the other methodological choices you’ll make as part of your study, you’ll often need to compromise and accept practical trade-offs when it comes to sampling. Don’t let this get you down though – as long as your sampling choice is well explained and justified, and the limitations of your approach are clearly articulated, you’ll be on the right track.

Let’s recap…
In this post, we’ve covered the basics of sampling within the context of a typical research project.
- Sampling refers to the process of defining a subgroup (sample) from the larger group of interest (population).
- The two overarching approaches to sampling are probability sampling (random) and non-probability sampling .
- Common probability-based sampling methods include simple random sampling, stratified random sampling, cluster sampling and systematic sampling.
- Common non-probability-based sampling methods include purposive sampling, convenience sampling and snowball sampling.
- When choosing a sampling method, you need to consider your research aims , objectives and questions, as well as your resources and other practical constraints .
If you’d like to see an example of a sampling strategy in action, be sure to check out our research methodology chapter sample .
Last but not least, if you need hands-on help with your sampling (or any other aspect of your research), take a look at our 1-on-1 coaching service , where we guide you through each step of the research process, at your own pace.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...

Excellent and helpful. Best site to get a full understanding of Research methodology. I’m nolonger as “clueless “..😉

Excellent and helpful for junior researcher!

Grad Coach tutorials are excellent – I recommend them to everyone doing research. I will be working with a sample of imprisoned women and now have a much clearer idea concerning sampling. Thank you to all at Grad Coach for generously sharing your expertise with students.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed.
- Search in PubMed
- Search in NLM Catalog
- Add to Search
Sampling Methods: A guide for researchers
Affiliation.
- 1 Arizona School of Dentistry & Oral Health A.T. Still University, Mesa, AZ, USA [email protected].
- PMID: 37553279
Sampling is a critical element of research design. Different methods can be used for sample selection to ensure that members of the study population reflect both the source and target populations, including probability and non-probability sampling. Power and sample size are used to determine the number of subjects needed to answer the research question. Characteristics of individuals included in the sample population should be clearly defined to determine eligibility for study participation and improve power. Sample selection methods differ based on study design. The purpose of this short report is to review common sampling considerations and related errors.
Keywords: research design; sample size; sampling.
Copyright © 2023 The American Dental Hygienists’ Association.
PubMed Disclaimer
Similar articles
- Common Sampling Errors in Research Studies. Spolarich AE. Spolarich AE. J Dent Hyg. 2023 Dec;97(6):50-53. J Dent Hyg. 2023. PMID: 38061808
- Folic acid supplementation and malaria susceptibility and severity among people taking antifolate antimalarial drugs in endemic areas. Crider K, Williams J, Qi YP, Gutman J, Yeung L, Mai C, Finkelstain J, Mehta S, Pons-Duran C, Menéndez C, Moraleda C, Rogers L, Daniels K, Green P. Crider K, et al. Cochrane Database Syst Rev. 2022 Feb 1;2(2022):CD014217. doi: 10.1002/14651858.CD014217. Cochrane Database Syst Rev. 2022. PMID: 36321557 Free PMC article.
- [A comparison of convenience sampling and purposive sampling]. Suen LJ, Huang HM, Lee HH. Suen LJ, et al. Hu Li Za Zhi. 2014 Jun;61(3):105-11. doi: 10.6224/JN.61.3.105. Hu Li Za Zhi. 2014. PMID: 24899564 Chinese.
- Power and sample size. Case LD, Ambrosius WT. Case LD, et al. Methods Mol Biol. 2007;404:377-408. doi: 10.1007/978-1-59745-530-5_19. Methods Mol Biol. 2007. PMID: 18450060 Review.
- Concepts in sample size determination. Rao UK. Rao UK. Indian J Dent Res. 2012 Sep-Oct;23(5):660-4. doi: 10.4103/0970-9290.107385. Indian J Dent Res. 2012. PMID: 23422614 Review.
- Search in MeSH
Related information
- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
An overview of sampling methods
Last updated
27 February 2023
Reviewed by
Cathy Heath
When researching perceptions or attributes of a product, service, or people, you have two options:
Survey every person in your chosen group (the target market, or population), collate your responses, and reach your conclusions.
Select a smaller group from within your target market and use their answers to represent everyone. This option is sampling .
Sampling saves you time and money. When you use the sampling method, the whole population being studied is called the sampling frame .
The sample you choose should represent your target market, or the sampling frame, well enough to do one of the following:
Generalize your findings across the sampling frame and use them as though you had surveyed everyone
Use the findings to decide on your next step, which might involve more in-depth sampling
Make research less tedious
Dovetail streamlines research to help you uncover and share actionable insights
How was sampling developed?
Valery Glivenko and Francesco Cantelli, two mathematicians studying probability theory in the early 1900s, devised the sampling method. Their research showed that a properly chosen sample of people would reflect the larger group’s status, opinions, decisions, and decision-making steps.
They proved you don't need to survey the entire target market, thereby saving the rest of us a lot of time and money.
- Why is sampling important?
We’ve already touched on the fact that sampling saves you time and money. When you get reliable results quickly, you can act on them sooner. And the money you save can pay for something else.
It’s often easier to survey a sample than a whole population. Sample inferences can be more reliable than those you get from a very large group because you can choose your samples carefully and scientifically.
Sampling is also useful because it is often impossible to survey the entire population. You probably have no choice but to collect only a sample in the first place.
Because you’re working with fewer people, you can collect richer data, which makes your research more accurate. You can:
Ask more questions
Go into more detail
Seek opinions instead of just collecting facts
Observe user behaviors
Double-check your findings if you need to
In short, sampling works! Let's take a look at the most common sampling methods.
- Types of sampling methods
There are two main sampling methods: probability sampling and non-probability sampling. These can be further refined, which we'll cover shortly. You can then decide which approach best suits your research project.
Probability sampling method
Probability sampling is used in quantitative research , so it provides data on the survey topic in terms of numbers. Probability relates to mathematics, hence the name ‘quantitative research’. Subjects are asked questions like:
How many boxes of candy do you buy at one time?
How often do you shop for candy?
How much would you pay for a box of candy?
This method is also called random sampling because everyone in the target market has an equal chance of being chosen for the survey. It is designed to reduce sampling error for the most important variables. You should, therefore, get results that fairly reflect the larger population.
Non-probability sampling method
In this method, not everyone has an equal chance of being part of the sample. It's usually easier (and cheaper) to select people for the sample group. You choose people who are more likely to be involved in or know more about the topic you’re researching.
Non-probability sampling is used for qualitative research. Qualitative data is generated by questions like:
Where do you usually shop for candy (supermarket, gas station, etc.?)
Which candy brand do you usually buy?
Why do you like that brand?
- Probability sampling methods
Here are five ways of doing probability sampling:
Simple random sampling (basic probability sampling)
Systematic sampling
Stratified sampling.
Cluster sampling
Multi-stage sampling
Simple random sampling.
There are three basic steps to simple random sampling:
Choose your sampling frame.
Decide on your sample size. Make sure it is large enough to give you reliable data.
Randomly choose your sample participants.
You could put all their names in a hat, shake the hat to mix the names, and pull out however many names you want in your sample (without looking!)
You could be more scientific by giving each participant a number and then using a random number generator program to choose the numbers.
Instead of choosing names or numbers, you decide beforehand on a selection method. For example, collect all the names in your sampling frame and start at, for example, the fifth person on the list, then choose every fourth name or every tenth name. Alternatively, you could choose everyone whose last name begins with randomly-selected initials, such as A, G, or W.
Choose your system of selecting names, and away you go.
This is a more sophisticated way to choose your sample. You break the sampling frame down into important subgroups or strata . Then, decide how many you want in your sample, and choose an equal number (or a proportionate number) from each subgroup.
For example, you want to survey how many people in a geographic area buy candy, so you compile a list of everyone in that area. You then break that list down into, for example, males and females, then into pre-teens, teenagers, young adults, senior citizens, etc. who are male or female.
So, if there are 1,000 young male adults and 2,000 young female adults in the whole sampling frame, you may want to choose 100 males and 200 females to keep the proportions balanced. You then choose the individual survey participants through the systematic sampling method.
Clustered sampling
This method is used when you want to subdivide a sample into smaller groups or clusters that are geographically or organizationally related.
Let’s say you’re doing quantitative research into candy sales. You could choose your sample participants from urban, suburban, or rural populations. This would give you three geographic clusters from which to select your participants.
This is a more refined way of doing cluster sampling. Let’s say you have your urban cluster, which is your primary sampling unit. You can subdivide this into a secondary sampling unit, say, participants who typically buy their candy in supermarkets. You could then further subdivide this group into your ultimate sampling unit. Finally, you select the actual survey participants from this unit.
- Uses of probability sampling
Probability sampling has three main advantages:
It helps minimizes the likelihood of sampling bias. How you choose your sample determines the quality of your results. Probability sampling gives you an unbiased, randomly selected sample of your target market.
It allows you to create representative samples and subgroups within a sample out of a large or diverse target market.
It lets you use sophisticated statistical methods to select as close to perfect samples as possible.
- Non-probability sampling methods
To recap, with non-probability sampling, you choose people for your sample in a non-random way, so not everyone in your sampling frame has an equal chance of being chosen. Your research findings, therefore, may not be as representative overall as probability sampling, but you may not want them to be.
Sampling bias is not a concern if all potential survey participants share similar traits. For example, you may want to specifically focus on young male adults who spend more than others on candy. In addition, it is usually a cheaper and quicker method because you don't have to work out a complex selection system that represents the entire population in that community.
Researchers do need to be mindful of carefully considering the strengths and limitations of each method before selecting a sampling technique.
Non-probability sampling is best for exploratory research , such as at the beginning of a research project.
There are five main types of non-probability sampling methods:
Convenience sampling
Purposive sampling, voluntary response sampling, snowball sampling, quota sampling.
The strategy of convenience sampling is to choose your sample quickly and efficiently, using the least effort, usually to save money.
Let's say you want to survey the opinions of 100 millennials about a particular topic. You could send out a questionnaire over the social media platforms millennials use. Ask respondents to confirm their birth year at the top of their response sheet and, when you have your 100 responses, begin your analysis. Or you could visit restaurants and bars where millennials spend their evenings and sign people up.
A drawback of convenience sampling is that it may not yield results that apply to a broader population.
This method relies on your judgment to choose the most likely sample to deliver the most useful results. You must know enough about the survey goals and the sampling frame to choose the most appropriate sample respondents.
Your knowledge and experience save you time because you know your ideal sample candidates, so you should get high-quality results.
This method is similar to convenience sampling, but it is based on potential sample members volunteering rather than you looking for people.
You make it known you want to do a survey on a particular topic for a particular reason and wait until enough people volunteer. Then you give them the questionnaire or arrange interviews to ask your questions directly.
Snowball sampling involves asking selected participants to refer others who may qualify for the survey. This method is best used when there is no sampling frame available. It is also useful when the researcher doesn’t know much about the target population.
Let's say you want to research a niche topic that involves people who may be difficult to locate. For our candy example, this could be young males who buy a lot of candy, go rock climbing during the day, and watch adventure movies at night. You ask each participant to name others they know who do the same things, so you can contact them. As you make contact with more people, your sample 'snowballs' until you have all the names you need.
This sampling method involves collecting the specific number of units (quotas) from your predetermined subpopulations. Quota sampling is a way of ensuring that your sample accurately represents the sampling frame.
- Uses of non-probability sampling
You can use non-probability sampling when you:
Want to do a quick test to see if a more detailed and sophisticated survey may be worthwhile
Want to explore an idea to see if it 'has legs'
Launch a pilot study
Do some initial qualitative research
Have little time or money available (half a loaf is better than no bread at all)
Want to see if the initial results will help you justify a longer, more detailed, and more expensive research project
- The main types of sampling bias, and how to avoid them
Sampling bias can fog or limit your research results. This will have an impact when you generalize your results across the whole target market. The two main causes of sampling bias are faulty research design and poor data collection or recording. They can affect probability and non-probability sampling.
Faulty research
If a surveyor chooses participants inappropriately, the results will not reflect the population as a whole.
A famous example is the 1948 presidential race. A telephone survey was conducted to see which candidate had more support. The problem with the research design was that, in 1948, most people with telephones were wealthy, and their opinions were very different from voters as a whole. The research implied Dewey would win, but it was Truman who became president.
Poor data collection or recording
This problem speaks for itself. The survey may be well structured, the sample groups appropriate, the questions clear and easy to understand, and the cluster sizes appropriate. But if surveyors check the wrong boxes when they get an answer or if the entire subgroup results are lost, the survey results will be biased.
How do you minimize bias in sampling?
To get results you can rely on, you must:
Know enough about your target market
Choose one or more sample surveys to cover the whole target market properly
Choose enough people in each sample so your results mirror your target market
Have content validity . This means the content of your questions must be direct and efficiently worded. If it isn’t, the viability of your survey could be questioned. That would also be a waste of time and money, so make the wording of your questions your top focus.
If using probability sampling, make sure your sampling frame includes everyone it should and that your random sampling selection process includes the right proportion of the subgroups
If using non-probability sampling, focus on fairness, equality, and completeness in identifying your samples and subgroups. Then balance those criteria against simple convenience or other relevant factors.
What are the five types of sampling bias?
Self-selection bias. If you mass-mail questionnaires to everyone in the sample, you’re more likely to get results from people with extrovert or activist personalities and not from introverts or pragmatists. So if your convenience sampling focuses on getting your quota responses quickly, it may be skewed.
Non-response bias. Unhappy customers, stressed-out employees, or other sub-groups may not want to cooperate or they may pull out early.
Undercoverage bias. If your survey is done, say, via email or social media platforms, it will miss people without internet access, such as those living in rural areas, the elderly, or lower-income groups.
Survivorship bias. Unsuccessful people are less likely to take part. Another example may be a researcher excluding results that don’t support the overall goal. If the CEO wants to tell the shareholders about a successful product or project at the AGM, some less positive survey results may go “missing” (to take an extreme example.) The result is that your data will reflect an overly optimistic representation of the truth.
Pre-screening bias. If the researcher, whose experience and knowledge are being used to pre-select respondents in a judgmental sampling, focuses more on convenience than judgment, the results may be compromised.
How do you minimize sampling bias?
Focus on the bullet points in the next section and:
Make survey questionnaires as direct, easy, short, and available as possible, so participants are more likely to complete them accurately and send them back
Follow up with the people who have been selected but have not returned their responses
Ignore any pressure that may produce bias
- How do you decide on the type of sampling to use?
Use the ideas you've gleaned from this article to give yourself a platform, then choose the best method to meet your goals while staying within your time and cost limits.
If it isn't obvious which method you should choose, use this strategy:
Clarify your research goals
Clarify how accurate your research results must be to reach your goals
Evaluate your goals against time and budget
List the two or three most obvious sampling methods that will work for you
Confirm the availability of your resources (researchers, computer time, etc.)
Compare each of the possible methods with your goals, accuracy, precision, resource, time, and cost constraints
Make your decision
- The takeaway
Effective market research is the basis of successful marketing, advertising, and future productivity. By selecting the most appropriate sampling methods, you will collect the most useful market data and make the most effective decisions.
Should you be using a customer insights hub?
Do you want to discover previous research faster?
Do you share your research findings with others?
Do you analyze research data?
Start for free today, add your research, and get to key insights faster
Editor’s picks
Last updated: 18 April 2023
Last updated: 27 February 2023
Last updated: 22 August 2024
Last updated: 5 February 2023
Last updated: 16 August 2024
Last updated: 9 March 2023
Last updated: 30 April 2024
Last updated: 12 December 2023
Last updated: 11 March 2024
Last updated: 4 July 2024
Last updated: 6 March 2024
Last updated: 5 March 2024
Last updated: 13 May 2024
Latest articles
Related topics, .css-je19u9{-webkit-align-items:flex-end;-webkit-box-align:flex-end;-ms-flex-align:flex-end;align-items:flex-end;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-flex-direction:row;-ms-flex-direction:row;flex-direction:row;-webkit-box-flex-wrap:wrap;-webkit-flex-wrap:wrap;-ms-flex-wrap:wrap;flex-wrap:wrap;-webkit-box-pack:center;-ms-flex-pack:center;-webkit-justify-content:center;justify-content:center;row-gap:0;text-align:center;max-width:671px;}@media (max-width: 1079px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}}@media (max-width: 799px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}} decide what to .css-1kiodld{max-height:56px;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;}@media (max-width: 1079px){.css-1kiodld{display:none;}} build next, decide what to build next, log in or sign up.
Get started for free
- En español – ExME
- Em português – EME
What are sampling methods and how do you choose the best one?
Posted on 18th November 2020 by Mohamed Khalifa

This tutorial will introduce sampling methods and potential sampling errors to avoid when conducting medical research.
Introduction to sampling methods
Examples of different sampling methods, choosing the best sampling method.
It is important to understand why we sample the population; for example, studies are built to investigate the relationships between risk factors and disease. In other words, we want to find out if this is a true association, while still aiming for the minimum risk for errors such as: chance, bias or confounding .
However, it would not be feasible to experiment on the whole population, we would need to take a good sample and aim to reduce the risk of having errors by proper sampling technique.
What is a sampling frame?
A sampling frame is a record of the target population containing all participants of interest. In other words, it is a list from which we can extract a sample.
What makes a good sample?
A good sample should be a representative subset of the population we are interested in studying, therefore, with each participant having equal chance of being randomly selected into the study.
We could choose a sampling method based on whether we want to account for sampling bias; a random sampling method is often preferred over a non-random method for this reason. Random sampling examples include: simple, systematic, stratified, and cluster sampling. Non-random sampling methods are liable to bias, and common examples include: convenience, purposive, snowballing, and quota sampling. For the purposes of this blog we will be focusing on random sampling methods .
Example: We want to conduct an experimental trial in a small population such as: employees in a company, or students in a college. We include everyone in a list and use a random number generator to select the participants
Advantages: Generalisable results possible, random sampling, the sampling frame is the whole population, every participant has an equal probability of being selected
Disadvantages: Less precise than stratified method, less representative than the systematic method

Example: Every nth patient entering the out-patient clinic is selected and included in our sample
Advantages: More feasible than simple or stratified methods, sampling frame is not always required
Disadvantages: Generalisability may decrease if baseline characteristics repeat across every nth participant

Example: We have a big population (a city) and we want to ensure representativeness of all groups with a pre-determined characteristic such as: age groups, ethnic origin, and gender
Advantages: Inclusive of strata (subgroups), reliable and generalisable results
Disadvantages: Does not work well with multiple variables

Example: 10 schools have the same number of students across the county. We can randomly select 3 out of 10 schools as our clusters
Advantages: Readily doable with most budgets, does not require a sampling frame
Disadvantages: Results may not be reliable nor generalisable

How can you identify sampling errors?
Non-random selection increases the probability of sampling (selection) bias if the sample does not represent the population we want to study. We could avoid this by random sampling and ensuring representativeness of our sample with regards to sample size.
An inadequate sample size decreases the confidence in our results as we may think there is no significant difference when actually there is. This type two error results from having a small sample size, or from participants dropping out of the sample.
In medical research of disease, if we select people with certain diseases while strictly excluding participants with other co-morbidities, we run the risk of diagnostic purity bias where important sub-groups of the population are not represented.
Furthermore, measurement bias may occur during re-collection of risk factors by participants (recall bias) or assessment of outcome where people who live longer are associated with treatment success, when in fact people who died were not included in the sample or data analysis (survivors bias).
By following the steps below we could choose the best sampling method for our study in an orderly fashion.
Research objectiveness
Firstly, a refined research question and goal would help us define our population of interest. If our calculated sample size is small then it would be easier to get a random sample. If, however, the sample size is large, then we should check if our budget and resources can handle a random sampling method.
Sampling frame availability
Secondly, we need to check for availability of a sampling frame (Simple), if not, could we make a list of our own (Stratified). If neither option is possible, we could still use other random sampling methods, for instance, systematic or cluster sampling.
Study design
Moreover, we could consider the prevalence of the topic (exposure or outcome) in the population, and what would be the suitable study design. In addition, checking if our target population is widely varied in its baseline characteristics. For example, a population with large ethnic subgroups could best be studied using a stratified sampling method.
Random sampling
Finally, the best sampling method is always the one that could best answer our research question while also allowing for others to make use of our results (generalisability of results). When we cannot afford a random sampling method, we can always choose from the non-random sampling methods.
To sum up, we now understand that choosing between random or non-random sampling methods is multifactorial. We might often be tempted to choose a convenience sample from the start, but that would not only decrease precision of our results, and would make us miss out on producing research that is more robust and reliable.
References (pdf)

Mohamed Khalifa
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
No Comments on What are sampling methods and how do you choose the best one?

Thank you for this overview. A concise approach for research.

really helps! am an ecology student preparing to write my lab report for sampling.

I learned a lot to the given presentation.. It’s very comprehensive… Thanks for sharing…

Very informative and useful for my study. Thank you

Oversimplified info on sampling methods. Probabilistic of the sampling and sampling of samples by chance does rest solely on the random methods. Factors such as the random visits or presentation of the potential participants at clinics or sites could be sufficiently random in nature and should be used for the sake of efficiency and feasibility. Nevertheless, this approach has to be taken only after careful thoughts. Representativeness of the study samples have to be checked at the end or during reporting by comparing it to the published larger studies or register of some kind in/from the local population.

Thank you so much Mr.mohamed very useful and informative article
Subscribe to our newsletter
You will receive our monthly newsletter and free access to Trip Premium.
Related Articles

How to read a funnel plot
This blog introduces you to funnel plots, guiding you through how to read them and what may cause them to look asymmetrical.

Internal and external validity: what are they and how do they differ?
Is this study valid? Can I trust this study’s methods and design? Can I apply the results of this study to other contexts? Learn more about internal and external validity in research to help you answer these questions when you next look at a paper.

Cluster Randomized Trials: Concepts
This blog summarizes the concepts of cluster randomization, and the logistical and statistical considerations while designing a cluster randomized controlled trial.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Sampling is the statistical process of selecting a subset—called a ‘sample’—of a population of interest for the purpose of making observations and statistical inferences about that population. Social science research is generally about inferring patterns of behaviours within specific populations. We cannot study entire populations because of feasibility and cost constraints, and hence, we must select a representative sample from the population of interest for observation and analysis. It is extremely important to choose a sample that is truly representative of the population so that the inferences derived from the sample can be generalised back to the population of interest. Improper and biased sampling is the primary reason for the often divergent and erroneous inferences reported in opinion polls and exit polls conducted by different polling groups such as CNN/Gallup Poll, ABC, and CBS, prior to every US Presidential election.
The sampling process
As Figure 8.1 shows, the sampling process comprises of several stages. The first stage is defining the target population. A population can be defined as all people or items ( unit of analysis ) with the characteristics that one wishes to study. The unit of analysis may be a person, group, organisation, country, object, or any other entity that you wish to draw scientific inferences about. Sometimes the population is obvious. For example, if a manufacturer wants to determine whether finished goods manufactured at a production line meet certain quality requirements or must be scrapped and reworked, then the population consists of the entire set of finished goods manufactured at that production facility. At other times, the target population may be a little harder to understand. If you wish to identify the primary drivers of academic learning among high school students, then what is your target population: high school students, their teachers, school principals, or parents? The right answer in this case is high school students, because you are interested in their performance, not the performance of their teachers, parents, or schools. Likewise, if you wish to analyse the behaviour of roulette wheels to identify biased wheels, your population of interest is not different observations from a single roulette wheel, but different roulette wheels (i.e., their behaviour over an infinite set of wheels).

The second step in the sampling process is to choose a sampling frame . This is an accessible section of the target population—usually a list with contact information—from where a sample can be drawn. If your target population is professional employees at work, because you cannot access all professional employees around the world, a more realistic sampling frame will be employee lists of one or two local companies that are willing to participate in your study. If your target population is organisations, then the Fortune 500 list of firms or the Standard & Poor’s (S&P) list of firms registered with the New York Stock exchange may be acceptable sampling frames.
Note that sampling frames may not entirely be representative of the population at large, and if so, inferences derived by such a sample may not be generalisable to the population. For instance, if your target population is organisational employees at large (e.g., you wish to study employee self-esteem in this population) and your sampling frame is employees at automotive companies in the American Midwest, findings from such groups may not even be generalisable to the American workforce at large, let alone the global workplace. This is because the American auto industry has been under severe competitive pressures for the last 50 years and has seen numerous episodes of reorganisation and downsizing, possibly resulting in low employee morale and self-esteem. Furthermore, the majority of the American workforce is employed in service industries or in small businesses, and not in automotive industry. Hence, a sample of American auto industry employees is not particularly representative of the American workforce. Likewise, the Fortune 500 list includes the 500 largest American enterprises, which is not representative of all American firms, most of which are medium or small sized firms rather than large firms, and is therefore, a biased sampling frame. In contrast, the S&P list will allow you to select large, medium, and/or small companies, depending on whether you use the S&P LargeCap, MidCap, or SmallCap lists, but includes publicly traded firms (and not private firms) and is hence still biased. Also note that the population from which a sample is drawn may not necessarily be the same as the population about which we actually want information. For example, if a researcher wants to examine the success rate of a new ‘quit smoking’ program, then the target population is the universe of smokers who had access to this program, which may be an unknown population. Hence, the researcher may sample patients arriving at a local medical facility for smoking cessation treatment, some of whom may not have had exposure to this particular ‘quit smoking’ program, in which case, the sampling frame does not correspond to the population of interest.
The last step in sampling is choosing a sample from the sampling frame using a well-defined sampling technique. Sampling techniques can be grouped into two broad categories: probability (random) sampling and non-probability sampling. Probability sampling is ideal if generalisability of results is important for your study, but there may be unique circumstances where non-probability sampling can also be justified. These techniques are discussed in the next two sections.
Probability sampling
Probability sampling is a technique in which every unit in the population has a chance (non-zero probability) of being selected in the sample, and this chance can be accurately determined. Sample statistics thus produced, such as sample mean or standard deviation, are unbiased estimates of population parameters, as long as the sampled units are weighted according to their probability of selection. All probability sampling have two attributes in common: every unit in the population has a known non-zero probability of being sampled, and the sampling procedure involves random selection at some point. The different types of probability sampling techniques include:

Stratified sampling. In stratified sampling, the sampling frame is divided into homogeneous and non-overlapping subgroups (called ‘strata’), and a simple random sample is drawn within each subgroup. In the previous example of selecting 200 firms from a list of 1,000 firms, you can start by categorising the firms based on their size as large (more than 500 employees), medium (between 50 and 500 employees), and small (less than 50 employees). You can then randomly select 67 firms from each subgroup to make up your sample of 200 firms. However, since there are many more small firms in a sampling frame than large firms, having an equal number of small, medium, and large firms will make the sample less representative of the population (i.e., biased in favour of large firms that are fewer in number in the target population). This is called non-proportional stratified sampling because the proportion of the sample within each subgroup does not reflect the proportions in the sampling frame—or the population of interest—and the smaller subgroup (large-sized firms) is oversampled . An alternative technique will be to select subgroup samples in proportion to their size in the population. For instance, if there are 100 large firms, 300 mid-sized firms, and 600 small firms, you can sample 20 firms from the ‘large’ group, 60 from the ‘medium’ group and 120 from the ‘small’ group. In this case, the proportional distribution of firms in the population is retained in the sample, and hence this technique is called proportional stratified sampling. Note that the non-proportional approach is particularly effective in representing small subgroups, such as large-sized firms, and is not necessarily less representative of the population compared to the proportional approach, as long as the findings of the non-proportional approach are weighted in accordance to a subgroup’s proportion in the overall population.
Cluster sampling. If you have a population dispersed over a wide geographic region, it may not be feasible to conduct a simple random sampling of the entire population. In such case, it may be reasonable to divide the population into ‘clusters’—usually along geographic boundaries—randomly sample a few clusters, and measure all units within that cluster. For instance, if you wish to sample city governments in the state of New York, rather than travel all over the state to interview key city officials (as you may have to do with a simple random sample), you can cluster these governments based on their counties, randomly select a set of three counties, and then interview officials from every office in those counties. However, depending on between-cluster differences, the variability of sample estimates in a cluster sample will generally be higher than that of a simple random sample, and hence the results are less generalisable to the population than those obtained from simple random samples.
Matched-pairs sampling. Sometimes, researchers may want to compare two subgroups within one population based on a specific criterion. For instance, why are some firms consistently more profitable than other firms? To conduct such a study, you would have to categorise a sampling frame of firms into ‘high profitable’ firms and ‘low profitable firms’ based on gross margins, earnings per share, or some other measure of profitability. You would then select a simple random sample of firms in one subgroup, and match each firm in this group with a firm in the second subgroup, based on its size, industry segment, and/or other matching criteria. Now, you have two matched samples of high-profitability and low-profitability firms that you can study in greater detail. Matched-pairs sampling techniques are often an ideal way of understanding bipolar differences between different subgroups within a given population.
Multi-stage sampling. The probability sampling techniques described previously are all examples of single-stage sampling techniques. Depending on your sampling needs, you may combine these single-stage techniques to conduct multi-stage sampling. For instance, you can stratify a list of businesses based on firm size, and then conduct systematic sampling within each stratum. This is a two-stage combination of stratified and systematic sampling. Likewise, you can start with a cluster of school districts in the state of New York, and within each cluster, select a simple random sample of schools. Within each school, you can select a simple random sample of grade levels, and within each grade level, you can select a simple random sample of students for study. In this case, you have a four-stage sampling process consisting of cluster and simple random sampling.
Non-probability sampling
Non-probability sampling is a sampling technique in which some units of the population have zero chance of selection or where the probability of selection cannot be accurately determined. Typically, units are selected based on certain non-random criteria, such as quota or convenience. Because selection is non-random, non-probability sampling does not allow the estimation of sampling errors, and may be subjected to a sampling bias. Therefore, information from a sample cannot be generalised back to the population. Types of non-probability sampling techniques include:
Convenience sampling. Also called accidental or opportunity sampling, this is a technique in which a sample is drawn from that part of the population that is close to hand, readily available, or convenient. For instance, if you stand outside a shopping centre and hand out questionnaire surveys to people or interview them as they walk in, the sample of respondents you will obtain will be a convenience sample. This is a non-probability sample because you are systematically excluding all people who shop at other shopping centres. The opinions that you would get from your chosen sample may reflect the unique characteristics of this shopping centre such as the nature of its stores (e.g., high end-stores will attract a more affluent demographic), the demographic profile of its patrons, or its location (e.g., a shopping centre close to a university will attract primarily university students with unique purchasing habits), and therefore may not be representative of the opinions of the shopper population at large. Hence, the scientific generalisability of such observations will be very limited. Other examples of convenience sampling are sampling students registered in a certain class or sampling patients arriving at a certain medical clinic. This type of sampling is most useful for pilot testing, where the goal is instrument testing or measurement validation rather than obtaining generalisable inferences.
Quota sampling. In this technique, the population is segmented into mutually exclusive subgroups (just as in stratified sampling), and then a non-random set of observations is chosen from each subgroup to meet a predefined quota. In proportional quota sampling , the proportion of respondents in each subgroup should match that of the population. For instance, if the American population consists of 70 per cent Caucasians, 15 per cent Hispanic-Americans, and 13 per cent African-Americans, and you wish to understand their voting preferences in an sample of 98 people, you can stand outside a shopping centre and ask people their voting preferences. But you will have to stop asking Hispanic-looking people when you have 15 responses from that subgroup (or African-Americans when you have 13 responses) even as you continue sampling other ethnic groups, so that the ethnic composition of your sample matches that of the general American population.
Non-proportional quota sampling is less restrictive in that you do not have to achieve a proportional representation, but perhaps meet a minimum size in each subgroup. In this case, you may decide to have 50 respondents from each of the three ethnic subgroups (Caucasians, Hispanic-Americans, and African-Americans), and stop when your quota for each subgroup is reached. Neither type of quota sampling will be representative of the American population, since depending on whether your study was conducted in a shopping centre in New York or Kansas, your results may be entirely different. The non-proportional technique is even less representative of the population, but may be useful in that it allows capturing the opinions of small and under-represented groups through oversampling.
Expert sampling. This is a technique where respondents are chosen in a non-random manner based on their expertise on the phenomenon being studied. For instance, in order to understand the impacts of a new governmental policy such as the Sarbanes-Oxley Act, you can sample a group of corporate accountants who are familiar with this Act. The advantage of this approach is that since experts tend to be more familiar with the subject matter than non-experts, opinions from a sample of experts are more credible than a sample that includes both experts and non-experts, although the findings are still not generalisable to the overall population at large.
Snowball sampling. In snowball sampling, you start by identifying a few respondents that match the criteria for inclusion in your study, and then ask them to recommend others they know who also meet your selection criteria. For instance, if you wish to survey computer network administrators and you know of only one or two such people, you can start with them and ask them to recommend others who also work in network administration. Although this method hardly leads to representative samples, it may sometimes be the only way to reach hard-to-reach populations or when no sampling frame is available.
Statistics of sampling
In the preceding sections, we introduced terms such as population parameter, sample statistic, and sampling bias. In this section, we will try to understand what these terms mean and how they are related to each other.
When you measure a certain observation from a given unit, such as a person’s response to a Likert-scaled item, that observation is called a response (see Figure 8.2). In other words, a response is a measurement value provided by a sampled unit. Each respondent will give you different responses to different items in an instrument. Responses from different respondents to the same item or observation can be graphed into a frequency distribution based on their frequency of occurrences. For a large number of responses in a sample, this frequency distribution tends to resemble a bell-shaped curve called a normal distribution , which can be used to estimate overall characteristics of the entire sample, such as sample mean (average of all observations in a sample) or standard deviation (variability or spread of observations in a sample). These sample estimates are called sample statistics (a ‘statistic’ is a value that is estimated from observed data). Populations also have means and standard deviations that could be obtained if we could sample the entire population. However, since the entire population can never be sampled, population characteristics are always unknown, and are called population parameters (and not ‘statistic’ because they are not statistically estimated from data). Sample statistics may differ from population parameters if the sample is not perfectly representative of the population. The difference between the two is called sampling error . Theoretically, if we could gradually increase the sample size so that the sample approaches closer and closer to the population, then sampling error will decrease and a sample statistic will increasingly approximate the corresponding population parameter.
If a sample is truly representative of the population, then the estimated sample statistics should be identical to the corresponding theoretical population parameters. How do we know if the sample statistics are at least reasonably close to the population parameters? Here, we need to understand the concept of a sampling distribution . Imagine that you took three different random samples from a given population, as shown in Figure 8.3, and for each sample, you derived sample statistics such as sample mean and standard deviation. If each random sample was truly representative of the population, then your three sample means from the three random samples will be identical—and equal to the population parameter—and the variability in sample means will be zero. But this is extremely unlikely, given that each random sample will likely constitute a different subset of the population, and hence, their means may be slightly different from each other. However, you can take these three sample means and plot a frequency histogram of sample means. If the number of such samples increases from three to 10 to 100, the frequency histogram becomes a sampling distribution. Hence, a sampling distribution is a frequency distribution of a sample statistic (like sample mean) from a set of samples , while the commonly referenced frequency distribution is the distribution of a response (observation) from a single sample . Just like a frequency distribution, the sampling distribution will also tend to have more sample statistics clustered around the mean (which presumably is an estimate of a population parameter), with fewer values scattered around the mean. With an infinitely large number of samples, this distribution will approach a normal distribution. The variability or spread of a sample statistic in a sampling distribution (i.e., the standard deviation of a sampling statistic) is called its standard error . In contrast, the term standard deviation is reserved for variability of an observed response from a single sample.

Social Science Research: Principles, Methods and Practices (Revised edition) Copyright © 2019 by Anol Bhattacherjee is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Sampling Techniques: Definition, Types, and Examples
Sampling is an inherent human trait we follow whenever we want to study something, but the domain is huge enough to force us to base our study on a sub-sample only. This is true for most of the studies in the practical world. The whole population is never accessible; even if it is, it’s not worth going through all of it.
Why Do We Need Sampling Techniques?
Research benefits greatly from sampling. It is one of the most crucial elements that affect how accurate your study or survey results are. If your sample contains any errors, the outcome will be affected accordingly. Depending on the situation and necessity, numerous methodologies aid in sample collection. But before diving into the topic, let’s look at some essential statistical terms you might need to remember.
A population is a group of related objects or occurrences relevant to a particular topic or experiment.
It is the particular group from whom you will get data. The sample size is always smaller than the population as a whole.
It is the object or person being observed.
It is a list of everything in the population that can be observed, whether it be people or other objects.
What is a Sampling Technique?
It is seldom possible to gather data from every member of a group of individuals when conducting research on them. So, what do you do? Well, you pick a sample instead. The population that will actually take part in the study is the sample.
What are the different types of Sampling Techniques?
1. probability sampling, 2. non-probability sampling techniques.
Let’s go through both, along with their sub-types.
Probability Sampling Techniques
Using a set of predetermined criteria and a random selection of population members, a researcher uses the sampling technique known as probability sampling. With this selection criteria, each member has an equal chance of being included in the sample. Our best shot at producing a sample that is accurately representative of the population and enables us to draw robust statistical conclusions about the entire group is through probability sampling. Random sampling is another name for it. It has four sub-divisions:
1. Simple Random Sampling Technique:
Every person in the population has an equal probability of getting chosen in a simple random sampling. The entire population should be part of your sampling frame. The Simple Random Sampling method is one of the top probability sampling approaches that aid in time and resource conservation. It is a reliable way to gather information.
The fact that this method is the most straightforward for probability sampling is a significant benefit. It does, however, come with a disclaimer: it might not choose enough people who fit our criteria. We use it when we don’t know anything about the target population beforehand.
A company has decided to give a bonus to 10 of its employees. These employees will be selected randomly through any method from the whole company.
2. Systematic Sampling Technique:
In systematic sampling , the first person is chosen randomly, and the others are selected according to a predetermined sampling interval. Put each person, in the population, in some kind of order and select every nth member to be in the sample from a random starting point.
Suppose you need to choose a sample of 50 people from a population of 100. You will select every 2nd person on the list.
3. Stratified Sampling Technique:
A researcher wants to know the number of people in a country who went to college. He\she would divide the country into cities and then further divide the cities into age groups. He\she would then randomly select a sample to get information about the topic.
4. Cluster Sampling Technique:
The sample has a higher chance of mistakes because there may be significant differences between clusters, but it is pretty helpful for handling oversized and dispersed populations. It is challenging to ensure that the sampled clusters accurately reflect the entire population.
A mobile company is looking to survey people from a country about the usage of phones. It would divide the country into cities, known as clusters, and then further divide the cities into areas (clusters) that are more populated.
Non-probability Sampling Techniques
In non-probability sampling, participants are chosen at random by the researcher. This type of sampling is not a set or predetermined selection procedure. Due to this, it is challenging to ensure that every component of a population has an equal chance of being represented in a sample. It enables simple data collection. A non-representative sample that cannot yield generalizable conclusions carries considerable risk. Non-random sampling is another name for this.
1. Convenience Sampling Technique:
Although it is quick and affordable, this method cannot yield generalizable conclusions because it is impossible to determine whether the sample reflects the population. Considering how simple it was for the researcher to conduct the study and contact the subjects, it is frequently referred to as convenience sampling. Researchers with almost no authority choose the sample components, and they are selected entirely based on accessibility rather than representativeness.
When gathering feedback is time and money-constrained, this non-probability sampling technique is used.
2. Purposive Sampling Technique:
In the purposive sampling technique , the researcher uses their knowledge to choose a sample that will be most helpful to the research’s objectives. This sort of sampling is also known as selective or judgment sampling. It is frequently employed when the researcher prefers to learn in-depth information on a particular occurrence versus drawing general conclusions from statistics or when the population is relatively tiny and focused.
3. Snowball Sampling Technique:
When subjects are challenging to trace, researchers use the snowball sampling technique . To discover people who are interested in participating in the study, the researcher contacts other people they know. Using the snowball theory, researchers can follow a few categories to interview and gather data in situations where it is challenging to survey people on a particular topic. This sampling strategy is also used by researchers when the subject is highly delicate and taboo . The population expands like a snowball as a result of this referral strategy. This sampling technique works well when it’s challenging to pinpoint a sampling frame.
Snowball sampling carries a considerable risk of selection bias because the people who are referred will have characteristics in common with the person who refers them.
For example, if a researcher is conducting a study about the psychological effects of STDs, the snowball sampling technique would be useful as STDs are considered taboo in most areas.
4. Quota Sampling Technique:
This approach divides the sample into groups based on traits and then interviews. The sample should reflect the population regarding the proportion of traits and attributes. The researcher stops collecting data once each group has adequate sample units. This sampling technique has numerous benefits, including its ability to compare groups within the population, quick and uncomplicated execution, and lack of need for a sample frame. The division of the groups may not be correct, and there is a possibility of some bias.
Sampling is a very extensive yet one of the most undermined areas in research and general statistical studies. People don’t realize how important it is to choose suitable sampling methods to achieve the correct results. Most use the same one or two generic approaches, regardless of their use case, resulting in improper results.
So, to achieve your research objectives properly, selecting a sampling technique carefully while taking everything into consideration is crucial. In order to help you make your decision on a broader category, I’ve made up a table to help you choose the right approach for you, highlighting the major differences between probability vs. non-probability sampling techniques .
| Using a process based on probability theory, samples from a bigger population are picked in the sampling approach known as probability sampling. | Non-probability sampling is a sampling technique in which the researcher selects samples based on the researcher’s subjective judgment rather than random selection. |
| The population is randomly selected. | The population is arbitrarily selected. |
| The population’s demographics are clearly represented because a procedure for selecting the sample was used. | The portrayal of population demographics is typically biased since the sampling methodology is arbitrary. |
| It takes longer to complete since the research design defines the selection criteria before the study starts. | Since neither the sample nor its selection criteria are ambiguous, this kind of sampling technique is quick. |
| The research is conclusive. | The research is exploratory. |
| Because of the complete neutrality of this form of sampling, the findings are both conclusive and unbiased. | The research is speculative because this highly skewed sampling method affects the outcomes. |
As an IT Engineer, who is passionate about learning and sharing. I have worked and learned quite a bit from Data Engineers, Data Analysts, Business Analysts, and Key Decision Makers almost for the past 5 years. Interested in learning more about Data Science and How to leverage it for better decision-making in my business and hopefully help you do the same in yours.
Recent Posts
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Sweepstakes
- Guided Meditations
- Verywell Mind Insights
- 2024 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
How and Why Sampling Is Used in Psychology Research
Verywell / Nusha Ashjaee
- Why Use Samples
- Probability Samples
- Nonprobability Samples
Sampling Errors
In statistics, a sample is a subset of a population that is used to represent the entire group as a whole. When doing psychology research, it is often impractical to survey every member of a particular population because the number of people is simply too large. To make inferences about the characteristics of a population, psychology researchers use a random sample .
Keep reading to learn about how samples are used in psychology research, the different types of samples, and the errors that may occur when using samples.
Why Psychology Researchers Use Samples
When researching an aspect of the human mind or human behavior , psychology researchers can rarely collect data from every single affected individual. Instead, they use a smaller sample of individuals to represent the larger group.
The goal when choosing a sample is to make sure it represents the entire group accurately. This means that the sample should reflect the diverse characteristics present in the total population. The sample must accurately represent the population in question so researchers can generalize their results to the larger group with statistical analysis .
In psychological research and other types of social science research , experimenters typically rely on a few different sampling methods. These can be grouped into probability and nonprobability samples.
Types of Probability Samples
Probability sampling means every individual in a population stands a chance of being selected. Because probability sampling uses random selection , every subset of the population has an equal chance of being represented in the sample.
Probability samples are more representative of large populations and researchers are better able to generalize their results to the group as a whole when they use probability samples.
Simple Random Sampling
Simple random sampling is, as the name suggests, the simplest type of probability sampling. Psychology researchers take every individual in a population and randomly select individuals to compose their sample, often by using some type of computer program or random number generator.
Stratified Random Sampling
Stratified random sampling involves separating the population into subgroups and then taking a simple random sample from each of these subgroups. For example, researchers may divide the population into subgroups based on race, sex, or age, and then take a simple random sample of each of these groups.
Stratified random sampling often provides greater statistical accuracy than simple random sampling because it ensures each of the subgroups is accurately represented in the sample.
Cluster Sampling
Cluster sampling involves dividing a population into smaller clusters, often based on geographic location. A random sample of these clusters is then selected, and all of the subjects within the cluster are measured.
For example, imagine you are doing a study on school principals in your state. Collecting data from every single school principal would be cost-prohibitive and time-consuming. But, if you were to use a cluster sampling method, you would randomly select five counties from your state and then collect data from every subject in each of those five counties to create a representative sample.
Probability sampling methods allow psychology researchers to get a more representative sample. Techniques that might be used include simple random sampling, stratified random sampling, and cluster sampling.
Types of Nonprobability Samples
Nonprobability sampling involves selecting participants using methods that do not give every subset of a population an equal chance of being represented. For example, a study may recruit participants from an already established group of volunteers.
One problem with this type of sample is that volunteers might differ from non-volunteers on certain variables, which can make it difficult to generalize the results to the entire population.
Convenience Sampling
Convenience sampling involves selecting participants for a study based on what is most convenient–people who are easily accessible and have the time. If you have ever volunteered for a psychology study conducted through your university's psychology department, then you have participated in a study that relied on a convenience sample.
Studies that rely on asking for volunteers or using clinical samples available to the researcher are also examples of convenience samples.
Purposive Sampling
Purposive sampling involves seeking out individuals who meet certain criteria. For example, a researcher might be interested in learning how college graduates between the ages of 20 and 35 feel about a topic. In purposive sampling, the researcher might conduct telephone interviews to intentionally seek out people who meet their criteria.
Quota Sampling
Quota sampling involves intentionally sampling specific proportions of each subgroup within a population. For example, political pollsters might be interested in researching the opinions of a population on a certain political issue. If they use simple random sampling, they might miss certain subsets of the population by chance.
Instead, they establish criteria to assign each subgroup a certain percentage of the sample. This differs from stratified sampling because, to find individuals within each subgroup, researchers use non-random methods to fill the quotas for each subgroup.
Nonprobability sampling can also be used when selecting a sample in psychology research. Such methods are less representative of the general population. Techniques include convenience sampling, purposive sampling, and quota sampling.
Sampling errors are differences between what is present in a population and what is present in a sample. Because sampling cannot include every single individual in a population, errors can occur. This can ultimately have an impact on the results of psychology research.
While it is impossible to know exactly how great the difference between the population and sample may be, researchers can statistically estimate the size of the sampling errors. In political polls, for example, you might often hear of the margin of errors expressed by certain confidence levels.
In general, the larger the sample size, the smaller the level of error. This is simply because the closer the sample is to the size of the total population, the more likely it is to accurately capture all of the characteristics of the population.
The only way to completely eliminate sampling error is to collect data from the entire population, which is often simply too costly and time-consuming. Sampling errors can be minimized, however, by using randomized probability testing and large sample size.
Samples are important in psychology research because they allow scientists to study what is happening in a larger population without having to reach every individual in the entire group.
Different types of samples can be used depending on what researchers are studying and the resources they have available to collect data. Probability samples tend to be more representative of the larger group. Nonprobability samples, on the other hand, tend to involve selecting participants based on availability and studying specific subsets of a larger group, which is less representative of the larger group.
Sampling errors can occur, however, with any type of sampling. To minimize errors, researchers strive to use large, representative samples.
Valliant R, Dever J. Estimating propensity adjustments for volunteer web surveys . Sociol Methods Res . 2011;40(1):105-137. doi:10.1177/0049124110392533
Lin L. Bias caused by sampling error in meta-analysis with small sample sizes . PLoS ONE . 2018;13(9):e0204056. doi:10.1371/journal.pone.0204056
Goodwin CJ. Research In Psychology: Methods and Design, 12th ed . John Wiley and Sons.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
Our websites may use cookies to personalize and enhance your experience. By continuing without changing your cookie settings, you agree to this collection. For more information, please see our University Websites Privacy Notice .
Neag School of Education
Educational Research Basics by Del Siegle
Selecting Subjects for Survey Research…
Sampling (Selecting Subjects) . ..
The main purpose of survey research is to describe the characteristics of a population. This is usually accomplished by collecting data from a sample. Therefore, the first step in sampling is to define the population.
POPULATION–> The population is the group consisting of all people to whom we (as researchers) wish to apply our findings. lf we were interested in the reading level of 3rd graders in Connecticut, the population would be all third graders in Connecticut. The data (information) we collect from populations are called PARAMETERS and are said to be DESCRIPTIVE. We label the number of subjects (observations) in a population with an upper case N (N=300). The first step in sampling is to define the population (3rd graders in Connecticut). The actual population to whom the researcher wishes to apply his or her findings is called the TARGET population. Often the TARGET population is not available, and the research must use an ACCESSIBLE POPULATIONS. In this case, the researcher can only apply (generalize) his or her findings to that group.
SAMPLE–> Subsets of people are usually used to conduct studies. These subsets are called samples. The samples are used to represent the population from which they were drawn. The data we collect from samples are called STATISTICS and are said to be INFERENTIAL (because we are making inferences about the POPULATION with data collected from the SAMPLE). We label the number of subjects (observations) in a sample with a lower case n (n=25).
Statistics are used to effectively communicate numerical information to other people. In statistics we are…
- …Looking at RELATIONSHIPS among (between) characteristics (i.e., salary & job satisfaction; food consumption & energy) — Correlation Research (which we study in a different unit) is an example of research involving relationships.
- …Looking at DIFFERENCES between (among) groups (i.e., males & females; experiment & control) — Experimental Research (which we study in a different unit) is an example of research that looks at differences.
- …Looking to DESCRIBE the characteristics of the population from data collected from a sample — Survey Research. The two major types of surveys are cross-sectional survey and longitudinal survey (trend, cohort, and panel studies) .
Inferential statistics are used to determine how likely it is that characteristics exhibited by a sample of people are an accurate description of those characteristics exhibited by the population of people from which the sample was drawn.
The term statistically significant (p < .05) is used merely as a way of indicating the chances are at least 95 out of 100 that the findings obtained from the sample of people who participated in the study are similar to what the findings would be if one were actually able to carry out the study with the entire population. In other words, with p< . 05 we believe that if we repeated our study 100 times with different samples from a population where there really was no difference (or relationship), that the results we found with our sample would occur just by chance less than 5 in 100 times.
The first step in selecting a sample is to define the population to which one wishes to generalize the results of a study. Unfortunately, one may not be able to collect data from his or her TARGET POPULATION. In this case, an ACCESSIBLE POPULATION is used. If the latter is used, care must be taken not to generalize beyond the ACCESSIBLE POPULATION.
-The sample is drawn from the population
- -Data is collected from the sample
- -Statistics are used to determine how likely the sample results are reflective of the population
A number of different strategies can be used to select a sample. Each of the strategies has strengths and weaknesses. There are times when the research results from the sample cannot be applied to the population because threats to external validity exist with the study. The most important aspect of sampling is that the sample represents the population.
*CHOOSING A SAMPLE*
- SIMPLE RANDOM SAMPLING – Each subject in the population has an equal chance of being selected
- STRATIFIED RANDOM SAMPLING – A representative number of subjects from various subgroups
- TWO STAGE CLUSTER RANDOM SAMPLING – Samples chosen from pre-existing groups
- SYSTEMATIC SAMPLING – Selection of every nth (i.e., 5th) subject in the population
- CONVENIENCE SAMPLING – Subjects are easily accessible
- PURPOSIVE SAMPLING – Subjects are selected because of some characteristic
SIMPLE RANDOM SAMPLING – Each subject in the population has an equal chance of being selected regardless of what other subjects have or will be selected. While this is desirable, it may not be possible.
A random number table or computer program (random generator) is often employed to generate a list of random numbers to use.
A simple procedure is to place the names from the population is a hat and draw out the number of names one wishes to use for a sample.
STRATIFIED RANDOM SAMPLING – A representative number of subjects from various subgroups is randomly selected.
Suppose we wish to study computer use of educators in the Hartford system. Assume we want the teaching level (elementary, middle school, and high school) in our sample to be proportional to what exists in the population of Hartford teachers.
First we must determine what percentage of the teachers in the Hartford system are elementary, middle school, and high school. For this example, we will use 50%, 20% and 30% respectively. Because those percentages exist in our population, we want our sample to have the same percentages.
Let’s also assume that we want to sample 200 teachers. Since 50% of those teachers need to be elementary teachers, we need 100 elementary teachers in our sample (200 X .50). To achieve this, we obtain a list of all of the elementary teachers in the system. From that list we randomly select 100.
Similarly, we use a list of all of the middle school teachers and randomly select 40 (20% of 200). We do the same for the high school teachers and select 60.
The sample we selected is exactly proportional to the population with regards to teaching level. If we had not used STRATIFIED RANDOM SAMPLING we might have reached a similar proportion, or by chance, we might have had over representation of one of the groups.
However, the main reason we do stratified is to better understand each of the subgroups . Therefore, researchers may over sample some of the subgroups and then weight the results so they are still proportional. The reason we oversample is because we need a large enough sample to represent the subgroup.
CLUSTER RANDOM SAMPLING – Samples chosen from pre-existing groups. Groups are selected and then the individuals in those groups are used for the study.
If we wished to know the attitude of fifth graders in Connecticut about reading, it might be difficult and costly to visit each fifth grade in the state to collect our data. We could randomly select 10 schools (our clusters) and survey the students in those schools. Each school in the state would have an equal chance of being selected, but only the students at the selected schools would be surveyed.
An extension of the Cluster Random Sample is the TWO-STAGE CLUSTER RANDOM SAMPLE. ln this situation, the clusters (classes in our example) are randomly selected and then students within those clusters are randomly selected.
SYSTEMATIC SAMPLING -Systematic sampling is an easier procedure than random sampling when you have a large population and the names of the targeted population are available. Systematic sampling involves selection of every nth (e.g., 5th) subject in the population to be in the sample.
Suppose you had a list of 10,000 voters in your school district and you wished to sample 400 voters to see if they supported special funding for a new school program.
We divide the number in the population (10,000) by the size of the sample we wish to use (400) and we get the interval we need to use when selecting subjects (25). In order to select 400 subjects, we need to select every 25 person on the list.
Before we start selecting subjects, we need to select a random starting point on the list. That starting point must be with one of the first 25 names on the list for this example. We would use a random table or generator to determine the starting point. Once we have the starting point, we select that subject and every 25th subject after that on the list.
CONVENIENCE SAMPLING – Subjects are selected because they are easily accessible. This is one of the weakest sampling procedures. An example might be surveying students in one’s class. Generalization to a population can seldom be made with this procedure.
“Researchers often need to select a convenience sample or face the possibility that they will be unable to do the study. Although a sample randomly drawn from a population ls more desirable, it usually is better to do a study with a convenience sample than to do no study at all– assuming, of course, that the sample suits the purpose of the study” {Gall, Borg, & Gall, 1996, p. 228).
Gall, M. D., Borg, W.R., & Gall, J.P. (1996). Educational Research: An Introduction. White Plains, NY: Longman.
PURPOSIVE SAMPLING-Subjects are selected because of some characteristic. Patton (1990) has proposed the following cases of purposive sampling. Purposive sampling is popular in qualitative research. Note: These categories are provided only for additional information for EPSY 5601 students.
- Extreme or Deviant Case – Learning from highly unusual manifestations of the phenomenon of interest, such as outstanding success/notable failures, top of the class/dropouts, exotic events,
- Intensity – Information-rich cases that manifest the phenomenon intensely, but not extremely, such as good students/poor students, above average/below
- Maximum Variation – Purposefully picking a wide range of variation on dimensions of interest…documents unique or diverse variations that have emerged in adapting to different conditions. Identifies important common patterns that cut across
- Homogeneous – Focuses, reduces variation, simplifies analysis, facilitates group interviewing.
- Typical Case – Illustrates or highlights what is typical, normal,
- Stratified Purposeful – Illustrates characteristics of particular subgroups of interest; facilitates
- Critical Case – Permits logical generalization and maximum application of information to other cases because if it’s true of this once case it’s likely to be true of a!I other
- Snowball or Chain – Identifies cases of interest from people who know people who know people who know what cases are information-rich, that is, good examples for study, good interview
- Criterion – Picking all cases that meet some criterion, such as all children abused in a treatment facility. Quality assurance.
- Theory-Based or Operational Construct – Finding manifestations of a theoretical construct of interest so as to elaborate and examine the
- Confirming or Disconfirming – Elaborating and deepening initial analysis, seeking exceptions, testing variation.
- Opportunistic – Following new leads during fieldwork, taking advantage of the unexpected, flexibility.
- Random Purposeful – (still small sample size) Adds credibility to sample when potential purposeful sample is larger than one can handle. Reduces judgment within a purposeful category. (Not for generalizations or representativeness.)
- Politically Important Cases -Attracts attention to the study {or avoids attracting undesired attention by purposefully eliminating from the sample politically sensitive cases).
- Convenience – Saves time, money, and Poorest rational; lowest credibility. Yields information-poor cases.
- Combination or Mixed Purposeful – Triangulation, flexibility, meets multiple interests and needs. (Patton, 1990)
Patton, M. Q. (1990). Qualitative evaluation and research methods (2nd ed.). Newbury Park, CA: Sage Publications.
Sample Size

Larger Samples are needed when…
- a large number of uncontrolled variables are interacting unpredictably
- the total sample is to be divided into several subsamples (the researcher is interested in also studying subgroups within the sample)
- the population is made up of a wide range of variables and characteristics
- differences in the results (effect size) are expected to be small
- high attrition of subjects is expected
Sample Sizes for Surveys
The number of subjects you select (use a sample size calculator to determine this) will influence how confident you can be that your results depict the population from which the sample was drawn.
The confidence interval is the plus-or-minus figure usually reported in newspaper or television opinion poll results. For example, if you use a confidence interval of 4 and 47% percent of your sample picks an answer you can be “sure” that if you had asked the question of the entire relevant population between 43% (47-4) and 51% (47+4) would have picked that answer.
The confidence level tells you how sure you can be. It is expressed as a percentage and represents how often the true percentage of the population who would pick an answer lies within the confidence interval. The 95% confidence level means you can be 95% certain of the confidence interval; the 99% confidence level means you can be 99% certain of the confidence interval. Most researchers use the 95% confidence level.
When you put the confidence level and the confidence interval together, you can say that you are 95% sure that the true percentage of the population is between 43% and 51%.
The wider the confidence interval you are willing to accept, the more certain you can be that the whole population answers would be within that range. For example, if you asked a sample of 1000 people in a city which brand of cola they preferred, and 60% said Brand A, you can be very certain that between 40 and 80% of all the people in the city actually do prefer that brand, but you cannot be so sure that between 59 and 61% of the people in the city prefer the brand.
Factors that Affect Confidence Intervals
There are three factors that determine the size of the confidence interval for a given confidence level. These are: sample size, percentage difference, and population size.
The larger your sample, the more confident you can be that their answers truly reflect the population. This indicates that for a given confidence level, the larger your sample size, the smaller your confidence interval. However, the relationship is not linear (i.e., doubling the sample size does not half the confidence interval).
Percentage Difference
Your accuracy also depends on the percentage of your sample that picks a particular answer. If 99% of your sample said “Yes” and 1% said “No” the chances of error are remote, irrespective of sample size. However, if the percentages are 51% and 49% the chances of error are much greater. It is easier to be sure of extreme answers than of middle-of-the-road ones.
When determining the sample size needed for a given level of accuracy you must use the worst case percentage (50%). You should also use this percentage if you want to determine a general level of accuracy for a sample you already have. To determine the confidence interval for a specific answer your sample has given, you use the percentage of the sample that selected that answer, which if it different than 50%, gives a smaller interval.
Population Size
How many people are there in the group your sample represents? This may be the number of people in a city you are studying, the number of people who buy new cars, etc. Often you may not know the exact population size. This is not a problem. The mathematics of probability proves the size of the population is irrelevant, unless the size of the sample exceeds a few percent of the total population you are examining. This means that a sample of 500 people is equally useful in examining the opinions of a state of 15,000,000 as it would a city of 100,000. For this reason, a sample calculator ignores the population size when it is “large” or unknown. Population size is only likely to be a factor when you work with a relatively small and known group of people.
Note : The confidence interval calculations assume you have a genuine random sample of the relevant population. If your sample is not truly random, you cannot rely on the intervals. Non-random samples usually result from some flaw in the sampling procedure. An example of such a flaw is to only call people during the day, and miss almost everyone who works. For most purposes, the non-working population cannot be assumed to accurately represent the entire (working and non-working) population.Information about confidence intervals was obtained from The Survey System
Del Siegle, Ph.D. Neag School of Education – University of Connecticut [email protected] www.delsiegle.com
- How it works

Population vs Sample – Definitions, Types & Examples
Published by Alvin Nicolas at September 20th, 2021 , Revised On July 19, 2023
Wondering who wins in the Population vs. Sample battle? Don’t know which one to choose for your survey?
If you are hunting similar questions, congratulations, you have come to the right place.
The Sample and Population sections tend to be a stumbling block for most students, if not all. And if you are one of those people, now is the perfect time to seize an opportunity. This guide contains all the information in the world to sweep through the methodology section of your dissertation proficiently.
Sounds interesting? Let’s get started then!
What is Population in Research?
Population in the research market comprises all the members of a defined group that you generalize to find the results of your study. This means the exact population will always depend on the scope of your respected study. Population in research is not limited to assessing humans; it can be any data parameter, including events, objects, histories, and more possessing a common trait. The measurable quality of the population is called a parameter .
For instance…
If you are to evaluate findings for Health Concerns of Women , you might have to consider all the women in the world that are dead, alive, and will live in the future.
|
|
Types of Population
Though there are different types and sub-categories of population, below are the four most common yet important ones to consider.

Countable Population
As the term itself explains, this type of population is one that can be numbered and calculated. It is also known as finite population . An example of a finite or countable population would be all the students in a college or potential buyers of a brand. A countable population in statistical analysis is thought to be of more benefit than other types.
Uncountable Population
The uncountable population, primarily known as an infinite population, is where the counting units are beyond one’s consideration and capabilities. For instance, the number of rice grains in the field. Or the total number of protons and electrons on a blank page. The fact that this type of population cannot be calculated often leaves room for error and uncertainty.
Hypothetical Population
This is the population whose unit is not available in a tangible form. Although the population in research analysis includes all sets of possible observations, events, and objects, there still are situations that can only be hypothetical. The perfect example to explain this would be the population of the world. You can give an estimated and hypothetical value gathered by different governments, but can you count all humans existing on the planet? Certainly, no! Another example would be the outcome of rolling dice.
Existent Population
The existent population is the opposite of a hypothetical population, i.e., everything is countable in a concrete form. All the notebooks and pens of students of a particular class could be an example of an existent population.
Is all clear?
Let us move on to the next important term of this guide.
What is Sample in Research?
In quantitative research methodology , the sample is a set of collected data from a defined procedure. It is basically a much smaller part of the whole, i.e., population. The sample depicts all the members of the population that are under observation when conducting research surveys . It can be further assessed to find out about the behavior of the entire population data. The measurable quality of the sample is called a statistic .
Say you send a research questionnaire to all the 200 contacts on your phone, and 42 of them end up filling up the forms. Your sample here is the 42 contacts that participated in the study. The rest of the people who did not participate but were sent invitations become part of your sampling frame . The sampling frame is the group of people who could possibly be in your research or can be a good fit, which here are the 158 people on your phone.
Can you think of more examples?
Before we start with the sampling types, here are a few other terminologies related to sampling for a better understanding.
Sample Size : the total number of people selected for the survey/study
Sample Technique : The technique you use in order to get your desired sample size.
Pro Tip: Use a sample for your research when you have a larger population, and you want to generalize your findings for the entire population from this sample.
What data collection best suits your research?
- Find out by hiring an expert from ResearchProspect today!
- Despite how challenging the subject may be, we are here to help you.

Types of Sampling Methods
There are two major types of sampling; Probability Sampling and Non-probability Sampling.
Probability Sampling
In this type of sampling, the researcher tends to set a selection of a few criteria and selects members of a population randomly. This means all the members have an equal chance to be a part of the study.
For example, you are to examine a bag containing rice or some other food item. Now any small portion or part you take for observation will be a true representative of the whole food bag.
It is further divided into the following five types:

- Simple Random Sampling
In this type of probability sampling, the members of the study are chosen by chance or randomly. Wondering if this affects the overall quality of your research? Well, it does not. The fact that every member has an equal chance of being selected, this random selection will do just as fine and speak well for the whole group. The only thing you need to make sure of is that the population is homogenous , like the bag of rice.
- Systematic Sampling
In systematic sampling, the researcher will select a member after a fixed interval of time. The member selected for the study after this fixed interval is known as the Kth element.
For example, if the researcher decides to select a member occurring after every 30 members, the Kth element here would be the 30th element.
- Stratified Random Sampling
If you know the meaning of strata, you might have guessed by now what stratified random sampling is. So, in this type of sampling, the population is first divided into sub-categories. There is no hard and fast rule for it; it is all done randomly.
So, when do we need this kind of sampling?
Stratified random sampling is adopted when the population is not homogenous. It is first divided into groups and categories based on similarities, and later members from each group are randomly selected. The idea is to address the problem of less homogeneity of the population to get a truly representative sample.
- Cluster Sampling
This is where researchers divide the population into clusters that tend to represent the whole population. They are usually divided based on demographic parameters , such as location, age, and sex. It can be a little difficult than the ones earlier mentioned, but cluster sampling is one of the most effective ways to derive interface from the feedback.
For example, suppose the United States government wishes to evaluate the number of people taking the first dose of the COVID-19 vaccine. In that case, they can divide it into groups based on various country estates. Not only will the results be accurate using this sampling method, but it will also be easier for future diagnoses.
- Multi-stage Sampling
Multi-stage sampling is similar to cluster sampling, but let’s say, a complex form of it. In this type of cluster sampling, all the clusters are further divided into sub-clusters. It involves multiple stages, thus the name. Initially, the naturally occurring categories in a population are chosen as clusters, then each cluster is categorized into smaller clusters, and lastly, members are selected from each smaller cluster.
How many stages are enough?
Well, that depends on the nature of your study/research. For some, two to three would be more than enough, while others can take up to 10 rounds or more.
Non-Probability Sampling
Non-probability sampling is the other sampling type where you cannot calculate the probability or chances of any members selected for research. In other words, it is everything the probability sampling is NOT. We just figured out that probability sampling includes selection by chance; this one depends on the subjective judgment of the researcher.
For example, one member might have a 20 percent chance of getting selected in non-probability sampling, while another could have a 60 percent chance.
Get statistical analysis help at an affordable price
- An expert statistician will complete your work
- Rigorous quality checks
- Confidentiality and reliability
- Any statistical software of your choice
- Free Plagiarism Report

Which type of sampling do you think is better?
The debate on this might prevail forever because there is no correct answer for this. Both have their advantages and disadvantages. While non-probability sampling cannot be reliable, it does save your time and costs. Similarly, if probability sampling yields accurate results, it also is not easy to use and sometimes impossible to be conducted, especially when you have a small population at hand.
Types of Non-Probability Sampling
The Four types of non-probability sampling are:
|
| |||
|---|---|---|---|
- Convenience Sampling
Convenience sampling relies on the ease of access to specific subjects such as students in the college café or pedestrians on the road. If the researcher can conveniently get the sample for their study, it will fall under this type of sampling. This type of sampling is usually effective when researchers lack time, resources, and money. They have almost zero authority to choose the sample elements and are purely done on immediacy. You send your questionnaire to random contacts on your phone would be convenience sampling as you did not walk extra miles to get the job done.
- Purposive Sampling
Purposive sampling is also known as judgmental sampling because researchers here would effectively consider the study’s purpose and some understanding of what to expect from the target audience. In other words, the target audience is defined here. For instance, if a study is conducted exclusively for Coronavirus patients, all others not affected by the virus will automatically be rejected or excluded from the study.
- Quota Sampling
For quota sampling, you need to have a pre-set standard of sample selection. What happens in quota sampling is that the sample is formed on the basis of specific attributes so that the qualities of this sample can be found in the total population. Slightly complex but worth the hassle.
- Snowball Sampling
Lastly, this type of non-probability sampling is applied when the subjects are rare and difficult to get. For example, if you are to trace and research drug dealers, it would be almost impossible to get them interviewed for the study. This is where snowball sampling comes into play. Similarly, writing a paper on the mental health of rape victims would also be a hard row to hoe. In such a situation, you will only tract a few sources/members and base the rest of your research on it.
To put it briefly, your sample is the group of people participating in the study, while the population is the total number of people to whom the results will apply. As an analogy, if the sample is the garden in your house, the population will be the forests out there.
Now that you have all the details on these two, can you spot three differences between population and sample ?
Well, we are sure you can give more than just three.
Here are a few differences in case you need a quick revision.
Differences between Population and Sample
| Sample | Population |
|---|---|
| Part of a larger group/population | The whole group |
| Characteristics are known as statistics | Characteristics are called parameters |
| The statistics are predicted/known | Parameters are unknown/unpredictable |
| Has a margin of error | True representation of opinion |
| Example: Top 10 students of the class | Example: All the students of the class |
This brings us to the end of this guide. We hope you are now clear on these topics and have made up your mind to use a sample for your research or population. The final choice is yours; however, make sure to keep all the above-mentioned facts and particulars in mind and see what works best for you.
Meanwhile, if you have questions and queries or wish to add to this guide, please drop a comment in the comments section below.
FAQs About Population vs. Sample
How can you identify a sample and population.
Sample is the specific group you collect data from, and the population is the entire group you deduce conclusions about. The population is the bigger sample size.
What is a population parameter?
Parameter is some characteristic of the population that cannot be studied directly. It is usually estimated by numbers and figures calculated from the sample data.
Is it better to use a sample instead of a population?
Yes, if you looking for a cost-effective and easier way, a sample is the better option.
What is an example of statistics?
If one office is the sample of the population of all offices in a building, then the average of salaries earned by all employees in the sample office annually would be an example of a statistic .
Does a sample represent the entire population?
Not always. Only a representative sample reflects the entire population of your study. It is an unbiased reflection of what the population is actually like. For instance, you can evaluate the effectiveness by dividing your population on the basis of gender, education, profession, and so on. It depends on how much information is available about your population and the scope of your study. Not to mention how detailed you want your study to be.
You May Also Like
A dependent variable is one that completely depends on another variable, mostly the independent one.
a multiple linear regression model is used when there are two or more independent variables—x1 and x2—that are predicted to change another variable, y.
The standard normal distribution is a special kind of normal distribution where the mean is 0, and the standard deviation is 1.
USEFUL LINKS
LEARNING RESOURCES

COMPANY DETAILS

- How It Works
Pardon Our Interruption
As you were browsing something about your browser made us think you were a bot. There are a few reasons this might happen:
- You've disabled JavaScript in your web browser.
- You're a power user moving through this website with super-human speed.
- You've disabled cookies in your web browser.
- A third-party browser plugin, such as Ghostery or NoScript, is preventing JavaScript from running. Additional information is available in this support article .
To regain access, please make sure that cookies and JavaScript are enabled before reloading the page.
Our Most Popular Products
Not sure where to start? See the most popular products and NGS services that your colleagues use the most.
DNA/RNA Shield Saliva Sputum Collection Kit - DX
The DNA/RNA Shield Saliva/Sputum Collection Kit is a collection kit for DNA and RNA transport and stabilization for saliva/sputum samples.

- DNA/RNA Shield™
- Direct to PCR
- Urine Conditioning Buffer™
- Fecal Collection Tubes
- Blood Collection Tubes
- Swab Collection Kits
- Saliva Collection Kits
- Lysis Tubes
- Mouth, Nose, and Throat
- Environmental
- Soil & Sludge
Forgot Password
Reset Your Password
Harness the True Power of Your Sample
Extract Inhibitor-Free DNA & RNA from ANY Sample and Enjoy 30% Off and a Free Gift with Purchase.

DNA From Any Sample
Simple DNA extraction and clean-up to suit any downstream application.

RNA Purification for Any Application
Discover the world of RNA with kits designed to ensure that the isolated RNA is ready for all sensitive downstream applications.

DNA/RNA Co-Purification
Isolate high-quality DNA and RNA at the same time with all-in-one purification kits.

30 Years of Driving Discovery with Sample Preparation
Zymo Research's sample preparation products are specifically designed to meet the complexities of today’s challenging molecular-based techniques, including PCR, next-generation sequencing, microarrays, and gene editing. Our technologies effectively remove contaminants, ensuring purity without compromising DNA and RNA yield.
From resilient organisms to spin columns that capture and elute both large and small DNA and RNA molecules in the lowest volume, our extractions remain unbiased and efficient. Compatible with diverse sample collection methods, these products set the standard for high nucleic acid concentrations, free from contaminants like salts and proteins, exemplified by the Direct and ZymoPURE product lines.
At Zymo Research, innovation drives excellence, empowering breakthroughs with every purified sample.
Featured Technologies

Quick -RNA Miniprep Plus Kit
NGS-Ready RNA From Any Sample
Spin-column purification of ultra-pure total RNA (including small/microRNAs) from cells, tissues and biological fluids.

DNA Clean & Concentrator-5
Ultra-pure, Highly Concentrated DNA in 2 Minutes
Clean and concentrate up to 5 µg of DNA with ≥ 6 µl elution in as little as 2 minutes with 0 µl wash residue carryover.

ZymoPURE Plasmid Kits
Transfection-grade Plasmid DNA in ≤ 18 Minutes
Recover up to 3 mg of highly concentrated transfection grade plasmid from a spin column with simple 16-minute midi/maxi preps.

Direct-zol RNA Miniprep Kits
RNA from TRIzol® in 7 Minutes
Simply add sample in TRI Reagent® directly to the Zymo-Spin Column and bind, wash, and elute high quality RNA. No phase separation or post-purification steps are necessary.

Quick -DNA Miniprep Plus Kit
Rapidly extract ultra-pure total DNA from a variety of sample types
Purify up to 3x more total DNA from cultured cells, tissues, and biological fluids that is free of RNA in just 20 minutes using a simple spin-column protocol.

Quick -DNA/RNA HT
Purify DNA/RNA in <15 Minutes from any Sample
Clinical, high throughput, magnetic bead based purification of total nucleic acid (DNA/RNA) from any clinical sample.
30% OFF ALL Purification Kits + FREE Cozy Sweater
Headed back to the lab? Fall into 30% savings on all DNA and RNA purification kits with Promo Code: POWER30 and enjoy a seasonal limited-edition sweater with your order.

Knowledge Center

How to Choose a DNA and RNA Purification Kit
Explore advanced purification technologies for high-quality DNA and RNA that is suitable for various downstream applications and explore the features that distinguish each kit from similar options.

How to Extract RNA from Hard-to-lyse Samples in TRIzol
Learn how to streamline RNA extraction from TRIzol®, ensuring high yield and purity, even from challenging sample types like hard-to-lyse tissue.

Genomic DNA Extraction & Tips For Success
Purifying genomic DNA that is suitable for downstream analysis is not always a given. Here are some important tips and suggestions for ensuring the extraction of high-quality genomic DNA from a variety of sample types.

Crash Course: What is Plasmid DNA?
Learn about what plasmid DNA is, common features of plasmid DNA, how to work with plasmid DNA in the lab, and more.

Dos & Don'ts of Plasmid Purification
Looking for some tips for effective plasmid purification? This guide highlights some of the essential Dos and Don'ts of plasmid purification.

Tips & Tricks for RNA Isolation
Scientists Share Their Best Tips for How To Extract RNA

How to Extract RNA from TRIzol®
Must-Know Tips for RNA Extraction from TRIzol®
- choosing a selection results in a full page refresh
Need help? Contact Us
The Vital Role of Market Research in Building a Winning Business Strategy

When it comes to crafting a business strategy that truly works, guesswork isn’t an option. To succeed, you need to know your audience inside out and have a firm grasp of the competitive landscape. This is where market research steps in. Think of it as your strategic compass—guiding your decisions and ensuring they’re grounded in reality.
Let’s break down why market research is indispensable and how you can integrate it into your strategy to drive your business forward.
What is Market Research?
Market research goes far beyond simply gathering data. It’s about transforming raw numbers and opinions into actionable insights. These insights then inform the critical decisions that shape your business’s direction and growth.
By systematically collecting and analyzing information about your target market, competitors, and industry trends, market research empowers you to make decisions that are not just informed—but strategic. Emergen Research comprehensive research approach ensures that you stay ahead in a competitive landscape, equipped with the knowledge to drive sustainable growth.
Why Market Research Matters
Identifying new opportunities.
Market research is your key to unlocking untapped potential. By diving into the needs and desires of your target audience, you can discover gaps in the market. This knowledge allows you to create products or services that meet those needs—giving you a competitive edge.
Mitigating Risks
Venturing into new markets or launching a new product is always a risk, but market research helps you minimize that risk. By understanding the current market trends and customer behaviors, you can avoid costly mistakes and make more confident decisions.
Staying Ahead of the Competition
In the fast-paced world of business, standing still is the same as falling behind. Regularly conducting market research keeps you informed about what your competitors are up to, enabling you to innovate and stay ahead of the curve.
The Two Pillars of Market Research: Quantitative and Qualitative
Market research generally falls into two categories: Quantitative and Qualitative. Each type offers unique insights and, when used together, provides a comprehensive view of your market.
Quantitative Research
Quantitative research is all about numbers—data you can measure and analyze statistically. It’s ideal for getting a clear picture of market size, customer demographics, and other measurable factors that influence your business.
Key Characteristics:
Employs structured tools like surveys and questionnaires
Produces numerical data that can be statistically analyzed
Useful for identifying trends and patterns
Surveys to gauge customer satisfaction
Polls to assess product popularity
Qualitative Research
If quantitative research is the "what," qualitative research is the "why." It seeks to understand the motivations and emotions behind consumer behavior. Through open-ended questions and discussions, qualitative research provides deeper insights that numbers alone can’t offer.
Utilizes unstructured or semi-structured techniques such as interviews and focus groups
Delivers insights into customer attitudes, beliefs, and motivations
Typically involves smaller, more targeted sample sizes
Focus groups discussing how a brand is perceived
In-depth interviews exploring why customers prefer one product over another
The Role of Market Research in Business Strategy Development
Market research plays a pivotal role in the formulation of business strategies. Here's how it contributes:
Identifying Demand and Market Viability
Before launching a product or service, it's crucial to assess its viability. Market research helps determine whether there is sufficient demand for your offering.
Steps to Determine Viability:
Identify Market Needs: Understand what the market currently lacks.
Assess Competition: Evaluate how your competitors are fulfilling these needs.
Test Market Demand: Conduct surveys to gauge potential customer interest, especially in niche areas like loans online , where understanding market demand is crucial before launching a new product or service.
Example: A startup looking to introduce eco-friendly packaging must first understand if the target market values sustainability enough to pay a premium price for such products.
Reducing Risks and Enhancing Profitability
Knowledge gained from market research can significantly cut down risks by predictive analysis. Understanding past and future trends helps businesses align their strategies to meet market needs.
Key Points:
Risk Mitigation: Evaluate market conditions and customer behavior to avoid potential pitfalls.
Increased Profitability: Focus resources on strategies with the highest potential for return on investment.
Example: A company considering an expansive marketing campaign can first test various advertising channels and messages to see which resonate most with their target audience.
Understanding and Retaining Customers
Customers' needs and preferences change over time. Constantly monitoring these changes through market research ensures that businesses stay relevant and improve customer satisfaction.
Customer Insights: Understand behavior and satisfaction levels.
Retention Strategies: Develop strategies to retain customers by addressing their evolving needs.
Example: An e-commerce platform might use feedback surveys and purchase data analysis to identify pain points in the user experience and improve it accordingly.
How to Plan Effective Market Research
Planning is the backbone of effective market research. Here’s a structured approach to get the best results:
Set Clear Objectives
Understand what you want to achieve with your research. Is it to understand market trends, customer behavior, or competitor analysis?
Components of a Good Plan:
Define Goals: What do you aim to find out?
Select Techniques: Choose between qualitative and quantitative methods based on your goals.
Design Survey: Formulate questions that will provide meaningful data.
Choose the Right Tools
Invest in robust market research tools. These types of platforms offer comprehensive survey creation, distribution, and analysis features that streamline the research process.
Key Tool Features:
Survey Builder: Customize and create surveys easily.
Data Collection: Gather data through various channels like email, web pop-ups, and mobile devices.
Real-time Reporting: Analyze data as it comes in for timely insights.
Integration: Connect with CRM and other marketing tools for comprehensive insights.
Example: When gathering data for a new product launch, use a combination of online surveys and focus groups to get a well-rounded understanding of market demand.
Analyze and Implement Findings
Effective analysis transforms raw data into actionable insights. Use statistical tools and qualitative analysis techniques to understand your data clearly.
Data Analysis: Employ cross-tabulation, descriptive and inferential statistics.
Derive Insights: Identify key trends and patterns.
Action Plan: Develop strategies based on insights.
Example: A retail chain could use sales trend analysis to determine which products to stock more during festive seasons.
In today's fast-paced business environment, market research is not optional; it's essential. It’s the linchpin that ties together market viability, competitive analysis, and customer understanding into a coherent business strategy. By implementing well-planned and executed market research, businesses can set realistic goals, minimize risks, and maximize profitability.
Please support us by following us on LinkedIn - https://www.linkedin.com/company/emergen-research
Read Comprehensive Report
Latest blogs.
Looking for Customization?
Have a Question?
Any Confusion?
Have a glance of the Report
How can we help you?
Please contact for a detailed synopsis of the report
Research Report
- Chemical and Advance Materials 491
- Healthcare and Pharmaceuticals 994
- Power and Energy 47
- Foods & Beverage 91
- Automotive 142
- Information and Communication Technology 441
- Manufacturing and Construction 39
- Semiconductors & Electronics 211
- Consumer Goods 60
- Aerospace and Defense 155
- Industrial Equipment and Machinery 70
- Agriculture 43
- Packaging 23
- Transportation 15
- Environment 24
- Banking and Finance 35
- Logistics and Supply Chain 12
Service Guarantee

Order And Delivery
This report has a service guarantee. We stand by our report qualityDelivery within 48 hours of receiving the payment.

Privacy Policy
Our website adheres to the guidelines given under the General Data Protection Regulation (GDPR). This privacy policy aims to assure the safety of data for users visiting our website.

Transactions on this website are protected by up to 256-bit Secure Sockets Layer encryption.

Report Customization
We provide report customization options, wherein the buyer can structure the report according to their requirements.

24/7 Research Support
All queries are resolved from an industry expert.
Free Sample PDF Copy
Our Report will provide insights on Market size, Company Details and Total Addressable Market(TAM)
New Markets | New Geographies | Competition

Bhaskaran Publishes Research on Laryngeal Dystonia
Written by Staff
September 3, 2024
Divya Bhaskaran, Assistant Professor in the Exercise Science program of the Biology Department, published a research paper in the Frontiers in Neurology Journal. The article titled "Effects of an 11-week vibro-tactile stimulation treatment on voice symptoms in laryngeal dystonia" is a longitudinal clinical trial conducted during Dr Bhaskaran's post-doctoral work at the University of Minnesota.
1536 Hewitt Ave
Saint Paul, MN 55104
General Information
Undergraduate Admission
Public Safety Office
Graduate Admission
ITS Central Service Desk
© 2024 Hamline University
In association with Mitchell | Hamline School of Law ®. Mitchell Hamline School of Law ® has more graduate enrollment options than any other law school in the nation.
- On-Campus Transfer
- Online Degree Completion
- International
- Admitted Students
- How to Apply
- Grants & Scholarships
- First-Year and Transfer Aid
- Online Degree Completion Aid
- Graduate Aid
- International Aid
- Military & Veteran Aid
- Undergraduate Tuition
- Online Degree Completion Tuition
- Graduate Tuition
- Housing & Food Costs
- Net Price Calculator
- Payment Info
- Undergraduate
- Continuing Education
- Program Finder
- Faculty by Program
- College of Liberal Arts
- School of Business
- School of Education & Leadership
- Mitchell Hamline School of Law
- Academic Bulletin
- Academic Calendars
- Bush Library
- Registration & Records
- Study Away & Study Abroad
- Housing & Dining
- Counseling & Health
- Service, Spiritual Life, & Recreation
- Activities & Organizations
- Diversity Resources
- Arts at Hamline
- Meet Our Students
- The Neighborhood
- The Hamline Academic Experience
- Student Research Opportunities
- Paid Internships
- Career Development Center
- Alumni Success Stories
- Center for Academic Success & Achievement
- Writing Center
- Why Hamline?
- Mission & History
- Fast Facts and Rankings
- University Leadership
- Diversity, Equity & Inclusion
- Alumni and Donors
- Request Info
Information
- Author Services
Initiatives
You are accessing a machine-readable page. In order to be human-readable, please install an RSS reader.
All articles published by MDPI are made immediately available worldwide under an open access license. No special permission is required to reuse all or part of the article published by MDPI, including figures and tables. For articles published under an open access Creative Common CC BY license, any part of the article may be reused without permission provided that the original article is clearly cited. For more information, please refer to https://www.mdpi.com/openaccess .
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world. Editors select a small number of articles recently published in the journal that they believe will be particularly interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the most exciting work published in the various research areas of the journal.
Original Submission Date Received: .
- Active Journals
- Find a Journal
- Proceedings Series
- For Authors
- For Reviewers
- For Editors
- For Librarians
- For Publishers
- For Societies
- For Conference Organizers
- Open Access Policy
- Institutional Open Access Program
- Special Issues Guidelines
- Editorial Process
- Research and Publication Ethics
- Article Processing Charges
- Testimonials
- Preprints.org
- SciProfiles
- Encyclopedia
Article Menu

- Subscribe SciFeed
- Recommended Articles
- Google Scholar
- on Google Scholar
- Table of Contents
Find support for a specific problem in the support section of our website.
Please let us know what you think of our products and services.
Visit our dedicated information section to learn more about MDPI.
JSmol Viewer
Assessing the fatigue stress behavior of starch biodegradable films with nanoclay using accelerated survival test methods.

1. Introduction
2. materials and methods, 2.1. materials, 2.2. film preparation, 2.3. thickness, 2.4. tensile properties, 2.5. experimental design, 3. results and discussion, 4. conclusions, author contributions, institutional review board statement, informed consent statement, data availability statement, conflicts of interest.
- Mujtaba, M.; Lipponen, J.; Ojanen, M.; Puttonen, S.; Vaittinen, H. Trends and challenges in the development of bio-based barrier coating materials for paper/cardboard food packaging; a review. Sci. Total Environ. 2022 , 851 , 158328. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Cruz, R.M.S.; Albertos, I.; Romero, J.; Agriopoulou, S.; Varzakas, T. Chapter Four—Innovations in Food Packaging for a Sustainable and Circular Economy. In Advances in Food and Nutrition Research ; Toldrá, F., Ed.; Academic Press: Cambridge, MA, USA, 2024; Volume 108, pp. 135–177. [ Google Scholar ]
- Barage, S.; Lakkakula, J.; Sharma, A.; Roy, A.; Alghamdi, S.; Almehmadi, M.; Hossain, M.J. Nanomaterial in Food Packaging: A Comprehensive Review. J. Nanomater. 2022 , 2022 , 6053922. [ Google Scholar ] [ CrossRef ]
- Gamage, A.; Thiviya, P.; Mani, S.; Ponnusamy, P.G.; Manamperi, A.; Evon, P.; Merah, O.; Madhujith, T. Environmental Properties and Applications of Biodegradable Starch-Based Nanocomposites. Polymers 2022 , 14 , 4578. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- El-Tahlawy, K.; Venditti, R.; Pawlak, J. Effect of alkyl ketene dimer reacted starch on the properties of starch microcellular foam using a solvent exchange technique. Carbohydr. Polym. 2008 , 73 , 133–142. [ Google Scholar ] [ CrossRef ]
- Ballesteros-Mártinez, L.; Pérez-Cervera, C.; Andrade-Pizarro, R. Effect of glycerol and sorbitol concentrations on mechanical, optical, and barrier properties of sweet potato starch film. NFS J. 2020 , 20 , 1–9. [ Google Scholar ] [ CrossRef ]
- Kechichian, V.; Ditchfield, C.; Veiga-Santos, P.; Tadini, C.C. Natural antimicrobial ingredients incorporated in biodegradable films based on cassava starch. LWT—Food Sci. Technol. 2010 , 43 , 1088–1094. [ Google Scholar ] [ CrossRef ]
- Souza, A.C.; Benze, R.; Ferrão, E.S.; Ditchfield, C.; Coelho, A.C.V.; Tadini, C.C. Cassava starch biodegradable films: Influence of glycerol and clay nanoparticles content on tensile and barrier properties and glass transition temperature. LWT 2012 , 46 , 110–117. [ Google Scholar ] [ CrossRef ]
- Wang, S.; Li, C.; Copeland, L.; Niu, Q.; Wang, S. Starch Retrogradation: A Comprehensive Review. Compr. Rev. 2015 , 14 , 568–585. [ Google Scholar ] [ CrossRef ]
- Bertuzzi, M.A.; Vidaurre, E.F.C.; Armada, M.; Gottifredi, J.C. Water vapor permeability of edible starch based films. J. Food Eng. 2007 , 80 , 972–978. [ Google Scholar ] [ CrossRef ]
- Zhou, X.Y.; Zhou, L.L.; Jia, M.; Xiong, Y. Nanofillers in Novel Food Packaging Systems and Their Toxicity Issues. Foods 2024 , 13 , 2014. [ Google Scholar ] [ CrossRef ]
- Kausar, A. Nanoclay Reinforced Thermoplastic Polymeric Nanocomposite Membranes-State-of-the-Art and Progresses. Polym.-Plast. Technol. Mater. 2024 , 63 , 1819–1841. [ Google Scholar ] [ CrossRef ]
- Dharini, V.; Selvam, S.P.; Jayaramudu, J.; Emmanuel, R.S. Functional properties of clay nanofillers used in the biopolymer-based composite films for active food packaging applications—Review. Appl. Clay Sci. 2022 , 226 , 106555. [ Google Scholar ] [ CrossRef ]
- Ray, S.S.; Okamoto, M. Polymer/layered silicate nanocomposites: A review from preparation to processing. Prog. Polym. Sci. 2003 , 28 , 1539–1641. [ Google Scholar ] [ CrossRef ]
- Mohan, T.; Devchand, K.; Kanny, K. Barrier and biodegradable properties of corn starch-derived biopolymer film filled with nanoclay fillers. J. Plast. Film Sheeting 2017 , 33 , 309–336. [ Google Scholar ] [ CrossRef ]
- Sim, G.-D.; Lee, Y.-S.; Lee, S.-B.; Vlassak, J.J. Effects of stretching and cycling on the fatigue behavior of polymer-supported Ag thin films. Mater. Sci. Eng. A 2013 , 575 , 86–93. [ Google Scholar ] [ CrossRef ]
- Tobias, T.D.; Paul, A. Applied Reliability , 3rd ed.; CRC Press: New York, NY, USA, 2011. [ Google Scholar ]
- Yu, K.J.; Yang, L.N.; Zhang, S.Y.; Zhang, N. Strong, tough, high-release, and antibacterial nanocellulose hydrogel for refrigerated chicken preservation. Int. J. Biol. Macromol. 2024 , 264 , 130727. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Leterrier, Y.; Mottet, A.; Bouquet, N.; Gilliéron, D.; Dumont, P.; Pinyol, A.; Lalande, L.; Waller, J.H.; Månson, J.A. Mechanical integrity of thin inorganic coatings on polymer substrates under quasi-static, thermal and fatigue loadings. Thin Solid Film. 2010 , 519 , 1729–1737. [ Google Scholar ] [ CrossRef ]
- Kim, T.W.; Kim, J.M.; Yun, H.J.; Lee, J.S.; Lee, J.H.; Song, J.Y.; Joo, Y.C.; Lee, W.J.; Kim, B.J. Electrical Reliability of Flexible Silicon Package Integrated on Polymer Substrate During Repeated Bending Deformations. J. Electron. Packag. 2022 , 144 , 041017. [ Google Scholar ] [ CrossRef ]
- Chang, C.C.; Lin, S.D.; Chiang, K.N. Development of a High Cycle Fatigue Life Prediction Model for Thin Film Silicon Structures. J. Electron. Packag. 2018 , 140 , 031008. [ Google Scholar ] [ CrossRef ]
- Chang, Y.C.; Chiu, T.C.; Yang, Y.T.; Tseng, Y.H.; Chen, X.H. A Viscoplastic-Based Fatigue Reliability Model for the Polyimide Dielectric Thin Film. In Proceedings of the 69th IEEE Electronic Components and Technology Conference (ECTC), Las Vegas, NV, USA, 29–31 May 2019; pp. 1359–1365. [ Google Scholar ] [ CrossRef ]
- Tian, W.C.; Li, W.B.; Zhang, S.Q.; Zhou, L.M.; Wang, H. Temperature Cycle Reliability Analysis of an FBAR Filter-Bonded Ceramic Package. Micromachines 2023 , 14 , 2132. [ Google Scholar ] [ CrossRef ]
- Watanabe, K.; Kariya, Y.; Yajima, N.; Obinata, K. Low-cycle fatigue testing and thermal fatigue life prediction of electroplated copper thin film for through hole via. Microelectron. Reliab. 2018 , 82 , 20–27. [ Google Scholar ] [ CrossRef ]
- Frangopoulos, T.; Marinopoulou, A.; Goulas, A.; Likotrafiti, E.; Rhoades, J.; Petridis, D. Optimizing the Functional Properties of Starch-Based Biodegradable Films. Foods 2023 , 12 , 2812. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Hoover, R.; Sosulski, F.W. Composition, structure, functionality, and chemical modification of legume starches—A review. Can. J. Physiol. Pharmacol. 1991 , 69 , 79–92. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Hoover, R.; Ratnayake, W.S. Starch characteristics of black bean, chick pea, lentil, navy bean and pinto bean cultivars grown in Canada. Food Chem. 2002 , 78 , 489–498. [ Google Scholar ] [ CrossRef ]
- ASTM D882-10 ; Standard Test Method for Tensile Properties of Thin Plastic Sheeting. ASTM Internationa: West Conshohocken, PA, USA, 2010.
- Zhang, Y.; Chen, J.H.; Sun, G.; Huang, H.; Tong, L.; Wang, M.J.; Li, H.; He, X.; He, X. Strain rate-dependent hardness and deformation behavior in the nanocrystalline/amorphous Ti2AlNb film. Surf. Coat. Int. 2021 , 412 , 127040. [ Google Scholar ] [ CrossRef ]
- Mensitieri, G.; Di Maio, E.; Buonocore, G.G.; Nedi, I.; Oliviero, M.; Sansone, L.; Iannace, S. Processing and shelf life issues of selected food packaging materials and structures from renewable resources. Trends Food. Sci. Technol. 2011 , 22 , 72–80. [ Google Scholar ] [ CrossRef ]
- Mejri, M.; Toubal, L.; Cuillière, J.-C.; François, V. Fatigue life and residual strength of a short- natural-fiber-reinforced plastic VS Nylon. Compos. Part B Eng. 2016 , 110 , 429–441. [ Google Scholar ] [ CrossRef ]
- Pineau, A. Low-Cycle Fatigue. In Fatigue of Materials and Structures ; Wiely: Hoboken, NJ, USA, 2013; pp. 113–177. [ Google Scholar ]
- Müller, P.; Kapin, É.; Fekete, E. Effects of preparation methods on the structure and mechanical properties of wet conditioned starch/montmorillonite nanocomposite films. Carbohydr. Polym. 2014 , 113 , 569–576. [ Google Scholar ] [ CrossRef ]
- Mansour, G.; Zoumaki, M.; Marinopoulou, A.; Tzetzis, D.; Prevezanos, M.; Raphaelides, S.N. Characterization and properties of non-granular thermoplastic starch—Clay biocomposite films. Carbohydr. Polym. 2020 , 245 , 116629. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Yashiro, K.; Naito, M.; Ueno, S.-I.; Jie, F. Molecular dynamics simulation of polyethylene under cyclic loading: Effect of loading condition and chain length. Int. J. Mech. Sci. 2010 , 52 , 136–145. [ Google Scholar ] [ CrossRef ]
- Guru, S.R.; Sarangi, M. Multicycle indentation based fatigue and creep study of polymers. J. Polym. Res. 2023 , 30 , 401. [ Google Scholar ] [ CrossRef ]
- Mansour, G.; Zoumaki, M.; Marinopoulou, A.; Raphaelides, S.N.; Tzetzis, D.; Zoumakis, N. Investigation on the Effects of Glycerol and Clay Contents on the Structure and Mechanical Properties of Maize Starch Nanocomposite Films. Starch-Stärke 2020 , 72 , 1900166. [ Google Scholar ] [ CrossRef ]
- Borges, J.A.; Romani, V.P.; Cortez-Vega, W.R.; Martins, V.G. Influence of different starch sources and plasticizers on properties of biodegradable films. Int. Food Res. J. 2015 , 22 , 2346–2351. [ Google Scholar ]
- Marques, G.S.; de Carvalho, G.R.; Marinho, N.P.; de Muniz, G.I.B.; de Matos Jorge, L.M.; Jorge, R.M.M. Production and characterization of starch-based films reinforced by ramie nanofibers ( Boehmeria nivea ). Appl. Polym. Sci. 2019 , 136 , 47919. [ Google Scholar ] [ CrossRef ]
- Korycki, A.; Garnier, C.; Irusta, S.; Chabert, F. Evaluation of Fatigue Life of Recycled Opaque PET from Household Milk Bottle Wastes. Polymers 2022 , 14 , 3466. [ Google Scholar ] [ CrossRef ]
- Schijve, J. Fatigue of structures and materials in the 20th century and the state of the art. Int. J. Fatigue 2003 , 25 , 679–702. [ Google Scholar ] [ CrossRef ]
- Li, X.; Qu, P.; Kong, H.; Zhu, Y.; Hua, C.; Guo, A.; Wang, S. Multi-scale numerical analysis of damage modes in 3D stitched composites. Int. J. Mech. Sci. 2024 , 266 , 108983. [ Google Scholar ] [ CrossRef ]
Click here to enlarge figure
| Sample ID | Starch Concentration (%wt) | Glycerol Concentration (%wt) * | Nanoclay Concentration (%wt) * |
|---|---|---|---|
| 7_50_1 | 7 | 50 | 1 |
| 4_50_1 | 4 | 50 | 1 |
| 7_35_1 | 7 | 35 | 1 |
| 7_50_10.5 | 7 | 50 | 10.5 |
| 7_35_10.5 | 7 | 35 | 10.5 |
| Elongation Level (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Stretch Cycle | Stress Time (min) | 5 | 8 | 12 | 14 | 15 | 16 | 18 | 20 | 23 | 25 | 45 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 7 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 10 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 13 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 16 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 19 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 22 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 7 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 10 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 13 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 16 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 19 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 22 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 6 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 7 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 10 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 13 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 16 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 19 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 22 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| Sample ID | Mean Thickness (Range) (mm) |
|---|---|
| 7_50_1 | 0.21 (0.19–0.22) |
| 4_50_1 | 0.11 (0.09–0.12) |
| 7_35_1 | 0.20 (0.19–0.21) |
| 7_50_10.5 | 0.23 (0.22–0.25) |
| 7_35_10.5 | 0.23 (0.22–0.24) |
| Sample ID | LSM | Lower 95% | Upper 95% | ||||
|---|---|---|---|---|---|---|---|
| 7_35_10.5 | A | 1.77 | 1.71 | 1.83 | |||
| 7_35_1 | B | 1.62 | 1.54 | 1.69 | |||
| 7_50_1 | C | 1.44 | 1.35 | 1.53 | |||
| 7_50_10.5 | D | 1.24 | 1.16 | 1.32 | |||
| 4_50_1 | D | 1.10 | 1.00 | 1.19 |
| Log [Exact Break Time] | Break Cycle | log[ts/bc] | log[ts/bc] Lower CI | log[ts/bc] Upper CI |
|---|---|---|---|---|
| 4.73 | 1 | 7.11 | 6.63 | 7.63 |
| 4.73 | 2 | 5.27 | 4.95 | 5.62 |
| 4.73 | 3 | 3.91 | 3.60 | 4.25 |
| 4.73 | 4 | 2.90 | 2.58 | 3.26 |
| 4.73 | 5 | 2.15 | 1.83 | 2.52 |
| 4.73 | 6 | 1.59 | 1.30 | 1.95 |
| The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Share and Cite
Frangopoulos, T.; Dimitriadou, S.; Ozuni, J.; Marinopoulou, A.; Goulas, A.; Petridis, D.; Karageorgiou, V. Assessing the Fatigue Stress Behavior of Starch Biodegradable Films with Nanoclay Using Accelerated Survival Test Methods. Appl. Sci. 2024 , 14 , 7728. https://doi.org/10.3390/app14177728
Frangopoulos T, Dimitriadou S, Ozuni J, Marinopoulou A, Goulas A, Petridis D, Karageorgiou V. Assessing the Fatigue Stress Behavior of Starch Biodegradable Films with Nanoclay Using Accelerated Survival Test Methods. Applied Sciences . 2024; 14(17):7728. https://doi.org/10.3390/app14177728
Frangopoulos, Theofilos, Sophia Dimitriadou, Joanis Ozuni, Anna Marinopoulou, Athanasios Goulas, Dimitrios Petridis, and Vassilis Karageorgiou. 2024. "Assessing the Fatigue Stress Behavior of Starch Biodegradable Films with Nanoclay Using Accelerated Survival Test Methods" Applied Sciences 14, no. 17: 7728. https://doi.org/10.3390/app14177728
Article Metrics
Article access statistics, further information, mdpi initiatives, follow mdpi.
Subscribe to receive issue release notifications and newsletters from MDPI journals
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Starting the research process
- 10 Research Question Examples to Guide Your Research Project
10 Research Question Examples to Guide your Research Project
Published on October 30, 2022 by Shona McCombes . Revised on October 19, 2023.
The research question is one of the most important parts of your research paper , thesis or dissertation . It’s important to spend some time assessing and refining your question before you get started.
The exact form of your question will depend on a few things, such as the length of your project, the type of research you’re conducting, the topic , and the research problem . However, all research questions should be focused, specific, and relevant to a timely social or scholarly issue.
Once you’ve read our guide on how to write a research question , you can use these examples to craft your own.
| Research question | Explanation |
|---|---|
| The first question is not enough. The second question is more , using . | |
| Starting with “why” often means that your question is not enough: there are too many possible answers. By targeting just one aspect of the problem, the second question offers a clear path for research. | |
| The first question is too broad and subjective: there’s no clear criteria for what counts as “better.” The second question is much more . It uses clearly defined terms and narrows its focus to a specific population. | |
| It is generally not for academic research to answer broad normative questions. The second question is more specific, aiming to gain an understanding of possible solutions in order to make informed recommendations. | |
| The first question is too simple: it can be answered with a simple yes or no. The second question is , requiring in-depth investigation and the development of an original argument. | |
| The first question is too broad and not very . The second question identifies an underexplored aspect of the topic that requires investigation of various to answer. | |
| The first question is not enough: it tries to address two different (the quality of sexual health services and LGBT support services). Even though the two issues are related, it’s not clear how the research will bring them together. The second integrates the two problems into one focused, specific question. | |
| The first question is too simple, asking for a straightforward fact that can be easily found online. The second is a more question that requires and detailed discussion to answer. | |
| ? dealt with the theme of racism through casting, staging, and allusion to contemporary events? | The first question is not — it would be very difficult to contribute anything new. The second question takes a specific angle to make an original argument, and has more relevance to current social concerns and debates. |
| The first question asks for a ready-made solution, and is not . The second question is a clearer comparative question, but note that it may not be practically . For a smaller research project or thesis, it could be narrowed down further to focus on the effectiveness of drunk driving laws in just one or two countries. |
Note that the design of your research question can depend on what method you are pursuing. Here are a few options for qualitative, quantitative, and statistical research questions.
| Type of research | Example question |
|---|---|
| Qualitative research question | |
| Quantitative research question | |
| Statistical research question |
Other interesting articles
If you want to know more about the research process , methodology , research bias , or statistics , make sure to check out some of our other articles with explanations and examples.
Methodology
- Sampling methods
- Simple random sampling
- Stratified sampling
- Cluster sampling
- Likert scales
- Reproducibility
Statistics
- Null hypothesis
- Statistical power
- Probability distribution
- Effect size
- Poisson distribution
Research bias
- Optimism bias
- Cognitive bias
- Implicit bias
- Hawthorne effect
- Anchoring bias
- Explicit bias
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2023, October 19). 10 Research Question Examples to Guide your Research Project. Scribbr. Retrieved September 3, 2024, from https://www.scribbr.com/research-process/research-question-examples/
Is this article helpful?
Shona McCombes
Other students also liked, writing strong research questions | criteria & examples, how to choose a dissertation topic | 8 steps to follow, evaluating sources | methods & examples, "i thought ai proofreading was useless but..".
I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes”
IMAGES
VIDEO
COMMENTS
The sample is the group of individuals who will actually participate in the research. To draw valid conclusions from your results, you have to carefully decide how you will select a sample that is representative of the group as a whole. This is called a sampling method. There are two primary types of sampling methods that you can use in your ...
What is a Sample? A sample is a smaller set of data that a researcher chooses or selects from a larger population using a pre-defined selection bias method. These elements are known as sample points, sampling units, or observations. Creating a sample is an efficient method of conducting research. Researching the whole population is often ...
The sample is a subset of the population's elements chosen for research, whereas the sample frame is a comprehensive list or inventory of all population items. Key points to takeaway In conclusion, a sample is a group or subset of persons or things chosen from a broader population to study or assess particular traits or behaviors.
A sample is a subset of individuals from a larger population. Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
In probability theory, the sample space comprises all possible outcomes of a random experiment, while the sample frame is the list or source guiding sample selection in statistical research. The sample represents the group of individuals participating in the study, forming the basis for the research findings. Selecting the correct sample is ...
Sampling in qualitative research has different purposes and goals than sampling in quantitative research. Sampling in both allows you to say something of interest about a population without having to include the entire population in your sample. We begin this chapter with the case of a population of interest composed of actual people.
Sampling methods in psychology refer to strategies used to select a subset of individuals (a sample) from a larger population, to study and draw inferences about the entire population. Common methods include random sampling, stratified sampling, cluster sampling, and convenience sampling. Proper sampling ensures representative, generalizable, and valid research results.
The sample should be selected randomly, or if using a non-random method, every effort should be made to minimize bias and ensure that the sample is representative of the population. Collect data: Once the sample has been selected, collect data from each member of the sample using appropriate research methods (e.g., surveys, interviews ...
Sampling refers to the process of defining a subgroup (sample) from the larger group of interest (population). The two overarching approaches to sampling are probability sampling (random) and non-probability sampling. Common probability-based sampling methods include simple random sampling, stratified random sampling, cluster sampling and ...
Sampling is a critical element of research design. Different methods can be used for sample selection to ensure that members of the study population reflect both the source and target populations, including probability and non-probability sampling. Power and sample size are used to determine the number of subjects needed to answer the research ...
The research implied Dewey would win, but it was Truman who became president. Poor data collection or recording. This problem speaks for itself. The survey may be well structured, the sample groups appropriate, the questions clear and easy to understand, and the cluster sizes appropriate.
Research objectiveness. Firstly, a refined research question and goal would help us define our population of interest. If our calculated sample size is small then it would be easier to get a random sample. If, however, the sample size is large, then we should check if our budget and resources can handle a random sampling method.
The main purpose of sampling in research is to make the research process doable. The research sample helps to reduce bias, accurately present the population and is cost-effective.
Sampling is the statistical process of selecting a subset—called a 'sample'—of a population of interest for the purpose of making observations and statistical inferences about that population. Social science research is generally about inferring patterns of behaviours within specific populations. We cannot study entire populations because of feasibility and cost constraints, and hence ...
Research benefits greatly from sampling. It is one of the most crucial elements that affect how accurate your study or survey results are. If your sample contains any errors, the outcome will be affected accordingly. Depending on the situation and necessity, numerous methodologies aid in sample collection.
In statistics, a sample is a subset of a population that is used to represent the entire group as a whole. When doing psychology research, it is often impractical to survey every member of a particular population because the number of people is simply too large. To make inferences about the characteristics of a population, psychology researchers use a random sample.
Sampling (Selecting Subjects)... The main purpose of survey research is to describe the characteristics of a population. This is usually accomplished by collecting data from a sample. Therefore, the first step in sampling is to define the population. POPULATION-> The population is the group consisting of all people to whom we (as researchers ...
So there was no uniform answer to the question and the ranges varied according to methodology. In fact, Shaw and Holland (2014) claim, sample size will largely depend on the method. (p. 87), "In truth," they write, "many decisions about sample size are made on the basis of resources, purpose of the research" among other factors. (p. 87).
A sample is the specific group that you will collect data from. The size of the sample is always less than the total size of the population. In research, a population doesn't always refer to people. It can mean a group containing elements of anything you want to study, such as objects, events, organizations, countries, species, organisms, etc
A sample is a subset of individuals from a larger population. Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
Definition. In quantitative research methodology, the sample is a set of collected data from a defined procedure. It is basically a much smaller part of the whole, i.e., population. The sample depicts all the members of the population that are under observation when conducting research surveys.
Unlike quantitative research, we are hoping to get a representative sample, in a representative sample that can then data be generalized back to the population. That is the less the case in qualitative research. Since your sample size is so small in qualitative research, usually 8 to 14 participants.
This covers the majority of statistical analysis done for research papers, political polls, clinical trials, market research, quality assurance sampling, and more. You gain significant efficiency without sacrificing too much precision. The key is to sample thoughtfully! Sampling Bias. While sampling saves time and effort, it introduces the risk ...
30 Years of Driving Discovery with Sample Preparation. Zymo Research's sample preparation products are specifically designed to meet the complexities of today's challenging molecular-based techniques, including PCR, next-generation sequencing, microarrays, and gene editing. Our technologies effectively remove contaminants, ensuring purity ...
Typically involves smaller, more targeted sample sizes. Examples: Focus groups discussing how a brand is perceived; In-depth interviews exploring why customers prefer one product over another; The Role of Market Research in Business Strategy Development . Market research plays a pivotal role in the formulation of business strategies.
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about: Your overall research objectives and approach. Whether you'll rely on primary research or secondary research. Your sampling methods or criteria for selecting subjects. Your data collection methods.
Divya Bhaskaran, Assistant Professor in the Exercise Science program of the Biology Department, published a research paper in the Frontiers in Neurology Journal. The article titled "Effects of an 11-week vibro-tactile stimulation treatment on voice symptoms in laryngeal dystonia" is a longitudinal clinical trial conducted during Dr Bhaskaran's post-doctoral work at the University of Minnesota.
Searches were conducted via multiple, relevant databases. Studies investigating loneliness across marital statuses were considered if they included an adult, bereaved sample, were written in English, and used quantitative research methods. Thirty-eight studies met inclusion criteria. Widowhood was associated with a greater likelihood of loneliness.
A sample of 120 experimental film units for each treatment (see sample ID in Table 1) was subjected to 11 consecutive elongation levels starting from 5% (which was considered as the reference use) to 45% for 1, 3 or 6 stretch cycles that lasted from 1 to 22 min . The log tensile quotient (logarithm of the tensile strength to the corresponding ...
The first question asks for a ready-made solution, and is not focused or researchable. The second question is a clearer comparative question, but note that it may not be practically feasible. For a smaller research project or thesis, it could be narrowed down further to focus on the effectiveness of drunk driving laws in just one or two countries.