{{ activeMenu.name }}
- Python Courses
- JavaScript Courses
- Artificial Intelligence Courses
- Data Science Courses
- React Courses
- Ethical Hacking Courses
- View All Courses

Fresh Articles

- Python Projects
- JavaScript Projects
- Java Projects
- HTML Projects
- C++ Projects
- PHP Projects
- View All Projects

- Python Certifications
- JavaScript Certifications
- Linux Certifications
- Data Science Certifications
- Data Analytics Certifications
- Cybersecurity Certifications
- View All Certifications

- IDEs & Editors
- Web Development
- Frameworks & Libraries
- View All Programming
- View All Development
- App Development
- Game Development
- Courses, Books, & Certifications
- Data Science
- Data Analytics
- Artificial Intelligence (AI)
- Machine Learning (ML)
- View All Data, Analysis, & AI

- Networking & Security
- Cloud, DevOps, & Systems
- Recommendations
- Crypto, Web3, & Blockchain
- User-Submitted Tutorials
- View All Blog Content

- JavaScript Online Compiler
- HTML & CSS Online Compiler
- Certifications
- Programming
- Development
- Data, Analysis, & AI
- Online JavaScript Compiler
- Online HTML Compiler
Don't have an account? Sign up
Forgot your password?
Already have an account? Login
Have you read our submission guidelines?
Go back to Sign In
Normalization in DBMS: 1NF, 2NF, 3NF, and BCNF [Examples]
When developing the schema of a relational database, one of the most important aspects to be taken into account is to ensure that the duplication of data is minimized. We do this by carrying out database normalization, an important part of the database schema design process.
Here, we explain normalization in DBMS, explaining 1NF, 2NF, 3NF, and BCNF with explanations. First, let’s take a look at what normalization is and why it is important.
- What is Normalization in DBMS?
Database normalization is a technique that helps design the schema of the database in an optimal way. The core idea of database normalization is to divide the tables into smaller subtables and store pointers to data rather than replicating it.
Why Do We Carry out Database Normalization?

There are two primary reasons why database normalization is used. First, it helps reduce the amount of storage needed to store the data. Second, it prevents data conflicts that may creep in because of the existence of multiple copies of the same data.
If a database isn’t normalized, then it can result in less efficient and generally slower systems, and potentially even inaccurate data. It may also lead to excessive disk I/O usage and bad performance.
- What is a Key?
You should also be aware of what a key is. A key is an attribute that helps identify a row in a table. There are seven different types, which you’ll see used in the explanation of the various normalizations:
- Candidate Key
- Primary Key
- Foreign Key
- Alternate Key
- Composite Key
- Database Normalization Example
To understand (DBMS)normalization with example tables, let's assume that we are storing the details of courses and instructors in a university. Here is what a sample database could look like:
|
|
|
|
|
| CS101 | Lecture Hall 20 | Prof. George | +1 6514821924 |
| CS152 | Lecture Hall 21 | Prof. Atkins | +1 6519272918 |
| CS154 | CS Auditorium | Prof. George | +1 6514821924 |
Here, the data basically stores the course code, course venue, instructor name, and instructor’s phone number. At first, this design seems to be good. However, issues start to develop once we need to modify information. For instance, suppose, if Prof. George changed his mobile number. In such a situation, we will have to make edits in 2 places.
What if someone just edited the mobile number against CS101, but forgot to edit it for CS154? This will lead to stale/wrong information in the database. This problem can be easily tackled by dividing our table into 2 simpler tables:
Table 1 (Instructor):
- Instructor ID
- Instructor Name
- Instructor mobile number
Table 2 (Course):
- Course code
- Course venue
Now, our data will look like the following:
|
|
|
|
| 1 | Prof. George | +1 6514821924 |
| 2 | Prof. Atkins | +1 6519272918 |
|
|
|
|
| CS101 | Lecture Hall 20 | 1 |
| CS152 | Lecture Hall 21 | 2 |
| CS154 | CS Auditorium | 1 |
Basically, we store the instructors separately and in the course table, we do not store the entire data of the instructor. Rather, we store the ID of the instructor. Now, if someone wants to know the mobile number of the instructor, they can simply look up the instructor table. Also, if we were to change the mobile number of Prof. George, it can be done in exactly one place. This avoids the stale/wrong data problem.
Further, if you observe, the mobile number now need not be stored 2 times. We have stored it in just 1 place. This also saves storage. This may not be obvious in the above simple example. However, think about the case when there are hundreds of courses and instructors and for each instructor, we have to store not just the mobile number, but also other details like office address, email address, specialization, availability, etc. In such a situation, replicating so much data will increase the storage requirement unnecessarily.
Suggested Course
Database Management System (DBMS) & SQL : Complete Pack 2024
- Types of DBMS Normalization
There are various normal forms in DBMS. Each normal form has an importance that helps optimize the database to save storage and reduce redundancies. We explain normalization in DBMS with examples below.
First Normal Form (1NF)
The first normal form simply says that each cell of a table should contain exactly one value. Assume we are storing the courses that a particular instructor takes, we can store it like this:
|
|
|
| Prof. George | (CS101, CS154) |
| Prof. Atkins | (CS152) |
Here, the issue is that in the first row, we are storing 2 courses against Prof. George. This isn’t the optimal way since that’s now how SQL databases are designed to be used. A better method would be to store the courses separately. For instance:
|
|
|
| Prof. George | CS101 |
| Prof. George | CS154 |
| Prof. Atkins | CS152 |
This way, if we want to edit some information related to CS101, we do not have to touch the data corresponding to CS154. Also, observe that each row stores unique information. There is no repetition. This is the First Normal Form.
Data redundancy is higher in 1NF because there are multiple columns with the same in multiple rows. 1NF is not so focused on eliminating redundancy as much as it is focused on eliminating repeating groups.
Second Normal Form (2NF)
For a table to be in second normal form, the following 2 conditions must be met:
- The table should be in the first normal form.
- The primary key of the table should have exactly 1 column.
The first point is obviously straightforward since we just studied 1NF. Let us understand the second point: a 1-column primary key. A primary key is a set of columns that uniquely identifies a row. Here, no 2 rows have the same primary keys.
In this table, the course code is unique so that becomes our primary key. Let us take another example of storing student enrollment in various courses. Each student may enroll in multiple courses. Similarly, each course may have multiple enrollments. A sample table may look like this (student name and course code):
|
|
|
| Rahul | CS152 |
| Rajat | CS101 |
| Rahul | CS154 |
| Raman | CS101 |
Here, the first column is the student name and the second column is the course taken by the student.
Clearly, the student name column isn’t unique as we can see that there are 2 entries corresponding to the name ‘Rahul’ in row 1 and row 3. Similarly, the course code column is not unique as we can see that there are 2 entries corresponding to course code CS101 in row 2 and row 4.
However, the tuple (student name, course code) is unique since a student cannot enroll in the same course more than once. So, these 2 columns when combined form the primary key for the database.
As per the second normal form definition, our enrollment table above isn’t in the second normal form. To achieve the same (1NF to 2NF), we can rather break it into 2 tables:
|
|
|
| Rahul | 1 |
| Rajat | 2 |
| Raman | 3 |
Here the second column is unique and it indicates the enrollment number for the student. Clearly, the enrollment number is unique. Now, we can attach each of these enrollment numbers with course codes.
|
|
|
| CS101 | 2 |
| CS101 | 3 |
| CS152 | 1 |
| CS154 | 1 |
These 2 tables together provide us with the exact same information as our original table.
Third Normal Form (3NF)
Before we delve into the details of third normal form, let us understand the concept of a functional dependency on a table.
Column A is said to be functionally dependent on column B if changing the value of A may require a change in the value of B. As an example, consider the following table:
|
|
|
|
|
| MA214 | Lecture Hall 18 | Prof. George | CS Department |
| ME112 | Auditorium building | Prof. John | Electronics Department |
Here, the department column is dependent on the professor name column. This is because if in a particular row, we change the name of the professor, we will also have to change the department value. As an example, suppose MA214 is now taken by Prof. Ronald who happens to be from the mathematics department, the table will look like this:
|
|
|
|
|
| MA214 | Lecture Hall 18 | Prof. Ronald | Mathematics Department |
| ME112 | Auditorium building | Prof. John | Electronics Department |
Here, when we changed the name of the professor, we also had to change the department column. This is not desirable since someone who is updating the database may remember to change the name of the professor, but may forget updating the department value. This can cause inconsistency in the database.
Third normal form avoids this by breaking this into separate tables:
|
|
|
|
| MA214 | Lecture Hall 18 | 1 |
| ME112 | Auditorium building, | 2 |
Here, the third column is the ID of the professor who’s taking the course.
|
|
|
|
| 1 | Prof. Ronald | Mathematics Department |
| 2 | Prof. John | Electronics Department |
Here, in the above table, we store the details of the professor against his/her ID. This way, whenever we want to reference the professor somewhere, we don’t have to put the other details of the professor in that table again. We can simply use the ID.
Therefore, in the third normal form, the following conditions are required:
- The table should be in the second normal form.
- There should not be any functional dependency.
Boyce-Codd Normal Form (BCNF)
The Boyce-Codd Normal form is a stronger generalization of the third normal form. A table is in Boyce-Codd Normal form if and only if at least one of the following conditions are met for each functional dependency A → B:
- A is a superkey
- It is a trivial functional dependency.
Let us first understand what a superkey means. To understand BCNF in DBMS, consider the following BCNF example table:
Here, the first column (course code) is unique across various rows. So, it is a superkey. Consider the combination of columns (course code, professor name). It is also unique across various rows. So, it is also a superkey. A superkey is basically a set of columns such that the value of that set of columns is unique across various rows. That is, no 2 rows have the same set of values for those columns. Some of the superkeys for the table above are:
- Course code, professor name
- Course code, professor mobile number
A superkey whose size (number of columns) is the smallest is called a candidate key. For instance, the first superkey above has just 1 column. The second one and the last one have 2 columns. So, the first superkey (Course code) is a candidate key.
Boyce-Codd Normal Form says that if there is a functional dependency A → B, then either A is a superkey or it is a trivial functional dependency. A trivial functional dependency means that all columns of B are contained in the columns of A. For instance, (course code, professor name) → (course code) is a trivial functional dependency because when we know the value of course code and professor name, we do know the value of course code and so, the dependency becomes trivial.
Let us understand what’s going on:
A is a superkey: this means that only and only on a superkey column should it be the case that there is a dependency of other columns. Basically, if a set of columns (B) can be determined knowing some other set of columns (A), then A should be a superkey. Superkey basically determines each row uniquely.
It is a trivial functional dependency: this means that there should be no non-trivial dependency. For instance, we saw how the professor’s department was dependent on the professor’s name. This may create integrity issues since someone may edit the professor’s name without changing the department. This may lead to an inconsistent database.
Another example would be if a company had employees who work in more than one department. The corresponding database can be decomposed into where the functional dependencies could be such keys as employee ID and employee department.
Fourth normal form
A table is said to be in fourth normal form if there is no two or more, independent and multivalued data describing the relevant entity.
Fifth normal form
A table is in fifth normal form if:
- It is in its fourth normal form.
- It cannot be subdivided into any smaller tables without losing some form of information.
- Normalization is Important for Database Systems
Normalization in DBMS is useful for designing the schema of a database such that there is no data replication which may possibly lead to inconsistencies. While designing the schema for applications, we should always think about how we can make use of these forms.
If you want to learn more about SQL , check out our post on the best SQL certifications . You can also read about SQL vs MySQL to learn about what the two are. To become a data engineer , you’ll need to learn about normalization and a lot more, so get started today.
- Frequently Asked Questions
1. Does database normalization reduce the database size?
Yes, database normalization does reduce database size. Redundant data is removed, so the database disk storage use becomes smaller.
2. Which normal form can remove all the anomalies in DBMS?
5NF will remove all anomalies. However, generally, most 3NF tables will be free from anomalies.
3. Can database normalization reduce the number of tables?
Database normalization increases the number of tables. This is because we split tables into sub-tables in order to eliminate redundant data.
4. What is the Difference between BCNF and 3NF?
BCNF is an extension of 3NF. The primary difference is that it removes the transitive dependency from a relation.
People are also reading:
- SQL Courses
- SQL Certifications
- Download SQL Cheat Sheet PDF
- Top DBMS Interview Questions & Answers
- Difference between MongoDB vs MySQL
- Create Database in MySQL
- What is Stored Procedure?
- Difference between OLTP vs OLAP
- What is MongoDB?
- Basic SQL Command

Entrepreneur, Coder, Speed-cuber, Blogger, fan of Air crash investigation! Aman Goel is a Computer Science Graduate from IIT Bombay. Fascinated by the world of technology he went on to build his own start-up - AllinCall Research and Solutions to build the next generation of Artificial Intelligence, Machine Learning and Natural Language Processing based solutions to power businesses.
Subscribe to our Newsletter for Articles, News, & Jobs.
Disclosure: Hackr.io is supported by its audience. When you purchase through links on our site, we may earn an affiliate commission.
In this article
- Download SQL Injection Cheat Sheet PDF for Quick References SQL Cheat Sheets
- SQL vs MySQL: What’s the Difference and Which One to Choose SQL MySQL
- What is SQL? A Beginner's Definitive Guide SQL
Please login to leave comments
This video might be helpful to you: https://www.youtube.com/watch?v=B5r8CcTUs5Y
4 years ago
Sagar Jaybhay
Very very nice explanation
Tiago Mendes
Thank you for your the tutorial, it was explained well and easy to folow!
2 years ago
nice explanation
4 months ago
Always be in the loop.
Get news once a week, and don't worry — no spam.
{{ errors }}
{{ message }}
- Help center
- We ❤️ Feedback
- Advertise / Partner
- Write for us
- Privacy Policy
- Cookie Policy
- Change Privacy Settings
- Disclosure Policy
- Terms and Conditions
- Refund Policy
Disclosure: This page may contain affliate links, meaning when you click the links and make a purchase, we receive a commission.
Database Normalization: A Step-By-Step-Guide With Examples
Database normalisation is a concept that can be hard to understand.
But it doesn’t have to be.
In this article, I’ll explain what normalisation in a DBMS is and how to do it, in simple terms.
By the end of the article, you’ll know all about it and how to do it.
So let’s get started.
Want to improve your database modelling skills? Click here to get my Database Normalisation Checklist: a list of things to do as you normalise or design your database!
Table of Contents
What Is Database Normalization?
Database normalisation, or just normalisation as it’s commonly called, is a process used for data modelling or database creation, where you organise your data and tables so it can be added and updated efficiently.
It’s something a person does manually, as opposed to a system or a tool doing it. It’s commonly done by database developers and database administrators.
It can be done on any relational database , where data is stored in tables that are linked to each other. This means that normalization in a DBMS (Database Management System) can be done in Oracle, Microsoft SQL Server, MySQL, PostgreSQL and any other type of database.
To perform the normalization process, you start with a rough idea of the data you want to store, and apply certain rules to it in order to get it to a more efficient form.
I’ll show you how to normalise a database later in this article.
Why Normalize a Database?
So why would anyone want to normalize their database?
Why do we want to go through this manual process of rearranging the data?
There are a few reasons we would want to go through this process:
- Make the database more efficient
- Prevent the same data from being stored in more than one place (called an “insert anomaly”)
- Prevent updates being made to some data but not others (called an “update anomaly”)
- Prevent data not being deleted when it is supposed to be, or from data being lost when it is not supposed to be (called a “delete anomaly”)
- Ensure the data is accurate
- Reduce the storage space that a database takes up
- Ensure the queries on a database run as fast as possible
Normalization in a DBMS is done to achieve these points. Without normalization on a database, the data can be slow, incorrect, and messy .
Data Anomalies
Some of these points above relate to “anomalies”.
An anomaly is where there is an issue in the data that is not meant to be there . This can happen if a database is not normalised.
Let’s take a look at the different kinds of data anomalies that can occur and that can be prevented with a normalised database.
Our Example
We’ll be using a student database as an example in this article, which records student, class, and teacher information.
Let’s say our student database looks like this:
| 1 | John Smith | 200 | Economics | Economics 1 | Biology 1 | |
| 2 | Maria Griffin | 500 | Computer Science | Biology 1 | Business Intro | Programming 2 |
| 3 | Susan Johnson | 400 | Medicine | Biology 2 | ||
| 4 | Matt Long | 850 | Dentistry |
This table keeps track of a few pieces of information:
- The student names
- The fees a student has paid
- The classes a student is taking, if any
This is not a normalised table, and there are a few issues with this.
Insert Anomaly
An insert anomaly happens when we try to insert a record into this table without knowing all the data we need to know.
For example, if we wanted to add a new student but did not know their course name.
The new record would look like this:
| 1 | John Smith | 200 | Economics | Economics 1 | Biology 1 | |
| 2 | Maria Griffin | 500 | Computer Science | Biology 1 | Business Intro | Programming 2 |
| 3 | Susan Johnson | 400 | Medicine | Biology 2 | ||
| 4 | Matt Long | 850 | Dentistry | |||
We would be adding incomplete data to our table, which can cause issues when trying to analyse this data.
Update Anomaly
An update anomaly happens when we want to update data, and we update some of the data but not other data.
For example, let’s say the class Biology 1 was changed to “Intro to Biology”. We would have to query all of the columns that could have this Class field and rename each one that was found.
| 1 | John Smith | 200 | Economics | Economics 1 | ||
| 2 | Maria Griffin | 500 | Computer Science | Business Intro | Programming 2 | |
| 3 | Susan Johnson | 400 | Medicine | Biology 2 | ||
| 4 | Matt Long | 850 | Dentistry |
There’s a risk that we miss out on a value, which would cause issues.
Ideally, we would only update the value once, in one location.
Delete Anomaly
A delete anomaly occurs when we want to delete data from the table, but we end up deleting more than what we intended.
For example, let’s say Susan Johnson quits and her record needs to be deleted from the system. We could delete her row:
| 1 | John Smith | 200 | Economics | Economics 1 | Biology 1 | |
| 2 | Maria Griffin | 500 | Computer Science | Biology 1 | Business Intro | Programming 2 |
| 4 | Matt Long | 850 | Dentistry |
But, if we delete this row, we lose the record of the Biology 2 class, because it’s not stored anywhere else. The same can be said for the Medicine course.
We should be able to delete one type of data or one record without having impacts on other records we don’t want to delete.
What Are The Normal Forms?
The process of normalization involves applying rules to a set of data. Each of these rules transforms the data to a certain structure, called a normal form .
There are three main normal forms that you should consider (Actually, there are six normal forms in total, but the first three are the most common).
Whenever the first rule is applied, the data is in “ first normal form “. Then, the second rule is applied and the data is in “ second normal form “. The third rule is then applied and the data is in “ third normal form “.
Fourth and fifth normal forms are then achieved from their specific rules.
Alright, so there are three main normal forms that we’re going to look at. I’ve written a post on designing a database , but let’s see what is involved in getting to each of the normal forms in more detail.
What Is First Normal Form?
First normal form is the way that your data is represented after it has the first rule of normalization applied to it. Normalization in DBMS starts with the first rule being applied – you need to apply the first rule before applying any other rules.
Let’s start with a sample database. In this case, we’re going to use a student and teacher database at a school. We mentioned this earlier in the article when we spoke about anomalies, but here it is again.
Our Example Database
We have a set of data we want to capture in our database, and this is how it currently looks. It’s a single table called “student” with a lot of columns.
| John Smith | 18-Jul-00 | 04-Aug-91 | 3 Main Street, North Boston 56125 | Economics 1 (Business) | Biology 1 (Science) | James Peterson | 44 March Way, Glebe 56100 | Economics | ||
| Maria Griffin | 14-May-01 | 10-Sep-92 | 16 Leeds Road, South Boston 56128 | Biology 1 (Science) | Business Intro (Business) | Programming 2 (IT) | James Peterson | 44 March Way, Glebe 56100 | Computer Science | |
| Susan Johnson | 03-Feb-01 | 13-Jan-91 | 21 Arrow Street, South Boston 56128 | Biology 2 (Science) | Sarah Francis | Medicine | ||||
| Matt Long | 29-Apr-02 | 25-Apr-92 | 14 Milk Lane, South Boston 56128 | Shane Cobson | 105 Mist Road, Faulkner 56410 | Dentistry |
Everything is in one table.
How can we normalise this?
We start with getting the data to First Normal Form.
To apply first normal form to a database, we look at each table, one by one, and ask ourselves the following questions of it:
Does the combination of all columns make a unique row every single time?
What field can be used to uniquely identify the row?
Let’s look at the first question.
No. There could be the same combination of data, and it would represent a different row. There could be the same values for this row and it would be a separate row (even though it is rare).
The second question says:
Is this the student name? No, as there could be two students with the same name.
Address? No, this isn’t unique either.
Any other field?
We don’t have a field that can uniquely identify the row.
If there is no unique field, we need to create a new field. This is called a primary key, and is a database term for a field that is unique to a single row. (Related: The Complete Guide to Database Keys )
When we create a new primary key, we can call it whatever we like, but it should be obvious and consistently named between tables. I prefer using the ID suffix, so I would call it student ID.
This is our new table:
Student ( student ID , student name, fees paid, date of birth, address, subject 1, subject 2, subject 3, subject 4, teacher name, teacher address, course name)
This can also be represented in an Entity Relationship Diagram (ERD):

The way I have written this is a common way of representing tables in text format. The table name is written, and all of the columns are shown in brackets, with the primary key underlined.
This data is now in first normal form.
This example is still in one table, but it’s been made a little better by adding a unique value to it.
Want to find a tool that creates these kinds of diagrams? There are many tools for creating these kinds of diagrams. I’ve listed 76 of them in this guide to Data Modeling Tools , along with reviews, price, and other features. So if you’re looking for one to use, take a look at that list.
What Is Second Normal Form?
The rule of second normal form on a database can be described as:
- Fulfil the requirements of first normal form
- Each non-key attribute must be functionally dependent on the primary key
What does this even mean?
It means that the first normal form rules have been applied. It also means that each field that is not the primary key is determined by that primary key , so it is specific to that record. This is what “functional dependency” means.
Let’s take a look at our table.
Are all of these columns dependent on and specific to the primary key?
The primary key is student ID, which represents the student. Let’s look at each column:
- student name: Yes, this is dependent on the primary key. A different student ID means a different student name.
- fees paid: Yes, this is dependent on the primary key. Each fees paid value is for a single student.
- date of birth: Yes, it’s specific to that student.
- address: Yes, it’s specific to that student.
- subject 1: No, this column is not dependent on the student. More than one student can be enrolled in one subject.
- subject 2: As above, more than one subject is allowed.
- subject 3: No, same rule as subject 2.
- subject 4: No, same rule as subject 2
- teacher name: No, the teacher name is not dependent on the student.
- teacher address: No, the teacher address is not dependent on the student.
- course name: No, the course name is not dependent on the student.
We have a mix of Yes and No here. Some fields are dependent on the student ID, and others are not.
How can we resolve those we marked as No?
Let’s take a look.
First, the subject 1 column. It is not dependent on the student, as more than one student can have a subject, and the subject isn’t a part of the definition of a student.
So, we can move it to a new table:
Subject (subject name)
I’ve called it subject name because that’s what the value represents. When we are writing queries on this table or looking at diagrams, it’s clearer what subject name is instead of using subject.
Now, is this field unique? Not necessarily. Two subjects could have the same name and this would cause problems in our data.
So, what do we do? We add a primary key column, just like we did for student. I’ll call this subject ID, to be consistent with the student ID.
Subject ( subject ID , subject name)
This means we have a student table and a subject table. We can do this for all four of our subject columns in the student table, removing them from the student table so it looks like this:
Student ( student ID , student name, fees paid, date of birth, address, teacher name, teacher address, course name)
But they are in separate tables. How do we link them together?
We’ll cover that shortly. For now, let’s keep going with our student table.
The next column we marked as No was the Teacher Name column. The teacher is separate to the student so should be captured separately. This means we should move it to its own table.
Teacher (teacher name)
We should also move the teacher address to this table, as it’s a property of the teacher. I’ll also rename teacher address to be just address.
Teacher (teacher name, address)
Just like with the subject table, the teacher name and address is not unique. Sure, in most cases it would be, but to avoid duplication we should add a primary key. Let’s call it teacher ID,
Teacher ( teacher ID , teacher name, address)
The last column we have to look at was the Course Name column. This indicates the course that the student is currently enrolled in.
While the course is related to the student (a student is enrolled in a course), the name of the course itself is not dependent on the student.
So, we should move it to a separate table. This is so any changes to courses can be made independently of students.
The course table would look like this:
Course (course name)
Let’s also add a primary key called course ID.
Course ( course ID , course name)
We now have our tables created from columns that were in the student table. Our database so far looks like this:
Student ( student ID , student name, fees paid, date of birth, address) Subject ( subject ID , subject name) Teacher ( teacher ID , teacher name, address) Course ( course ID , course name)
Using the data from the original table, our data could look like this:
| 1 | John Smith | 18-Jul-00 | 04-Aug-91 | 3 Main Street, North Boston 56125 |
| 2 | Maria Griffin | 14-May-01 | 10-Sep-92 | 16 Leeds Road, South Boston 56128 |
| 3 | Susan Johnson | 03-Feb-01 | 13-Jan-91 | 21 Arrow Street, South Boston 56128 |
| 4 | Matt Long | 29-Apr-02 | 25-Apr-92 | 14 Milk Lane, South Boston 56128 |
| 1 | Economics 1 (Business) |
| 2 | Biology 1 (Science) |
| 3 | Business Intro (Business) |
| 4 | Programming 2 (IT) |
| 5 | Biology 2 (Science) |
| 1 | James Peterson | 44 March Way, Glebe 56100 |
| 2 | Sarah Francis | |
| 3 | Shane Cobson | 105 Mist Road, Faulkner 56410 |
| 1 | Computer Science |
| 2 | Dentistry |
| 3 | Economics |
| 4 | Medicine |
How do we link these tables together? We still need to know which subjects a student is taking, which course they are in, and who their teachers are.
Foreign Keys in Tables
We have four separate tables, capturing different pieces of information. We need to capture that students are taking certain courses, have teachers, and subjects. But the data is in different tables.
How can we keep track of this?
We use a concept called a foreign key.
A foreign key is a column in one table that refers to the primary key in another table . Related: The Complete Guide to Database Keys .
It’s used to link one record to another based on its unique identifier, without having to store the additional information about the linked record.
Here are our two tables so far:
Student ( student ID , student name, fees paid, date of birth, address) Subject ( subject ID , subject name) Teacher ( teacher ID , teacher name, teacher address) Course ( course ID , course name)
To link the two tables using a foreign key, we need to put the primary key (the underlined column) from one table into the other table.
Let’s start with a simple one: students taking courses. For our example scenario, a student can only be enrolled in one course at a time, and a course can have many students.
We need to either:
- Add the course ID from the course table into the student table
- Add the student ID from the student table into the course table
But which one is it?
In this situation, I ask myself a question to work out which way it goes:
Does a table1 have many table2s, or does a table2 have many table1s?
If it’s the first, then table1 ID goes into table 2, and if it’s the second then table2 ID goes into table1.
So, if we substitute table1 and table2 for course and student:
Does a course have many students, or does a student have many courses?
Based on our rules, the first statement is true: a course has many students.
This means that the course ID goes into the student table.
Student ( student ID , course ID , student name, fees paid, date of birth, address) Subject ( subject ID , subject name) Teacher ( teacher ID , teacher name, teacher address) Course ( course ID , course name)
I’ve italicised it to indicate it is a foreign key – a value that links to a primary key in another table.
When we actually populate our tables, instead of having the course name in the student table, the course ID goes in the student table. The course name can then be linked using this ID.
| 1 | 3 | John Smith | 200 | 4 Aug 1991 | 3 Main Street, North Boston 56125 |
| 2 | 1 | Maria Griffin | 500 | 10 Sep 1992 | 16 Leeds Road, South Boston 56128 |
| 3 | 4 | Susan Johnson | 400 | 13 Jan 1991 | 21 Arrow Street, South Boston 56128 |
| 4 | 2 | Matt Long | 850 | 25 Apr 1992 | 14 Milk Lane, South Boston 56128 |
This also means that the course name is stored in one place only, and can be added/removed/updated without impacting other tables.
I’ve created a YouTube video to explain how to identify and diagram one-to-many relationships like this:
We’ve linked the student to the course. Now let’s look at the teacher.
How are teachers related? Depending on the scenario, they could be related in one of a few ways:
- A student can have one teacher that teaches them all subjects
- A subject could have a teacher than teaches it
- A course could have a teacher that teaches all subjects in a course
In our scenario, a teacher is related to a course. We need to relate these two tables using a foreign key.
Does a teacher have many courses, or does a course have many teachers?
In our scenario, the first statement is true. So the teacher ID goes into the course table:
Student ( student ID , course ID , student name, fees paid, date of birth, address) Subject ( subject ID , subject name) Teacher ( teacher ID , teacher name, teacher address) Course ( course ID , teacher ID , course name)
The table data would look like this:
| 1 | 1 | Computer Science |
| 2 | 3 | Dentistry |
| 3 | 1 | Economics |
| 4 | 2 | Medicine |
This allows us to change the teacher’s information without impacting the courses or students.
Student and Subject
So we’ve linked the course, teacher, and student tables together so far.
What about the subject table?
Does a subject have many students, or does a student have many subjects?
The answer is both.
How is that possible?
A student can be enrolled in many subjects at a time, and a subject can have many students in it.
How can we represent that? We could try to put one table’s ID in the other table:
| 1 | 3 | 1, 2 | John Smith | 200 | 4 Aug 1991 | 3 Main Street, North Boston 56125 |
| 2 | 1 | 2, 3, 2004 | Maria Griffin | 500 | 10 Sep 1992 | 16 Leeds Road, South Boston 56128 |
| 3 | 4 | 5 | Susan Johnson | 400 | 13 Jan 1991 | 21 Arrow Street, South Boston 56128 |
| 4 | 2 | Matt Long | 850 | 25 Apr 1992 | 14 Milk Lane, South Boston 56128 |
But if we do this, we’re storing many pieces of information in one column, possibly separated by commas.
This makes it hard to maintain and is very prone to errors.
If we have this kind of relationship, one that goes both ways, it’s called a many to many relationship . It means that many of one record is related to many of the other record.
Many to Many Relationships
A many to many relationship is common in databases. Some examples where it can happen are:
- Students and subjects
- Employees and companies (an employee can have many jobs at different companies, and a company has many employees)
- Actors and movies (an actor is in multiple movies, and a movie has multiple actors)
If we can’t represent this relationship by putting a foreign key in each table, how can we represent it?
We use a joining table.
This is a table that is created purely for storing the relationships between the two tables.
It works like this. Here are our two tables:
Student ( student ID , course ID , student name, fees paid, date of birth, address) Subject ( subject ID , subject name)
And here is our joining table:
Subject_Student ( student ID , subject ID )
It has two columns. Student ID is a foreign key to the student table, and subject ID is a foreign key to the subject table.
Each record in the row would look like this:
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
| 2 | 3 |
| 2 | 4 |
| 3 | 5 |
Each row represents a relationship between a student and a subject.
Student 1 is linked to subject 1.
Student 1 is linked to subject 2.
Student 2 is linked to subject 2.
This has several advantages:
- It allows us to store many subjects for each student, and many students for each subject.
- It separates the data that describes the records (subject name, student name, address, etc.) from the relationship of the records (linking ID to ID).
- It allows us to add and remove relationships easily.
- It allows us to add more information about the relationship. We could add an enrolment date, for example, to this table, to capture when a student enrolled in a subject.
You might be wondering, how do we see the data if it’s in multiple tables? How can we see the student name and the name of the subjects they are enrolled in?
Well, that’s where the magic of SQL comes in. We use a SELECT query with JOINs to show the data we need. But that’s outside the scope of this article – you can read the articles on my Oracle Database page to find out more about writing SQL.
One final thing I have seen added to these joining tables is a primary key of its own. An ID field that represents the record. This is an optional step – a primary key on a single new column works in a similar way to defining the primary key on the two ID columns. I’ll leave it out in this example.
So, our final table structure looks like this:
Student ( student ID , course ID , student name, fees paid, date of birth, address) Subject ( subject ID , subject name) Subject Enrolment ( student ID , subject ID ) Teacher ( teacher ID , teacher name, teacher address) Course ( course ID , teacher ID , course name)
I’ve called the table Subject Enrolment. I could have left it as the concatenation of both of the related tables (student subject), but I feel it’s better to rename the table to what it actually captures – the fact a student has enrolled in a subject. This is something I recommend in my SQL Best Practices post .
I’ve also underlined both columns in this table, as they represent the primary key. They can also represent a foreign key, which is why they are also italicised.
An ERD of these tables looks like this:

This database structure is in second normal form. We almost have a normalised database.
Now, let’s take a look at third normal form.
What Is Third Normal Form?
Third normal form is the final stage of the most common normalization process. The rule for this is:
- Fulfils the requirements of second normal form
- Has no transitive functional dependency
What does this even mean? What is a transitive functional dependency?
It means that every attribute that is not the primary key must depend on the primary key and the primary key only .
For example:
- Column A determines column B
- Column B determines column C
- Therefore, column A determines C
This means that column A determines column B which determines column C . This is a transitive functional dependency, and it should be removed. Column C should be in a separate table.
We need to check if this is the case for any of our tables.
Student ( student ID , course ID , student name, fees paid, date of birth, address)
Do any of the non-primary-key fields depend on something other than the primary key?
No, none of them do. However, if we look at the address, we can see something interesting:
| 3 Main Street, North Boston 56125 |
| 16 Leeds Road, South Boston 56128 |
| 21 Arrow Street, South Boston 56128 |
| 14 Milk Lane, South Boston 56128 |
We can see that there is a relationship between the ZIP code and the city or suburb. This is common with addresses, and you may have noticed this if you have filled out any forms for addresses online recently.
How are they related? The ZIP code, or postal code, determines the city, state, and suburb.
In this case, 56128 is South Boston, and 56125 is North Boston. (I just made this up so this is probably inaccurate data).
This falls into the pattern we mentioned earlier: A determines B which determines C.
Student determines the address ZIP code which determines the suburb.
So, how can we improve this?
We can move the ZIP code to another table, along with everything it identifies, and link to it from the student table.
Our table could look like this:
Student ( student ID , course ID , student name, fees paid, date of birth, street address, address code ID ) Address Code ( address code ID , ZIP code, suburb, city, state)
I’ve created a new table called Address Code, and linked it to the student table. I created a new column for the address code ID, because the ZIP code may refer to more than one suburb. This way we can capture that fact, and it’s in a separate table to make sure it’s only stored in one place.
Let’s take a look at the other tables:
Subject ( subject ID , subject name) Subject Enrolment ( student ID , subject ID )
Both of these tables have no columns that aren’t dependent on the primary key.
Teacher ( teacher ID , teacher name, teacher address)
The teacher table also has the same issue as the student table when we look at the address. We can, and should use the same approach for storing address.
So our table would look like this:
Teacher ( teacher ID , teacher name, street address, address code ID ) Address Code ( address code ID , ZIP code, suburb, city, state)
It uses the same Address Code table as mentioned above. We aren’t creating a new address code table.
Finally, the course table:
Course ( course ID , teacher ID , course name)
This table is OK. The course name is dependent on the course ID.
So, what does our database look like now?
Student ( student ID , course ID , student name, fees paid, date of birth, street address, address code ID ) Address Code ( address code ID , ZIP code, suburb, city, state) Subject ( subject ID , subject name) Subject Enrolment ( student ID , subject ID ) Teacher ( teacher ID , teacher name, street address, address code ID ) Course ( course ID , teacher ID , course name)
So, that’s how third normal form could look if we had this example.
An ERD of third normal form would look like this:

Stopping at Third Normal Form
For most database normalisation exercises, stopping after achieving Third Normal Form is enough .
It satisfies a good relationship rules and will greatly improve your data structure from having no normalisation at all.
There are a couple of steps after third normal form that are optional. I’ll explain them here so you can learn what they are.
Fourth Normal Form and Beyond
Fourth normal form is the next step after third normal form.
What does it mean?
It needs to satisfy two conditions:
- Meet the criteria of third normal form.
- There are no non-trivial multivalued dependencies other than a candidate key.
So, what does this mean?
A multivalued dependency is probably better explained with an example, which I’ll show you shortly. It means that there are other attributes in the table that are not dependent on the primary key, and can be moved to another table.
Our database looks like this:
This meets the third normal form rules.
However, let’s take a look at the address fields: street address and address code.
- Both the student and teacher table have these
- What if a student moves addresses? Do we update the address in this field? If we do, then we lose the old address.
- If an address is updated, is it because they moved? Or is it because there was an error in the old address?
- What if two students have the same street address. Are they actually at the same address? What if we update one and not the other?
- What if a teacher and a student are at the same address?
- What if we want to capture a student or a teacher having multiple addresses (for example, postal and residential)?
There are a lot of “what if” questions here. There is a way we can resolve them and improve the quality of the data.
This is a multivalued dependency.
We can solve this by moving the address to a separate table .
The address can then be linked to the teacher and student tables.
Let’s start with the address table.
Address ( address ID , street address, address code ID )
In this table, we have a primary key of address ID, and we have stored the street address here. The address code table stays the same.
We need to link this to the student and teacher tables. How do we do this?
Do we also want to capture the fact that a student or teacher can have multiple addresses? It may be a good idea to future proof the design. It’s something you would want to confirm in your organisation.
For this example, we will design it so there can be multiple addresses for a single student.
Our tables could look like this:
Student ( student ID , course ID , student name, fees paid, date of birth) Address ( address ID , street address, address code ID ) Address Code ( address code ID , ZIP code, suburb, city, state) Student Address ( address ID, student ID ) Subject ( subject ID , subject name) Subject Enrolment ( student ID , subject ID ) Teacher ( teacher ID , teacher name) Teacher Address ( teacher ID, address ID ) Course ( course ID , teacher ID , course name)
An ERD would look like this:

A few changes have been made here:
- The address code ID has been removed from the Student table, because the relationships between student and address is now captured in the joining table called Student Address.
- The teacher’s address is also captured in the joining table Teacher Address, and the address code ID has been removed from the Teacher table. I couldn’t think of a better name for each of these tables.
- Address still links to address code ID
This design will let you do a few things:
- Store multiple addresses for each student or teacher
- Store additional information about an address relationship to a teach or student, such as an effective date (to track movements over time) or an address type (postal, residential)
- Determine which students or teachers live at the same address with certainty (it’s linked to the same record).
So, that’s how you can achieve fourth normal form on this database.
There are a few enhancements you can make to this design, but it depends on your business rules:
- Combine the student and teacher tables into a person table, as they are both effectively people, but teachers teach a class and students take a class. This table could then link to subjects and define that relationship as “teaches” or “is enrolled in”, to cater for this.
- Relate a course to a subject, so you can see which subjects are in a course
- Split the address into separate fields for unit number, street number, address line 1, address line 2, and so on.
- Split the student name and teacher name into first and last names to help with displaying data and sorting.
These changes could improve the design, but I haven’t detailed them in any of these steps as they aren’t required for fourth normal form.
I hope this explanation has helped you understand what the normal forms are and what normalization in DBMS is. Do you have any questions on this process? Share them in the section below.
Lastly, if you enjoy the information and career advice I’ve been providing, sign up to my newsletter below to stay up-to-date on my articles. You’ll also receive a fantastic bonus. Thanks!
68 thoughts on “Database Normalization: A Step-By-Step-Guide With Examples”

Thanks so much for explaining this concept Ben. To me as a learner, this is the best way to grab this concept.
You broke this down to the last atom. Keep up the good work!

Thanks James, glad you found it helpful!

Absolutely, the best and easiest explanation I have seen. Very helpful.

Saludos Ben, buen post. Podrías por favor revisar la simbología que utilizaste en la relación de las tablas Student y Course, dado que comentaste en las líneas de arriba “significa que la identificación del curso entra en la tabla de estudiantes.” Comenta si la relación sería: Course -< Student
Hi Ronald, Sure, I’ll check this and update the post. (Google Translate: Greetings Ben, good post. Could you please check the symbology you used in the Student and Course table relationship, since you commented on the lines above “it means that the course identification enters the student table.” Comment if the relationship would be: Course – < Student)
Saludos Ben, la simbología de Courses y Student según planteaste es de “1 a n” verifica si sería ” -< " Buen post.
Thanks Ronald! (Google Translate: Greetings Ben, the symbology of Courses and Student as you raised is “1 to n” verifies if it would be “- <" Good post.)

thank you for sharing these things to us , damn i really love it. You guys are really awesome

i dont understand the second normal form linking student id to course id isnt clear

Excellent working example
Glad you found it useful!

This is a nice compilation and a good illustration of how to carry out table normalization. I wish you can provide script samples that represent the ERD you presented here. It will be so much helpful.
Hi DJ, Glad you like the article. Good idea – I’ll create some sample scripts and add them to the post. Thanks, Ben

Good job! This is a great way explaining this topic. You made it look easy to understand. But, one question I have for you is where is a best scenario in real life used the fourth normal form?
Hi Nati, Thanks, I’m glad you like the article. I’m not sure what would be a realistic example of using fourth normal form. I think many 3NF databases can be turned into 4NF, depending on how to want to record values (either a value in a table or an ID to another table). I haven’t used it that often.

Dear Sir’ Can we call the Fourth Normal Form as a BCNF (Boyce Codd Normal Form). Or not?
Hi Subzar, I think Fourth Normal Form is slightly different to BCNF. I haven’t used either method but I know they are a little different. I think 4NF comes after BCNF.

Hey Ben, Your notes are too helpful. Will recommend my other friends for sure. Thanks a lot :)

You’ve done a truly superb job on the majority of this. You’ve used far more details than most people who provide examples do.
Particularly good is the splitting of addresses into a separate table. That is just not done nearly enough.
However, two tables have critical problems: (1) The Student table should not contain Course ID (nor fees paid); there should be a separate Student_Course intersection table. (2) Similarly, the Course table should not have a Teacher ID, likewise a separate Course_Teacher intersection table should be created.
Reasoning (condensed): (1) A student must be able to enroll first, without yet specificying a course. The student’s name and other enrollment data are not related to any specific course. (2) A course has data of its own not related to the teacher: # of credit/lab hours, cost(s), first term offered, last term offered, etc.. Should the only teacher currently teaching a course withdraw from it, the course data should not be lost. Courses have prerequisites, sometimes complex ones, that have nothing to do with who is teaching the course.
Thanks for the feedback Scott and glad you like the post! I understand your reasoning, and yes ideally there would be those two intersection tables. These scenarios are things that we, as developers, would clarify during the design. The example I went with was a simple one where a student must have a course and a course must have a teacher, but in the real world it would cater to your scenarios. Thanks again, Ben

Simple & powerfully conveyed. Thank you.
Glad you found it helpful!

As a grade 11 teacher, I am well aware of the complexities students face when teaching/explaining the concepts within this topic. This article is brilliant and breaks down such a confusing topic quite nicely with examples along the way. My students will definitely benefit from this, thank you so much.

I am just starting out in SQL and this was quite helpful. Thanks.

what a tremendous insights about the normalisation you have explained and its gave me a lot of confedence Thank u some much ben my deepest gratitude for sharing knowledge . you truly proved sharing is caring with regards chandu, india

Came across your material while searching for Normalisation material, as wanting to use my time to improve my Club Membership records, having gained a ‘Database qualification’ some 20 to 30 years years ago, I think, I needed to refresh my memory! Anyway – some queries:
1. Shouldn’t the Student Name be broken down or decomposed into StudentForename and StudentSurname, since doesn’t 1NF require this? 2. Shouldn’t Teacher Name be converted as per 121 above as well?
This would enable records to be retrieved using Surname or Forename
Hi Tim, yes that’s a good point and it would be better to break it into two names for that purpose.

Wow, this is the very first website i finally thoroughly understood normalization. Thanks a lot.
Hello again
I have thought thru the data I need to record, I think, time will tell I suspect. Anyway we run upto 18 competitions, played by teams of 1, 2 3 or 4 members, thus I think that there may be Many to Many relationship between Member and Competition tables, as in Many Member records may be related to Many Competition records [potential for a Pairs or Triples or Fours teams to win all the Competitions they enter], am I correct?
Also should I design the Competition table as CompID, Year, Comp1, Comp 2, Comp3, each Header having the name of the Competition, then I presume a table that links the two, along the lines of:
CompID, Year, MemberID OR MemberID, Year, CompID
Regards, Tim
Hello again, thinking further, I presume that I could create 18 tables, one per Competition to capture the annual results.
Again though, presume my single Comp table (see above) shouldn’t have a column per comp, as this is a repeating group
So do I create a ‘joining table’, that records Year and Comp, another that records Member and Comp and one that records Member and Year.
I may be over thinking it, but as No Comp this year, I think I need to be able to record this, I think
Hi Tim, good question. You could create one table per competition, but you would have 18 tables which have the same structure and different data, which is quite repetitive. I would suggest having a single table for comp, and a column that indicates which competition it is for. It’s OK for a table to have a value that is repeated like this, as it identifies which competition something refers to. Yes you could create joining tables for Year and Comp (if there is a many to many relationship between them) and Member and Comp as well. What’s the relationship between Member and Year?
Thanks for reply, however, would it be easier to say create a Comp table of 18 records, a Comp Type table which has 2 records, that is Annual and One Day, another table for Comp Year, which will record the annual competition results based on:
CompYear – CompTypeID – CompID – MemID
thus each year would create 32 records [10 x 1 + 4 x2 + 2 x3 + 2 x 4], e.g
2019 – 1 – 4 – 1 2019 – 1 – 4 – 2 2019 – 1 – 4 – 3 2019 – 1 – 4 – 4 2019 – 1 – 3 – 1 2019 – 1 – 3 – 2 2019 – 1 – 3 – 3 2019 – 2 – 1 – 1
so members 1 to 4 won the 2019 one day comp Bickford Fours; and members 1 to 3 won the 2019 one day comp Arthur Johnson Triples; and member 1 won the 2019 annual singles championship
Would this work and have I had a light bulb moment?
Hi Tim, yes I think that would work! Storing the comp data separately from the comp type (and so on) will ensure the data is not repeated and is only stored in one place. Good luck!

Ben, Thank you so much! I was only able to grasp the concept of normalization in one hour or so because how you simplified the concepts through a simple running example.

Thanks a lot sir Daniel i have really understood this you are a great teacher

Firstly :Thank you for your website. Secondly: I have still problem with understanding the Second normal form. For example you have written : “student name: Yes, this is dependent on the primary key. A different student ID means a different student name.”. So in your design I am not allowed to have 2 students with same names? What will happen when this, not so uncommon situation occurs?
Glad you like it Wojtek! Yes, in this design you can have two students with the same name. They would have different IDs and different rows in the table, as two people with the same name is common like you mentioned.

This is the best explanation on why and how to normalize Tables… excellent work, maybe the best explanation out there….

Hi, Thanks for the post. That is exactly what I was looking for. But I have a question, how would I insert into student address and teacher address. Best regards

This is amazing, very well explained. Simple example made it easy to understand. Thank you so much!

Thanks sir, this very helpful

Sorry but your example is not in 1NF. 1NF dictates that you cannot have a repeating group. The subjects are a repeating group. Not saying you got the design wrong at the end just that you failed to remove the repeating group in 1NF. When you went to 2NF you made rules for the repeating group multiple times and took care of it but it should have been taken care of in 1NF.

Its so helpful easy to understand

This is great! You make it easy and simple to learn where I can understand.

If you”re going to break address into atoms, (unit, street, city, zip, etc.), would you also break down telephone numbers, (country code, area code, exchange, unit number) into separate fields in another table? How elemental do you go?

Clearly explained :)

Wow c’est vraiment très utile, ça vient d’apporter un plus ma connaissance. Vraiment merci beaucoup pour cet article.

Great post! Just wanted to check – for the ERD diagram in the 2NF example, wouldn’t the relationship between Course and Student be the other way around? A course can have many students, but a student can only be enrolled in one course. So the crows feet symbol should be on the Student table.

Hi Ben, I am hoping you can respond to the question above. I noticed the same and I was hoping to find a correction or explanation in the notes. I second everyone else’s compliments on a great post, too.

From table Student (student ID, course ID, student name, fees paid, date of birth, street address, address code ID) why you put “street address” column remember that “address code ID” is available idenitify address of student i dont understand here

Hi Ben ! ive got a question for you. i didnt understand this part:
So that means in a first normal form duplicate roes are allowed?

I stumbled on this article explaining so succinctly about normalization of database. I must admit that it helped me understand the concept using an example far much better than just theory.
Kudos to you @Ben – You are really a DB star.
Will recommend it to my friends. I am in the process of putting this knowledge into an Employee Management System.

Mmnh ! Thank you sir, it’s very awesome tutor. 👍

The model breaks as soon as you add a 2nd course for a student. CourseID should not be in the student table. You need a separate table that ties studentID and courseID together
That’s a good point. Yes you would need a separate table for that scenario.

The ERDs for the 2nd / 3rd / 4th normal form show the crows foot at the COURSE table, but the STUDENT table receives the FK course_id. The crows foot represents the many end of the relationship, but there is no representation in the course table of any student data point.
Imho, this is where it is broken in addition to what Dan has pointed to.

Loved it – easy explanation. Thank you – love from India

Well done Ben, this is the best normalization tutorial I have ever seen. Thanks so much. keep up the good work.

Thanks for taking the time to create this. This is one of the best breakdowns that I’ve read regarding DB Normalization. However, I can’t really wrap my mind around 4NF as I would like to know how to use it in a real life scenario. Thanks again as this was extremely helpful to me!

Thank you . Very clear explanation

If the statement is true that each student can only have 1 course, then the relationship is not shown correctly in the ERD.

Hi, I don’t quite understand how your example satisfies third normal form. It seems that street address could depend on address ID, which depends upon the primary key. In other words, if address ID were to change, I would assume street address would also have to change. So doesn’t that create transitive dependency?
ii) I also don’t understand why you made two address tables, couldn’t they be combined into one?

Hi ben thanks for superb work.
What I always think that how to determine functional dependency? In this example , After 1NF, we know that course is not functionally dependent on student id because it is day to day example & it make sense.
however While designing DB for client whose domain is unknown to us, how to know effectively the functional dependency from client? What question we should ask as layman?

Thank you very much

This is my last stop to understanding data normalisation after two years of searching and searching. Thousands of tons of thanks Ben.

thanks so much sir have really enjoyed the class and gain alot
Leave a Comment Cancel Reply
Your email address will not be published. Required fields are marked *
This site uses Akismet to reduce spam. Learn how your comment data is processed .
DBMS Normalization: 1NF, 2NF, 3NF Database Example
What is Database Normalization?
Normalization is a database design technique that reduces data redundancy and eliminates undesirable characteristics like Insertion, Update and Deletion Anomalies. Normalization rules divides larger tables into smaller tables and links them using relationships. The purpose of Normalization in SQL is to eliminate redundant (repetitive) data and ensure data is stored logically.
The inventor of the relational model Edgar Codd proposed the theory of normalization of data with the introduction of the First Normal Form, and he continued to extend theory with Second and Third Normal Form. Later he joined Raymond F. Boyce to develop the theory of Boyce-Codd Normal Form.
Types of Normal Forms in DBMS
Here is a list of Normal Forms in SQL:
- 1NF (First Normal Form): Ensures that the database table is organized such that each column contains atomic (indivisible) values, and each record is unique. This eliminates repeating groups, thereby structuring data into tables and columns.
- 2NF (Second Normal Form): Builds on 1NF by We need to remove redundant data from a table that is being applied to multiple rows. and placing them in separate tables. It requires all non-key attributes to be fully functional on the primary key.
- 3NF (Third Normal Form): Extends 2NF by ensuring that all non-key attributes are not only fully functional on the primary key but also independent of each other. This eliminates transitive dependency.
- BCNF (Boyce-Codd Normal Form): A refinement of 3NF that addresses anomalies not handled by 3NF. It requires every determinant to be a candidate key, ensuring even stricter adherence to normalization rules.
- 4NF (Fourth Normal Form): Addresses multi-valued dependencies. It ensures that there are no multiple independent multi-valued facts about an entity in a record.
- 5NF (Fifth Normal Form): Also known as “Projection-Join Normal Form” (PJNF), It pertains to the reconstruction of information from smaller, differently arranged data pieces.
- 6NF (Sixth Normal Form): Theoretical and not widely implemented. It deals with temporal data (handling changes over time) by further decomposing tables to eliminate all non-temporal redundancy.
The Theory of Data Normalization in MySQL server is still being developed further. For example, there are discussions even on 6 th Normal Form. However, in most practical applications, normalization achieves its best in 3 rd Normal Form . The evolution of Normalization in SQL theories is illustrated below-
Database Normalization With Examples
Database Normalization Example can be easily understood with the help of a case study. Assume, a video library maintains a database of movies rented out. Without any normalization in database, all information is stored in one table as shown below. Let’s understand Normalization database with normalization example with solution:

Here you see Movies Rented column has multiple values. Now let’s move into 1st Normal Forms:
First Normal Form (1NF)
- Each table cell should contain a single value.
- Each record needs to be unique.
The above table in 1NF-
1NF Example

Before we proceed let’s understand a few things —
What is a KEY in SQL
A KEY in SQL is a value used to identify records in a table uniquely. An SQL KEY is a single column or combination of multiple columns used to uniquely identify rows or tuples in the table. SQL Key is used to identify duplicate information, and it also helps establish a relationship between multiple tables in the database.
Note: Columns in a table that are NOT used to identify a record uniquely are called non-key columns.
What is a Primary Key?

A primary is a single column value used to identify a database record uniquely.
It has following attributes
- A primary key cannot be NULL
- A primary key value must be unique
- The primary key values should rarely be changed
- The primary key must be given a value when a new record is inserted.
What is Composite Key?
A composite key is a primary key composed of multiple columns used to identify a record uniquely
In our database, we have two people with the same name Robert Phil, but they live in different places.

Hence, we require both Full Name and Address to identify a record uniquely. That is a composite key.
Let’s move into second normal form 2NF
Second Normal Form (2NF)
- Rule 1- Be in 1NF
- Rule 2- Single Column Primary Key that does not functionally dependent on any subset of candidate key relation
It is clear that we can’t move forward to make our simple database in 2 nd Normalization form unless we partition the table above.

We have divided our 1NF table into two tables viz. Table 1 and Table2. Table 1 contains member information. Table 2 contains information on movies rented.
We have introduced a new column called Membership_id which is the primary key for table 1. Records can be uniquely identified in Table 1 using membership id
Database – Foreign Key
In Table 2, Membership_ID is the Foreign Key

Foreign Key references the primary key of another Table! It helps connect your Tables
- A foreign key can have a different name from its primary key
- It ensures rows in one table have corresponding rows in another
- Unlike the Primary key, they do not have to be unique. Most often they aren’t
- Foreign keys can be null even though primary keys can not

Why do you need a foreign key?
Suppose, a novice inserts a record in Table B such as

You will only be able to insert values into your foreign key that exist in the unique key in the parent table. This helps in referential integrity.
The above problem can be overcome by declaring membership id from Table2 as foreign key of membership id from Table1
Now, if somebody tries to insert a value in the membership id field that does not exist in the parent table, an error will be shown!
What are transitive functional dependencies?
A transitive functional dependency is when changing a non-key column, might cause any of the other non-key columns to change
Consider the table 1. Changing the non-key column Full Name may change Salutation.

Let’s move into 3NF
Third Normal Form (3NF)
- Rule 1- Be in 2NF
- Rule 2- Has no transitive functional dependencies
To move our 2NF table into 3NF, we again need to again divide our table.
3NF Example
Below is a 3NF example in SQL database:

We have again divided our tables and created a new table which stores Salutations.
There are no transitive functional dependencies, and hence our table is in 3NF
In Table 3 Salutation ID is primary key, and in Table 1 Salutation ID is foreign to primary key in Table 3
Now our little example is at a level that cannot further be decomposed to attain higher normal form types of normalization in DBMS. In fact, it is already in higher normalization forms. Separate efforts for moving into next levels of normalizing data are normally needed in complex databases. However, we will be discussing next levels of normalisation in DBMS in brief in the following.
Boyce-Codd Normal Form (BCNF)
Even when a database is in 3 rd Normal Form, still there would be anomalies resulted if it has more than one Candidate Key.
Sometimes is BCNF is also referred as 3.5 Normal Form.
Fourth Normal Form (4NF)
If no database table instance contains two or more, independent and multivalued data describing the relevant entity, then it is in 4 th Normal Form.
Fifth Normal Form (5NF)
A table is in 5 th Normal Form only if it is in 4NF and it cannot be decomposed into any number of smaller tables without loss of data.
Sixth Normal Form (6NF) Proposed
6 th Normal Form is not standardized, yet however, it is being discussed by database experts for some time. Hopefully, we would have a clear & standardized definition for 6 th Normal Form in the near future…
Advantages of Normal Form
- Improve Data Consistency: Normalization ensures that each piece of data is stored in only one place, reducing the chances of inconsistent data. When data is updated, it only needs to be updated in one place, ensuring consistency.
- Reduce Data Redundancy: Normalization helps eliminate duplicate data by dividing it into multiple, related tables. This can save storage space and also make the database more efficient.
- Improve Query Performance: Normalized databases are often easier to query. Because data is organized logically, queries can be optimized to run faster.
- Make Data More Meaningful: Normalization involves grouping data in a way that makes sense and is intuitive. This can make the database easier to understand and use, especially for people who didn’t design the database.
- Reduce the Chances of Anomalies: Anomalies are problems that can occur when adding, updating, or deleting data. Normalization can reduce the chances of these anomalies by ensuring that data is logically organized.
Disadvantages of Normalization
- Increased Complexity: Normalization can lead to complex relations. An extensive number of tables with foreign keys can be difficult to manage, leading to confusion.
- Reduced Flexibility: Due to the strict rules of normalization, there might be less flexibility in storing data that doesn’t adhere to these rules.
- Increased Storage Requirements: While normalization reduces redundancy, It may be necessary to allocate more storage space to accommodate the additional tables and indices.
- Performance Overhead: Joining multiple tables can be costly in terms of performance. The more normalized the data, the more joins are needed, which can slow down data retrieval times.
- Loss of Data Context: Normalization breaks down data into separate tables, which can lead to a loss of business context. Examining related tables is necessary to understand the context of a piece of data.
- Need for Expert Knowledge: Implementing a normalized database requires a deep understanding of the data, the relationships between data, and the normalization rules. This requires expert knowledge and can be time-consuming.
That’s all to SQL Normalization!!!
- Database designing is critical to the successful implementation of a database management system that meets the data requirements of an enterprise system.
- Normalization in DBMS is a process which helps produce database systems that are cost-effective and have better security models.
- Functional dependencies are a very important component of the normalize data process
- Most database systems are normalized database up to the third normal forms in DBMS.
- A primary key uniquely identifies are record in a Table and cannot be null
- A foreign key helps connect table and references a primary key
- Database Design in DBMS Tutorial: Learn Data Modeling
- MySQL Workbench Tutorial: What is, How to Install & Use
- What is a Database? Definition, Meaning, Types with Example
- MySQL SELECT Statement with Examples
- SQL Tutorial for Beginners: Learn SQL in 7 Days
- MySQL Tutorial for Beginners: Learn MySQL Basics in 7 Days
- 17 Best SQL Tools & Software (2024)
- MariaDB vs MySQL – Difference Between Them
Normalization in SQL DBMS: 1NF, 2NF, 3NF, and BCNF Examples

Introduction
If you've started learning about databases, you may have come across the term "normalization" or "database normalization".
In this article, you'll learn what normalization is, what the benefits are, and how to perform normalization in SQL using some database normalization examples.
What is Normalization in SQL?
Normalization, also known as database normalization or normalization in SQL, is a process to improve a design of a database to meet specific rules.
When you create database tables and add columns, you're able to create them in almost any way and configuration that you like.
However, to use the benefits of a database and to have an effective design, it helps to follow a certain set of rules. The process of applying these rules is called normalization, and it has several benefits.
The main benefit of normalization is that a piece of information is stored in a single place.
Let's look at an example. Let's say we're designing a database for an eCommerce store that sells shoes.
One of the main items you'll store information about is the name of a product, such as a shoe called "Nike Air Max". On the website for this eCommerce store, you may need to show this in several places:
- A list of products to browse
- A person's shopping cart, which is a list of products they have added to a cart for purchasing
- A customer's order and purchase receipt
There's a potential for this product name to be stored in many places in the database.
However, with a normalized database, the product name of Nike Air Max is only stored in one place. Any other area of the database that needs to know about the product name can refer to this specific product record.
Why is this helpful? There are a few reasons:
- Making updates to a record is easier because it only needs to be done in one place
- References to the record can be changed without removing the record
- It's easier to keep a history of records over time
- It reduces the risk of data entry errors
How Does Normalization Impact SQL?
You might be wondering how the outcome of the normalization process impacts your SQL queries.
Normalization will likely result in more tables being created and more relationships between the tables.
A common reaction to this is that it would make writing SQL queries harder, because there are more tables to think about when writing, and slower, because there are more joins used.
However, that's not necessarily the case. Here are some benefits to writing SQL on a normalized database:
- Less data is considered: with multiple smaller tables, there is less data for the database to look through and consider when returning results of a query, compared to tables with more rows and more columns.
- Performance can be optimised: there are many ways to increase the performance of queries if there are many tables used
- One place to make changes: writing Insert, Update, or Delete statements to make changes to data is easier because there's only one place to do it.
How to Normalize
How do you follow the process of SQL normalization?
There are several stages of the normalization process. The three main stages are:
- First normal form
- Second normal form
- Third normal form
A database is said to be normalized if it meets the rules specified in "third normal form", which is the third stage of the DBMS normalization process.
There are several further stages of SQL normalization, or database normal forms, such as Boyce Codd Normal Form and Fourth Normal Form.
We'll explain each of these stages in this article.
Our Example
As we work through the normalization in DBMS process in this article, we'll continue our example of an online shoe store.

First Normal Form
The first normal form is the first step in the process.
For a database design to be in first normal form, or 1NF, each row needs to have a primary key, and each field needs to contain a single value.
In our example, the Category column can contain several values (Men or Women or Kids), and the Color column contains several values (Black, White, Green, and many others).
We also do not have a primary key in the table.
So, this design does not meet first normal form.
To adhere to the first normal form, we can add a new product ID column to the table, and move the Category and Color values to separate tables.

This design now meets first normal form.
Second Normal Form
For a database to meet second normal form, or 2NF, it must meet the rules of first normal form, and also "each non-key attribute must be functionally dependent on the primary key".
This means that any column that is not the primary key needs to depend on the primary key. If it doesn't, we need to solve that.
Does each column in the product table depend on the product ID?
- product name: Yes, this is directly related to the product ID.
- usage: This contains values such as Casual or Running, and it's not dependent on the product ID. It can exist separately to the product.
- manufacturer: The manufacturer does not depend on the product ID. A manufacturer, such as Nike, can exist independently of this Nike Air Max product.
- price: Yes, this is specific to this product.
- size: No, the size can exist separately from the product.
- description: Yes, this is specific to this product.
- number in stock: Yes, this is specific to this product.
We have several attributes that are not dependent on the product ID. They should be created as separate tables:
- manufacturer
We can create the tables in a similar way to the color and category tables.

Another step we need to take as part of second normal form is relating our tables together. This is done by adding foreign keys to tables, so that they can relate to the correct record.
Our database design currently has data in separate tables, but we still need to know which of the values in each table apply to a product. For example, we need to know the color of our product, even if it's in a separate table.
We do this by adding a foreign key to one of the tables.

We can take the same approach for the other tables. The product needs to relate to the correct usage, size, category, and manufacturer records.

Our design is now in second normal form.
Third Normal Form
The next step is called third normal form. This is a common place to end the SQL normalization process, because the design allows for efficient SQL queries and addresses the issues of databases that aren't normalised.
A design will meet third normal form if it has no "transitive functional dependency".
A "transitive functional dependency" means that every attribute that is not the primary key is dependent on only the primary key.
For example, in one table:
- Column A determines Column B
- Column B determines Column C
This is a "transitive functional dependency" because Column C depends on Column B instead of Column A.
How do we apply this to our design?
For all of our newer smaller tables (usage, size, category, color, and manufacturer), they all meet these criteria. They only have two columns, and the second column (the name) is dependent on the first column (the ID).
Let's look at our product table. For each of our columns, are they dependent on something other than the primary key of product ID?
- category ID: No, this is only dependent on the product ID.
- color ID: No, this is only dependent on the product ID
- usage ID: No
- size ID: Maybe - we'll look at this shortly.
- manufacturer ID: No
- product name: No
- description: No
- number in stock: No
What does the size ID column represent? It refers to a size of the product, such as "US Mens 9" from our example.
However, other size values could be "EU Womens 37" or "UK Mens 8". These sizes are actually dependent on whether the product is for Men or Women, so they are dependent on the category.
In our design, one way we can solve this is by removing the category ID from the product table and adding it to the size table.

So, our example Nike Air Max shoe would have a size ID that relates to the size of "US Mens 9", and this size record would have a category ID that relates to the value of "Mens".
Our design now meets third normal form. Because of this, our design is said to be normalized.
If we want to enhance our design, there are some more steps or "database normal forms" that can be applied.
BCNF stands for Boyce-Codd Normal Form, and it's a slightly stricter version of third normal form. It's often referred to as 3.5NF because it's close to third normal form.
A database design will meet BCNF if all redundancy based on functional dependency has been removed. This is best explained with an example.
It's uncommon that you'll find a table that is in third normal form but not in BCNF. We don't see any in our design for products.

All of the columns depend on the ID of the table.
However, we have an address in both tables. The address could be separated into its own table, and related to the teacher and student table.

BCNF is one of the normal forms in SQL that is not used very often, but it's helpful if you want to make improvements to your design to reduce the risk of redundancy.
Fourth Normal Form
Fourth normal form is the next level of normalization in SQL after BCNF.
Just like with BCNF, this is one of the uncommon normal forms in SQL, but it's still possible that your design can meet third normal form or BCNF but not meet fourth normal form.
The definition of fourth normal form is that "are no non-trivial multivalued dependencies other than a candidate key."
This means that any dependency between columns in the table involves a column that could be the primary key.
Let's see an example of fourth normal form.
We don't have any in our product database, so we'll use a different database normalization example for this.
Let's say we had a customer table.

And here's some sample data:
This table contains two pieces of information about a customer:
- the operating system that the customer uses, which can be more than one
- the location the customer is based in, which is one value
This table also shows that these two pieces of information are independent: the operating system is not dependent on or related to the location. Both of the columns are dependent on the individual customer (the ID).
It also shows that there can be multiple values for an operating system, which is an example of a multi-valued dependency.
To move this into fourth normal form, we need to separate this multi-valued dependency into a separate table.

Our sample data would look like this:
customer _ operating _ system
The multi-valued dependency has been removed, and this design is now in fourth normal form.
The SQL normalization process is a great way to improve the design of a database, by removing the risk of poor data quality, redundant data, and missing data. It also remains easy to write SQL queries against the tables to get the data you need.
The database normal forms can be summarised as:
- First normal form: each table needs a primary key
- Second normal form: any column that is not the primary key needs to depend on the primary key
- Third normal form: any column that is not the primary key is only dependent on the primary key (and no other columns)
- Boyce-Codd normal form: remove functional dependencies
- Fourth normal form: remove multi-valued dependencies
When you create or modify your database by writing SQL queries, you'll need a tool to do this. PopSQL is a great choice for this, as it helps you and your team work together on SQL and store your scripts in a central location (as well as many other helpful features).
Spread the word
Ready for a modern SQL editor?
Home » Data Modeling / Database » A Comprehensive Guide to Database Normalization with Examples
A Comprehensive Guide to Database Normalization with Examples
- Posted on September 15, 2023
- / Under Data Modeling / Database
Introduction
Database normalization is a crucial concept in the world of database management. It is a process that optimizes database structure by reducing data redundancy and improving data integrity. Normalization is a set of rules and guidelines that help organize data efficiently and prevent common data anomalies like update anomalies, insertion anomalies, and deletion anomalies.
In this article, we will delve into the fundamentals of database normalization, the various normal forms, and provide practical examples to illustrate each level of normalization.
Why Normalize a Database?
Before we dive into the details of database normalization, it’s essential to understand why it’s necessary. Normalization offers several advantages:
- Data Integrity: Normalization helps maintain data accuracy and consistency by reducing redundancy. When data is stored in a non-repetitive manner, it is less prone to errors.
- Efficient Storage: Normalized databases tend to occupy less storage space as duplicate data is minimized. This reduces the overall cost of storage.
- Query Optimization: Queries become more efficient in normalized databases because they need to access smaller, well-structured tables instead of large, denormalized ones.
- Flexibility: Normalized databases are more flexible when it comes to accommodating changes in data requirements or business rules.
Levels of Normalization

- First Normal Form (1NF): Ensures that each column in a table contains atomic, indivisible values. There should be no repeating groups, and each column should have a unique name.
- Second Normal Form (2NF): Building on 1NF, 2NF eliminates partial dependencies. A table is in 2NF if it’s in 1NF and all non-key attributes are functionally dependent on the entire primary key.
- Third Normal Form (3NF): Building on 2NF, 3NF eliminates transitive dependencies. A table is in 3NF if it’s in 2NF and all non-key attributes are functionally dependent on the primary key, but not on other non-key attributes.
- Boyce-Codd Normal Form (BCNF): A stricter version of 3NF, BCNF ensures that every non-trivial functional dependency is a superkey. This means that no partial dependencies or transitive dependencies are allowed.
- Fourth Normal Form (4NF): 4NF deals with multi-valued dependencies, where an attribute depends on another attribute but is not a function of the primary key.
- Fifth Normal Form (5NF) or Project-Join Normal Form (PJNF): These forms deal with cases where a table is in 4NF, but there are join dependencies that can be further optimized.
Now, let’s illustrate these normal forms with examples:
First Normal Form (1NF)
Consider an unnormalized table that stores customer orders:
| OrderID | Customer | Products |
|---|---|---|
| 1 | John | Apples, Bananas, Oranges |
| 2 | Alice | Grapes, Strawberries |
| 3 | Bob | Lemons, Limes |
This table violates 1NF because the Products column contains a list of items. To bring it to 1NF, we split the products into separate rows:
| OrderID | Customer | Product |
|---|---|---|
| 1 | John | Apples |
| 1 | John | Bananas |
| 1 | John | Oranges |
| 2 | Alice | Grapes |
| 2 | Alice | Strawberries |
| 3 | Bob | Lemons |
| 3 | Bob | Limes |
Now, each cell contains an atomic value, and the table is in 1NF.
Second Normal Form (2NF)
Consider a table that stores information about students and their courses:
| StudentID | CourseID | CourseName | Instructor |
|---|---|---|---|
| 1 | 101 | Math | Prof. Smith |
| 1 | 102 | Physics | Prof. Johnson |
| 2 | 101 | Math | Prof. Smith |
| 3 | 103 | History | Prof. Davis |
This table violates 2NF because the Instructor attribute depends on both StudentID and CourseID . To achieve 2NF, we split the table into two separate tables:
Students Table:
| StudentID | StudentName |
|---|---|
| 1 | John |
| 2 | Alice |
| 3 | Bob |
Courses Table:
| CourseID | CourseName | Instructor |
|---|---|---|
| 101 | Math | Prof. Smith |
| 102 | Physics | Prof. Johnson |
| 103 | History | Prof. Davis |
Now, the Instructor attribute depends only on the CourseID , and the table is in 2NF.
Third Normal Form (3NF)
Consider a table that stores information about employees and their projects:
| EmployeeID | ProjectID | ProjectName | Manager |
|---|---|---|---|
| 1 | 101 | ProjectA | John |
| 1 | 102 | ProjectB | Alice |
| 2 | 101 | ProjectA | John |
| 3 | 103 | ProjectC | Bob |
This table violates 3NF because the Manager attribute depends on the EmployeeID , not directly on the primary key. To bring it to 3NF, we split the table into two separate tables:
Employees Table:
| EmployeeID | EmployeeName |
|---|---|
| 1 | John |
| 2 | Alice |
| 3 | Bob |
Projects Table:
| ProjectID | ProjectName |
|---|---|
| 101 | ProjectA |
| 102 | ProjectB |
| 103 | ProjectC |
EmployeeProjects Table:
| EmployeeID | ProjectID |
|---|---|
| 1 | 101 |
| 1 | 102 |
| 2 | 101 |
| 3 | 103 |
Now, the Manager attribute depends on the ProjectID , and the table is in 3NF.
Boyce-Codd Normal Form (BCNF)
BCNF is a stricter version of 3NF. To illustrate BCNF, consider a table that stores information about professors and their research areas:
| ProfessorID | ResearchArea | OfficeNumber |
|---|---|---|
| 1 | Artificial Intelligence | 101 |
| 2 | Machine Learning | 102 |
| 3 | Artificial Intelligence | 103 |
This table violates BCNF because there is a non-trivial functional dependency between ResearchArea and OfficeNumber (i.e., the office number depends on the research area). To achieve BCNF, we split the table into two separate tables:
Professors Table:
| ProfessorID | ProfessorName |
|---|---|
| 1 | Prof. Smith |
| 2 | Prof. Johnson |
| 3 | Prof. Davis |
ResearchAreas Table:
| ResearchArea | OfficeNumber |
|---|---|
| Artificial Intelligence | 101 |
| Machine Learning | 102 |
ProfessorResearch Table:
| ProfessorID | ResearchArea |
|---|---|
| 1 | Artificial Intelligence |
| 2 | Machine Learning |
| 3 | Artificial Intelligence |
Now, the table is in BCNF because there are no non-trivial functional dependencies.
Fourth Normal Form (4NF)
4NF deals with multi-valued dependencies. Consider a table that stores information about books and their authors:
| BookID | Title | Authors |
|---|---|---|
| 1 | BookA | AuthorX, AuthorY |
| 2 | BookB | AuthorY, AuthorZ |
| 3 | BookC | AuthorX |
This table violates 4NF because there is a multi-valued dependency between BookID and Authors . To achieve 4NF, we split the table into three separate tables:
Books Table:
| BookID | Title |
|---|---|
| 1 | BookA |
| 2 | BookB |
| 3 | BookC |
Authors Table:
| AuthorID | AuthorName |
|---|---|
| 1 | AuthorX |
| 2 | AuthorY |
| 3 | AuthorZ |
BookAuthors Table:
| BookID | AuthorID |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
| 2 | 3 |
| 3 | 1 |
Now, each table is in 4NF, and multi-valued dependencies are removed.
Fifth Normal Form (5NF) or Project-Join Normal Form (PJNF)
5NF or PJNF deals with join dependencies, which are beyond the scope of this introductory article. Achieving 5NF typically involves further decomposition and is often necessary for complex databases.
Database normalization is a critical process in database design, aimed at optimizing data storage, improving data integrity, and reducing data anomalies. By organizing data into normalized tables, you can enhance the efficiency and maintainability of your database system.
Remember that achieving higher normal forms, such as BCNF and 4NF, may not always be necessary for all databases. The level of normalization depends on the specific requirements of your application and the trade-offs between data integrity and performance.
When designing a database, it’s essential to strike a balance between normalization and practicality. In many cases, achieving 3NF is sufficient to ensure data integrity while maintaining good query performance.
Understanding the principles of normalization and practicing them with real-world examples is crucial for database administrators and developers to create efficient and robust database systems.
Leave a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Visual Paradigm Online
- Request Help
- Customer Service
- Community Circle
- Demo Videos
- Visual Paradigm
- YouTube Channel
- Academic Partnership
Database Normalization – Normal Forms 1nf 2nf 3nf Table Examples

In relational databases, especially large ones, you need to arrange entries so that other maintainers and administrators can read them and work on them. This is why database normalization is important.
In simple words, database normalization entails organizing a database into several tables in order to reduce redundancy. You can design the database to follow any of the types of normalization such as 1NF, 2NF, and 3NF.
In this article, we’ll look at what database normalization is in detail and its purpose. We’ll also take a look at the types of normalization – 1NF, 2NF, 3NF – with examples.
What We'll Cover
What is database normalization, what is the purpose of normalization, the first normal form – 1nf, the second normal form – 2nf, the third normal form – 3nf, examples of 1nf, 2nf, and 3nf.
Database normalization is a database design principle for organizing data in an organized and consistent way.
It helps you avoid redundancy and maintain the integrity of the database. It also helps you eliminate undesirable characteristics associated with insertion, deletion, and updating.
The main purpose of database normalization is to avoid complexities, eliminate duplicates, and organize data in a consistent way. In normalization, the data is divided into several tables linked together with relationships.
Database administrators are able to achieve these relationships by using primary keys, foreign keys, and composite keys.
To get it done, a primary key in one table, for example, employee_wages is related to the value from another table, for instance, employee_data .
N.B. : A primary key is a column that uniquely identifies the rows of data in that table. It’s a unique identifier such as an employee ID, student ID, voter’s identification number (VIN), and so on.
A foreign key is a field that relates to the primary key in another table.
A composite key is just like a primary key, but instead of having a column, it has multiple columns.
What is 1NF 2NF and 3NF?
1NF, 2NF, and 3NF are the first three types of database normalization. They stand for first normal form , second normal form , and third normal form , respectively.
There are also 4NF (fourth normal form) and 5NF (fifth normal form). There’s even 6NF (sixth normal form), but the commonest normal form you’ll see out there is 3NF (third normal form).
All the types of database normalization are cumulative – meaning each one builds on top of those beneath it. So all the concepts in 1NF also carry over to 2NF, and so on.
For a table to be in the first normal form, it must meet the following criteria:
- a single cell must not hold more than one value (atomicity)
- there must be a primary key for identification
- no duplicated rows or columns
- each column must have only one value for each row in the table
The 1NF only eliminates repeating groups, not redundancy. That’s why there is 2NF.
A table is said to be in 2NF if it meets the following criteria:
- it’s already in 1NF
- has no partial dependency. That is, all non-key attributes are fully dependent on a primary key.
When a table is in 2NF, it eliminates repeating groups and redundancy, but it does not eliminate transitive partial dependency.
This means a non-prime attribute (an attribute that is not part of the candidate’s key) is dependent on another non-prime attribute. This is what the third normal form (3NF) eliminates.
So, for a table to be in 3NF, it must:
- have no transitive partial dependency.
Database normalization is quite technical, but we will illustrate each of the normal forms with examples.
Imagine we're building a restaurant management application. That application needs to store data about the company's employees and it starts out by creating the following table of employees:
| employee_id | name | job_code | job | state_code | home_state |
|---|---|---|---|---|---|
| E001 | Alice | J01 | Chef | 26 | Michigan |
| E001 | Alice | J02 | Waiter | 26 | Michigan |
| E002 | Bob | J02 | Waiter | 56 | Wyoming |
| E002 | Bob | J03 | Bartender | 56 | Wyoming |
| E003 | Alice | J01 | Chef | 56 | Wyoming |
All the entries are atomic and there is a composite primary key (employee_id, job_code) so the table is in the first normal form (1NF) .
But even if you only know someone's employee_id , then you can determine their name , home_state , and state_code (because they should be the same person). This means name , home_state , and state_code are dependent on employee_id (a part of primary composite key). So, the table is not in 2NF . We should separate them to a different table to make it 2NF.
Example of Second Normal Form (2NF)
Employee_roles table.
| employee_id | job_code |
|---|---|
| E001 | J01 |
| E001 | J02 |
| E002 | J02 |
| E002 | J03 |
| E003 | J01 |
employees Table
| employee_id | name | state_code | home_state |
|---|---|---|---|
| E001 | Alice | 26 | Michigan |
| E002 | Bob | 56 | Wyoming |
| E003 | Alice | 56 | Wyoming |
| job_code | job |
|---|---|
| J01 | Chef |
| J02 | Waiter |
| J03 | Bartender |
home_state is now dependent on state_code . So, if you know the state_code , then you can find the home_state value.
To take this a step further, we should separate them again to a different table to make it 3NF.
Example of Third Normal Form (3NF)
| employee_id | name | state_code |
|---|---|---|
| E001 | Alice | 26 |
| E002 | Bob | 56 |
| E003 | Alice | 56 |
states Table
| state_code | home_state |
|---|---|
| 26 | Michigan |
| 56 | Wyoming |
Now our database is in 3NF.
This article took you through what database normalization is, its purpose, and its types. We also look at those types of normalization and the criteria a table must meet before it can be certified to be in any of them.
It is worth noting that most tables don’t exceed the 3NF limit, but you can also take them to 4NF and 5NF, depending on requirements and the size of the data at hand.
If you find the article helpful, don’t hesitate to share it with friends and family.
Web developer and technical writer focusing on frontend technologies. I also dabble in a lot of other technologies.
If you read this far, thank the author to show them you care. Say Thanks
Learn to code for free. freeCodeCamp's open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Database Normalization Explained with Real-World Examples
Tousif Md. Amin Faisal
Hey there, backend developers and database enthusiasts! As you dive deeper into the world of backend development, understanding the concept of database normalization is as crucial as mastering SQL. Database normalization isn’t just a theoretical concept; it’s a practical approach to designing efficient, reliable, and scalable databases. Let’s explore why every backend developer should grasp the fundamentals of database normalization, illustrated with real-world examples.
The Essence of Database Normalization 📚
Database normalization is like the art of organizing a library. It’s a systematic approach to reducing data redundancy and improving data integrity. By following a set of rules (normal forms), you can structure your database in a way that each piece of information is stored only once. This approach not only saves storage space but also simplifies data management and enhances performance.
Real-World Examples for Clear Understanding 🌐
1. The Online Retail Store 🛍️
Imagine an online retail store database. Initially, you might store customer information (name, address, email) and their order details (order ID, product, quantity) in a single table. However, this design leads to repetition of customer information for each order they place. By normalizing the database, you separate customer information and order details into two linked tables, reducing redundancy and making updates more straightforward.
2. The Employee Management System 👥
In a company’s employee management system, you might start with a table that includes employee details, department information, and manager details. Normalization involves splitting this data into separate tables (e.g., Employees, Departments, Managers) and linking them through foreign keys. This separation ensures that changes in department or manager details are made in just one place, reflecting across the entire system.
Benefits of Database Normalization 🌟
1. Improved Data Consistency and Integrity 🛡️
Normalization ensures that each data item exists in one place. This singularity prevents inconsistencies and errors, which are common in redundant data setups.
2. Easier Modification and Deletion 🛠️
Updating or deleting data becomes more manageable when it’s stored in a normalized form. You avoid the risk of leaving orphan records or inconsistent data across tables.
3. Optimized Query Performance 🔍
While it might seem counterintuitive, a well-normalized database can actually improve query performance. With less redundant data, queries can run faster, especially in complex systems.
4. Scalability and Flexibility 📈
As your application grows, a normalized database can be more easily modified and expanded compared to a non-normalized one. This flexibility is crucial for long-term project sustainability.
Normalization in Action: A Practical Approach 🛠️
1. Understanding Normal Forms
Familiarize yourself with the normal forms — from the First Normal Form (1NF) to the Boyce-Codd Normal Form (BCNF). Each form has specific rules that guide how to organize data in tables.
2. Analyzing Relationships
Pay attention to how data is related. Understanding one-to-one, one-to-many, and many-to-many relationships is key to effective normalization.
3. Refactoring Existing Databases
Practice normalization by refactoring existing databases. This hands-on approach helps you understand the challenges and benefits of normalization in real-world scenarios.
In conclusion, database normalization is not just a theoretical exercise; it’s a practical skill that enhances the efficiency, reliability, and scalability of your databases. As a backend developer, embracing normalization techniques will empower you to design better database structures, leading to more robust and maintainable applications. So, if you haven’t already, now is the perfect time to dive into the world of database normalization. It’s an investment in your skills that will pay dividends in your career. 🚀🌟

Written by Tousif Md. Amin Faisal
Software engineer in Q3 Aurelia. BSc in CSSE from AIUB. Love reading, traveling, writing, coding. Developing software to make life easier and better #CSSE #AIUB
Text to speech

Database Normalization in SQL with Examples
gourishankar , 2020-02-18
Introduction
As a database developer, we might often come across terms like normalization and denormalization of a database. Database normalization is a technique that helps to efficiently organize data in a given database. Essentially, it is a systematic approach to decompose a larger table into smaller tables that would help to get rid of data redundancy and other inserts/ update anomalies.
According to the definition in Wikipedia -
" Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by Edgar F. Codd as part of his relational model.
Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints. It is accomplished by applying some formal rules either by a process of synthesis (creating a new database design) or decomposition (improving an existing database design). "
Database Normalization
Database Normalization is a set of rules that are applied to a database, such that the schema of the database ensures that all the rules are being followed. These rules are also known as Normal Forms and are widely used while designing database solutions.
The database normalization process can be divided into following types:
First Normal Form (1NF)
Second normal form (2nf), third normal form (3nf).
- Boyce-Codd Normal Form or Fourth Normal Form (BCNF of 4NF)
- Fifth Normal Form (5NF)
- Sixth Normal Form (6NF)
In this article, we will only understand the concepts of 1NF, 2NF and 3NF with examples. The next normal forms are out of scope for this article and will not be discussed here.
Now, let us understand the rules that needs to be applied for each normal form.
- Data is stored in tables with rows that can be uniquely identified by a Primary Key.
- Data within each table is stored in individual columns in its most reduced form.
- There are no repeating groups.
- All the rules from 1NF must be satisfied.
- Only those data that relates to a table’s primary key is stored in each table.
- All the rules from 2NF must be satisfied.
- There should be no intra-table dependencies between the columns in each table.
In this tutorial, we will be taking an already existing database sample and re-design it so that it supports all the three Normal Forms.
Let us consider the following database schema. As you can see in Fig 1 , there are four tables ( Existing Database ) - Projects , Employees , ProjectEmployees , and JobOrders . Recently, the Customers table has also been added to the database to store the customers' information. As you can see in the diagram below, the Customers table has not been designed in a proper way to support the normal forms, let's go ahead and fix it.
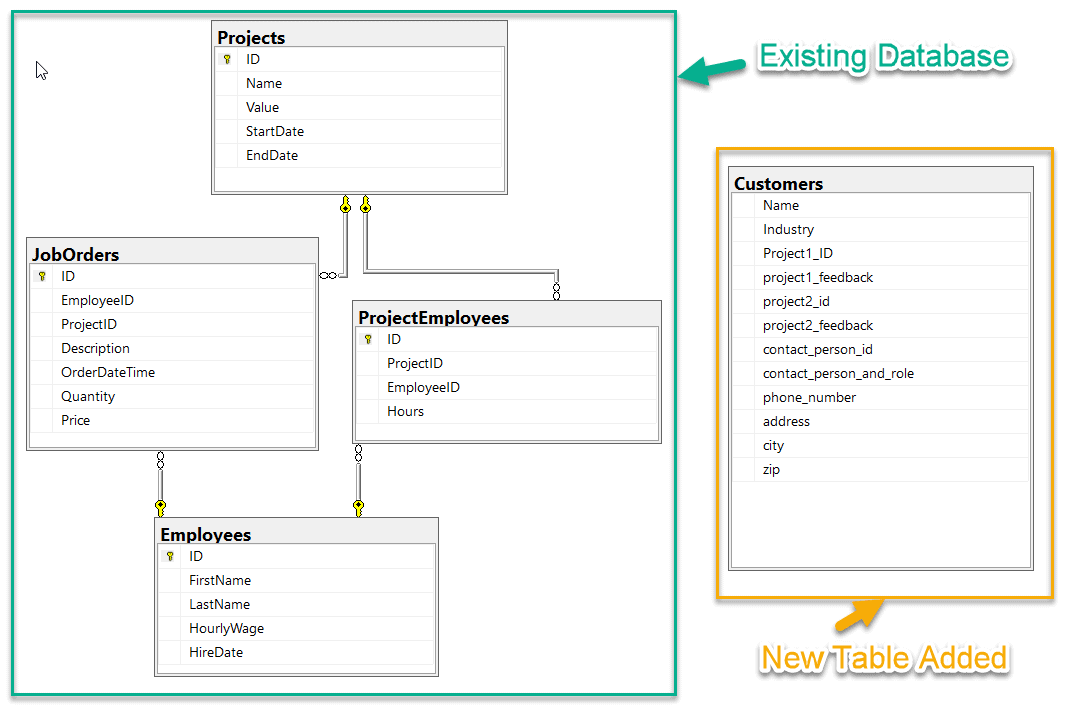
I have provided the script to create all the tables if you want to try it out on your local system.
First Normal Form
As we have already discussed above, the first normal form relates to the duplication of data and also over-grouping of data in the columns.
The Customers table in the diagram violates all the three rules of the first normal form.
- We do not see any Primary Key in the table.
- The data is not found in its most reduced form. For example, the column ContactPersonAndRole can be divided further into two individual columns - ContactPerson and ContactPersonRole .
- Also, we can see there are two repeating groups of columns in this table - ( Project1_ID , Project1_FeedBack ) and ( Project2_ID , Project2_Feedback ). We need to get these removed from this table.
The diagram below shows dummy data stored in the Customers table.

Let us now get our hands dirty and start modifying the table, so that it satisfies the first normal form.
The first thing that we need to do is to add a primary key to this table. For this, we can add a new column ID with datatype as INT and also assign it as an Identity column. The script is given below.
When you execute this script, a new column gets added at the end of all the columns. This is the primary key of the table and now it satisfies the first rule of the First Normal Form.
Secondly, we need to split the column ContactPersonAndRole into two individual columns. This can be done in two steps as follows:
- Rename the original column from ContactPersonAndRole to ContactPerson .
- Add a new column for ContactPersonRole .
The script below, when executed, will rename the original column and add a new column to store the ContactRole information.
Finally, in order to satisfy the third rule of the First Normal Form, we need to move the columns Project1_ID , Project1_Feedback , Project2_ID , and Project2_Feedback into a new table. This can be done by creating a new table ProjectFeedbacks and link it back with the Customers and the Projects table.
When the script below is executed, it will remove the above-mentioned columns from the Customers table and create a new table ProjectFeedbacks with Foreign Key references to the Customers and Projects table.
The database schema after applying all the rules of the first normal form is as below.
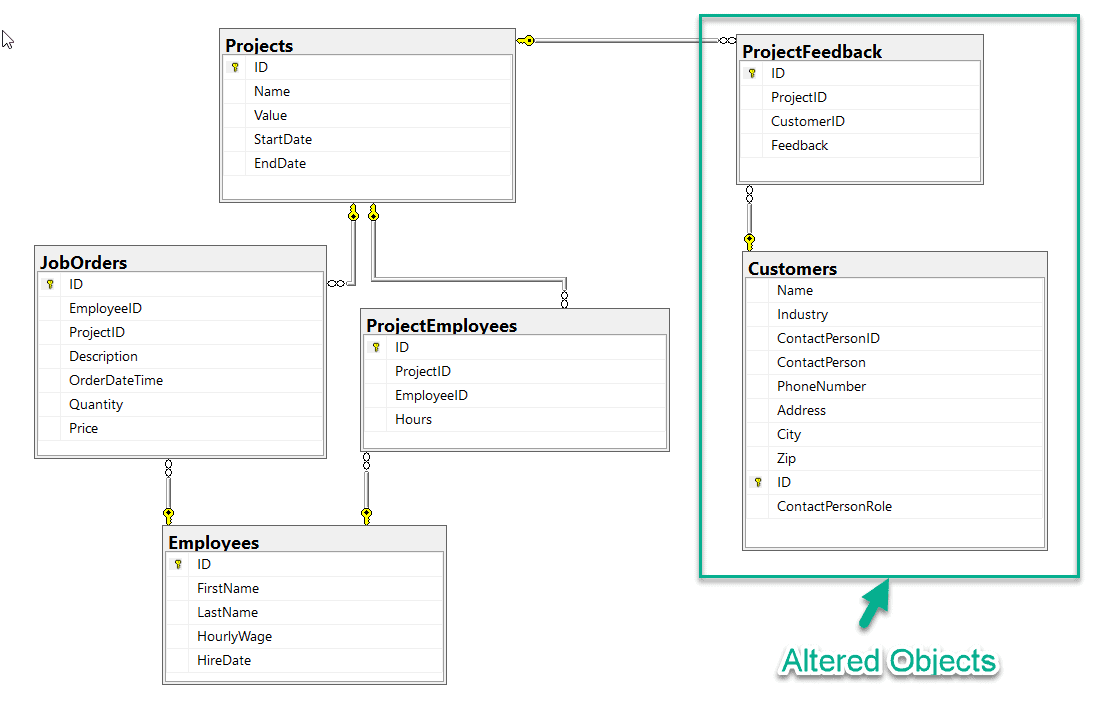
As you can see, the Customers table has been altered and a new table ProjectFeedbacks has been added into the schema. Thus, there are no repeating groups in the Customers or the ProjectFeedbacks table. We can also know about the feedbacks as it refers to both the Customers and the Projects table.
Now, that the Customers table supports 1NF, let's go ahead and apply the second normal form.
Second Normal Form
To satisfy the conditions of the second normal form, all the rules of the first normal form should satisfy. And along with that, we also need to ensure that all the columns in the table relate directly to the primary key of the record in the table.
However, if you see the database schema diagram above ( Fig 3 ), you can see that the ContactPerson , ContactPersonRole and the PhoneNumber do not directly relate to the ID of the Customers table. That is because the primary key refers to a customer and not to any person or role or the phone number of the contact person. If ever, the contact person for a customer changes, we would have to update all of these columns, running the risk that we will update the values in one of the columns but forget to modify the other.
So, in order to satisfy this rule, we need to remove these three columns from the Customers table and put them in a separate table. This table should contain data that is related only to the contact person and not the customer.
Let us remove all these columns from the Customers table which do not relate to the primary key of the table directly. The script below removes the three columns from the table as these are not related to the customer, instead of to the contact person only.
Once, the columns are removed from the Customers table, we need to create a new table that'll store the data for the contact persons. Let us create a new table ContactPersons and relate it to the Customers table with a foreign key relation. The script is provided below.
Once this script is executed, you can see in the diagram below ( Fig 4 ) that a new table has been added to the schema and now it satisfies the second normal form of the database.
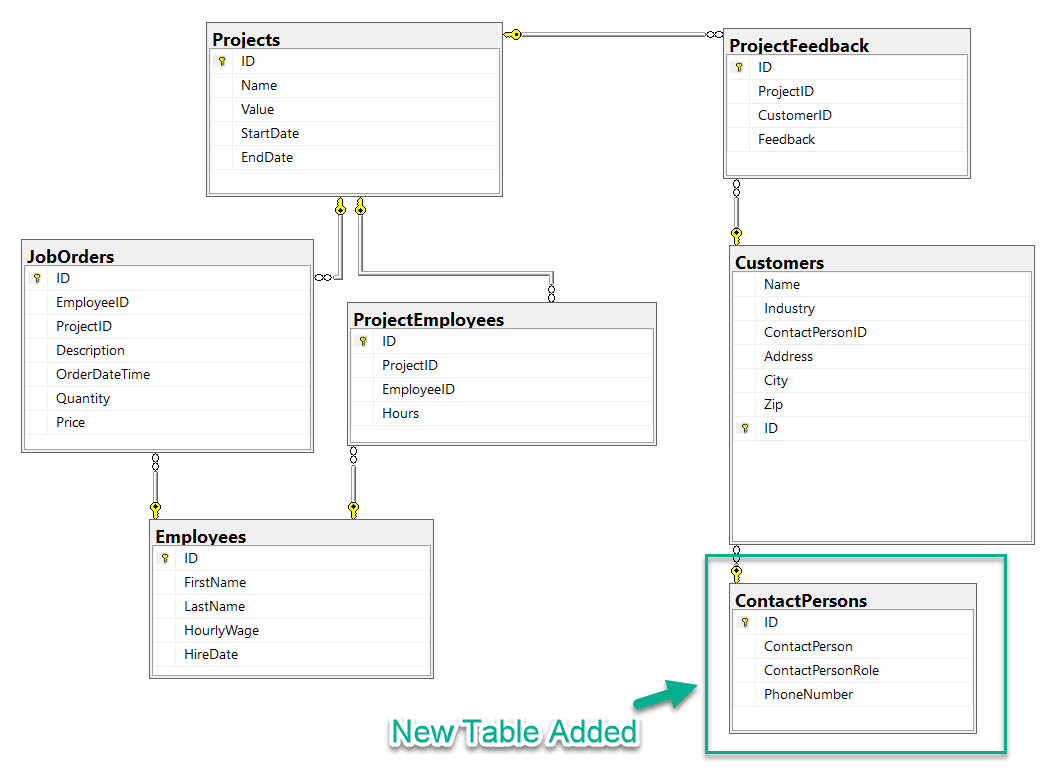
Now, if the contact person for customer changes, we just need to insert a record into the ContactPersons table and change the ContactPersonID in the Customers table.
Third Normal Form
To satisfy the conditions of the third normal form, all the rules of the second normal form must satisfy. And with that, we also need to ensure that each column must be non-transitively dependent on the primary key of the table. This means that all columns in a table should rely only on the primary key and no other column. If ColumnA relies on the primary key and also on the ColumnB, then ColumnA is known to be transitively dependent on the primary key and it violates the third normal form.
After applying 1NF and 2NF, below is what the Customers table looks like now ( Fig 5 ).

If you look carefully, there are transitive dependent columns in this table and it violates the 3NF. The transitive dependent relationship is between the columns - City and Zip . The city in which a customer is situated relates to the primary key of the customer, so this satisfies the second normal form. However, the city also depends on the zip code. If a customer changes its location, there may be a chance we update one column but not the other. Because of this relationship between the City and Zip , the database is not in 3NF.
In order to fix this and bring the table to satisfy the third normal form, we need to remove the City from the Customers table and create a new table ZipCodes to store the Zip and City . This new table can be related to the Customers table via a foreign key relation. The script is provided below.
Now that all the changes are performed, lets look at the schema after the third normal form has also been satisfied ( Fig 6 ). As you can see, the new table ZipCodes has been added and it relates to the Customers table.
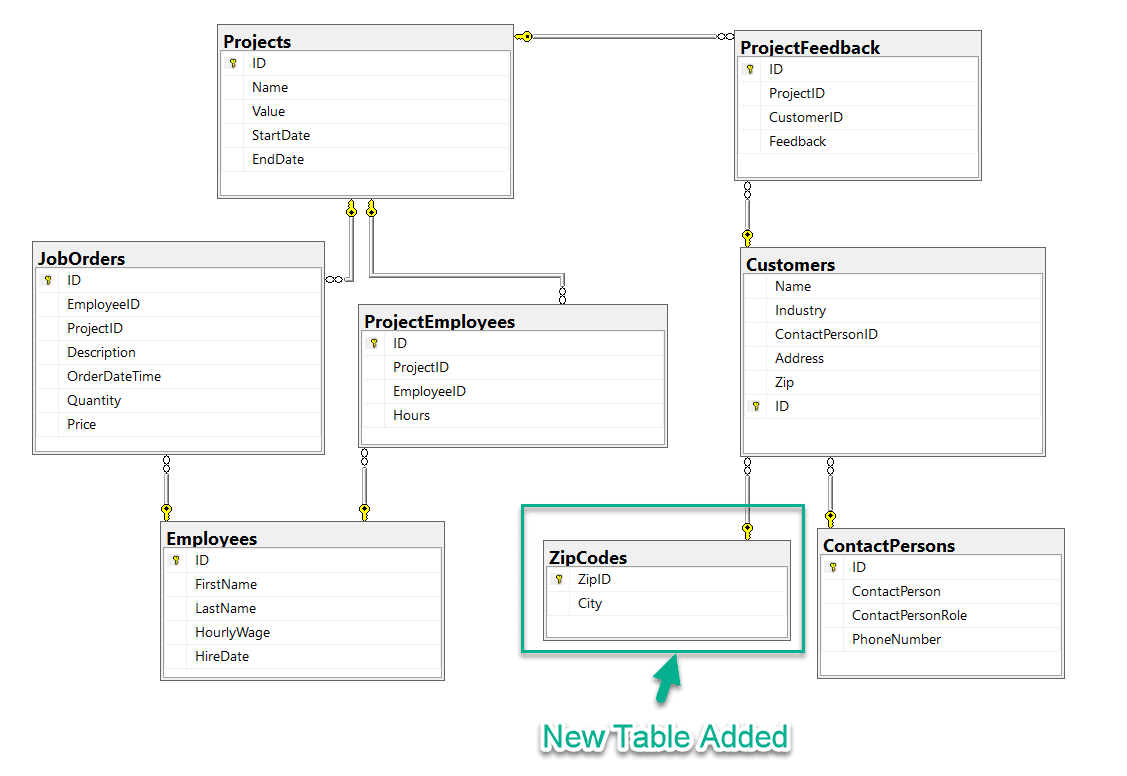
That's all for the third normal form. The Customers table now supports all the three normal forms and can be used as required. It is always tricky to find issues that are caused by a violation of the third normal form. However, for good database design, these are quite essential that all the normal forms are satisfied.
In this article, we have seen what is database normalization and how can we implement it in a SQL Server database. To learn more please follow the link below.
- Database normalization article from Microsoft
- Database Denormalization
Log in or register to rate
You rated this post 5 out of 5. Change rating
Join the discussion and add your comment
Related content
Mean median mode using sql and dax.
- by gourishankar
- SQLServerCentral
This article explains how to calculate the important statistical functions, MEAN, MEDIAN, and MODE, in both T-SQL and DAX.
You rated this post out of 5. Change rating
31,099 reads
Implementing Date Calculations in SQL
- Datetime Functions
This article explains a way to use labels (last year, YTD, etc.) for report parameters.
6,657 reads
Introduction to STRING_SPLIT function in SQL
- split string
- String Functions
This article explains the T-SQL function STRING_SPLIT() and demonstrates a creative use for it.
9,771 reads
Handling Aggregations on a Poorly Designed Database
When the database design is not great, you may have to write some creative queries to get what you need.
3,429 reads
Introduction to PIVOT operator in SQL
- pivot table
Learn how to use the PIVOT operator in SQL in a step-by-step manner.
4.83 ( 12 )
12,898 reads
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 12 Normalization
Adrienne Watt
Normalization should be part of the database design process. However, it is difficult to separate the normalization process from the ER modelling process so the two techniques should be used concurrently.
Use an entity relation diagram (ERD) to provide the big picture, or macro view, of an organization’s data requirements and operations. This is created through an iterative process that involves identifying relevant entities, their attributes and their relationships.
Normalization procedure focuses on characteristics of specific entities and represents the micro view of entities within the ERD.
What Is Normalization?
Normalization is the branch of relational theory that provides design insights. It is the process of determining how much redundancy exists in a table. The goals of normalization are to:
- Be able to characterize the level of redundancy in a relational schema
- Provide mechanisms for transforming schemas in order to remove redundancy
Normalization theory draws heavily on the theory of functional dependencies. Normalization theory defines six normal forms (NF). Each normal form involves a set of dependency properties that a schema must satisfy and each normal form gives guarantees about the presence and/or absence of update anomalies. This means that higher normal forms have less redundancy, and as a result, fewer update problems.
Normal Forms
All the tables in any database can be in one of the normal forms we will discuss next. Ideally we only want minimal redundancy for PK to FK. Everything else should be derived from other tables. There are six normal forms, but we will only look at the first four, which are:
- First normal form (1NF)
- Second normal form (2NF)
- Third normal form (3NF)
- Boyce-Codd normal form (BCNF)
BCNF is rarely used.
First Normal Form (1NF)
In the first normal form , only single values are permitted at the intersection of each row and column; hence, there are no repeating groups.
To normalize a relation that contains a repeating group, remove the repeating group and form two new relations.
The PK of the new relation is a combination of the PK of the original relation plus an attribute from the newly created relation for unique identification.
Process for 1NF
We will use the Student_Grade_Repor t table below , from a School database, as our example to explain the process for 1NF.
- In the Student Grade Report table, the repeating group is the course information. A student can take many courses.
- Remove the repeating group. In this case, it’s the course information for each student.
- Identify the PK for your new table.
- The PK must uniquely identify the attribute value (StudentNo and CourseNo).
- After removing all the attributes related to the course and student, you are left with the student course table ( StudentCourse ).
- The Student table ( Student ) is now in first normal form with the repeating group removed.
- The two new tables are shown below.
How to update 1NF anomalies
StudentCourse ( StudentNo, CourseNo , CourseName, InstructorNo, InstructorName, InstructorLocation, Grade)
- To add a new course, we need a student.
- When course information needs to be updated, we may have inconsistencies.
- To delete a student, we might also delete critical information about a course.
Second Normal Form (2NF)
For the second normal form , the relation must first be in 1NF. The relation is automatically in 2NF if, and only if, the PK comprises a single attribute.
If the relation has a composite PK, then each non-key attribute must be fully dependent on the entire PK and not on a subset of the PK (i.e., there must be no partial dependency or augmentation).
Process for 2NF
To move to 2NF, a table must first be in 1NF.
- The Student table is already in 2NF because it has a single-column PK.
- When examining the Student Course table, we see that not all the attributes are fully dependent on the PK; specifically, all course information. The only attribute that is fully dependent is grade.
- Identify the new table that contains the course information.
- Identify the PK for the new table.
- The three new tables are shown below.
How to update 2NF anomalies
- When adding a new instructor, we need a course.
- Updating course information could lead to inconsistencies for instructor information.
- Deleting a course may also delete instructor information.
Third Normal Form (3NF)
To be in third normal form , the relation must be in second normal form. Also all transitive dependencies must be removed; a non-key attribute may not be functionally dependent on another non-key attribute.
Process for 3NF
- Eliminate all dependent attributes in transitive relationship(s) from each of the tables that have a transitive relationship.
- Create new table(s) with removed dependency.
- Check new table(s) as well as table(s) modified to make sure that each table has a determinant and that no table contains inappropriate dependencies.
- See the four new tables below.
At this stage, there should be no anomalies in third normal form. Let’s look at the dependency diagram (Figure 12.1) for this example. The first step is to remove repeating groups, as discussed above.
Student (StudentNo, StudentName, Major)
StudentCourse (StudentNo, CourseNo, CourseName, InstructorNo, InstructorName, InstructorLocation, Grade)
To recap the normalization process for the School database, review the dependencies shown in Figure 12.1.
The abbreviations used in Figure 12.1 are as follows:
- PD: partial dependency
- TD: transitive dependency
- FD: full dependency (Note: FD typically stands for functional dependency. Using FD as an abbreviation for full dependency is only used in Figure 12.1.)
Boyce-Codd Normal Form (BCNF)
When a table has more than one candidate key, anomalies may result even though the relation is in 3NF. Boyce-Codd normal form is a special case of 3NF. A relation is in BCNF if, and only if, every determinant is a candidate key.
BCNF Example 1
Consider the following table ( St_Maj_Adv ).
| 111 | Physics | Smith |
| 111 | Music | Chan |
| 320 | Math | Dobbs |
| 671 | Physics | White |
| 803 | Physics | Smith |
T he semantic rules (busines s rules applied to the database) for this table are:
- Each Student may major in several subjects.
- For each Major, a given Student has only one Advisor.
- Each Major has several Advisors.
- Each Advisor advises only one Major.
- Each Advisor advises several Students in one Major.
The functional dependencies for this table are listed below. The first one is a candidate key; the second is not.
- Student_id, Major ——> Advisor
- Advisor ——> Major
Anomalies for this table include:
- Delete – student deletes advisor info
- Insert – a new advisor needs a student
- Update – inconsistencies
Note : No single attribute is a candidate key.
PK can be Student_id, Major or Student_id, Advisor .
To reduce the St_Maj_Adv relation to BCNF, you create two new tables:
- St_Adv ( Student_id, Advisor )
- Adv_Maj ( Advisor , Major)
St_Adv table
| 111 | Smith |
| 111 | Chan |
| 320 | Dobbs |
| 671 | White |
| 803 | Smith |
Adv_Maj table
| Smith | Physics |
| Chan | Music |
| Dobbs | Math |
| White | Physics |
BCNF Example 2
Consider the following table ( Client_Interview) .
| CR76 | 13-May-02 | 10.30 | SG5 | G101 |
| CR56 | 13-May-02 | 12.00 | SG5 | G101 |
| CR74 | 13-May-02 | 12.00 | SG37 | G102 |
| CR56 | 1-July-02 | 10.30 | SG5 | G102 |
FD1 – ClientNo, InterviewDate –> InterviewTime, StaffNo, RoomNo (PK)
FD2 – staffNo, interviewDate, interviewTime –> clientNO (candidate key: CK)
FD3 – roomNo, interviewDate, interviewTime –> staffNo, clientNo (CK)
FD4 – staffNo, interviewDate –> roomNo
A relation is in BCNF if, and only if, every determinant is a candidate key. We need to create a table that incorporates the first three FDs ( Client_Interview2 table) and another table ( StaffRoom table) for the fourth FD.
Client_Interview2 table
| CR76 | 13-May-02 | 10.30 | SG5 |
| CR56 | 13-May-02 | 12.00 | SG5 |
| CR74 | 13-May-02 | 12.00 | SG37 |
| CR56 | 1-July-02 | 10.30 | SG5 |
StaffRoom table
| SG5 | 13-May-02 | G101 |
| SG37 | 13-May-02 | G102 |
| SG5 | 1-July-02 | G102 |
Normalization and Database Design
During the normalization process of database design, make sure that proposed entities meet required normal form before table structures are created. Many real-world databases have been improperly designed or burdened with anomalies if improperly modified during the course of time. You may be asked to redesign and modify existing databases. This can be a large undertaking if the tables are not properly normalized.
Key Terms and Abbrevations
first normal form (1NF): only single values are permitted at the intersection of each row and column so there are no repeating groups
normalization : the process of determining how much redundancy exists in a table
second normal form (2NF) : the relation must be in 1NF and the PK comprises a single attribute
semantic rules : business rules applied to the database
Complete chapters 11 and 12 before doing these exercises.
- What is normalization?
- When is a table in 1NF?
- When is a table in 2NF?
- When is a table in 3NF?
- Using the dependency diagram you just drew, show the tables (in their third normal form) you would create to fix the problems you encountered. Draw the dependency diagram for the fixed table.
- This table is susceptible to update anomalies. Provide examples of insertion, deletion and update anomalies.
- Normalize this table to third normal form. State any assumptions.
- ____________________ produces a lower normal form.
- Any attribute whose value determines other values within a row is called a(n) ____________________.
- An attribute that cannot be further divided is said to display ____________________.
- ____________________ refers to the level of detail represented by the values stored in a table’s row.
- A relational table must not contain ____________________ groups.
Also see Appendix B: Sample ERD Exercises
Bibliography
Nguyen Kim Anh , Relational Design Theory . OpenStax CNX. 8 Jul 2009 Retrieved July 2014 from http://cnx.org/contents/606cc532-0b1d-419d-a0ec-ac4e2e2d533b@1@1
Russell, Gordon. Chapter 4 – Normalisation. Database eLearning . N.d. Retrived July 2014 from db.grussell.org/ch4.html
Database Design - 2nd Edition Copyright © 2014 by Adrienne Watt is licensed under a Creative Commons Attribution 4.0 International License , except where otherwise noted.
Share This Book
What is Data Science? A Beginner’s Guide
Advanced file handling in python: working with csv, json, and xml, building python cli applications: a step-by-step tutorial, 5 tips for writing efficient python code for data analysis.

Data Science Horizons
Navigating the Data Frontier: Explore the World of Data Science Today

Why Normalization Matters in Data Science

Large Language Model Crash Course for Data Scientists
- Data Engineering
Database Normalization: A Practical Guide
Introduction
Database normalization is the process of organizing data in a database to reduce data redundancy and improve data integrity. This practical guide covers the basics of normalization, including the different normal forms such as 1NF, 2NF, and 3NF, and provides examples of unnormalized and normalized databases. It also explains how normalization helps eliminate modification anomalies and covers denormalization and when it may be useful despite the reduction in normalization. The history, evolution, practical applications, and some modern considerations of database normalization are also explored.
Database normalization is an important concept for database and application developers to understand. Normalization helps organize data efficiently, eliminate data redundancy, and ensure data integrity. By following proper normalization techniques, developers can build robust and maintainable databases and applications. The origins of normalization can be traced back to the 1970s, and it has evolved to address the burgeoning data demands of modern applications.
Goals and Benefits of Normalization
The primary goals of normalization are to:
Some key benefits include:
Normal Forms and Normalization Levels
Normalization organizes data by progressive levels called normal forms. Each level builds on the previous one, providing more structure and constraints.
First Normal Form (1NF)
Second normal form (2nf), third normal form (3nf).
Higher normal forms exist, like Boyce-Codd Normal Form, which addresses certain specific scenarios beyond 3NF. However, most databases only normalize to 3NF.
Anomalies Explained
Anomalies refer to inconsistencies that can occur during data modification. Insertion anomalies happen when certain information cannot be inserted without other information. Deletion anomalies occur when deleting data inadvertently removes other valuable data. Update anomalies are inconsistencies that occur when data is changed or updated. Normalization helps to eliminate these potential pitfalls.
Examples of Normalization
Let’s look at some examples to illustrate how normalization transforms an unstructured design into a well-structured normalized database. Practical scenarios from various industries can also shed light on how these principles are applied in real-world contexts.
Unnormalized Form
Here is an unnormalized table storing book and author data:
Book ID | Title | Author Name | Author Birthplace ———————————————– 1 | SQL Basics | John Doe | Boston 2 | DB Design | Jane Smith | Chicago 3 | SQL Queries | John Doe | Boston
This unnormalized table displays data redundancy – John Doe’s name and birthplace are repeated. It also has multiple entity types in one table, storing both book and author details.
First Normal Form (1NF) To satisfy 1NF, we’ll split this into two tables – Books and Authors. Each table has its own primary key and contains related data only.
Books ————- BookID | Title ————- 1 | SQL Basics 2 | DB Design 3 | SQL Queries
Authors ————- AuthorID | Name | Birthplace ————- 1 | John Doe | Boston 2 | Jane Smith | Chicago
To demonstrate 2NF, consider a scenario where a composite primary key exists. In that case, all non-key attributes should fully depend on the entire composite key, without partial dependencies.
No table has transitive dependencies, so the database satisfies 3NF. This well-structured normalized design eliminates data anomalies and redundancies.
When to Denormalize
In some cases, controlled denormalization – intentionally reducing normalization for performance gains – may be beneficial despite the risks.
Denormalization can optimize read performance since joins are avoided. It may help simple parallel processing and replication. Fewer tables and foreign keys can mean faster writes.
However, denormalization leads to data repetition and all the drawbacks that normalization aims to solve. It increases anomaly risks and data integrity issues.
Denormalization requires careful analysis and should only be used sparingly when the performance gains outweigh increased maintenance and data integrity risks.

Tools and Technologies
In the world of database management, various tools and technologies play a crucial role in facilitating the normalization process. Entity-Relationship (ER) modeling tools, for example, provide a visual way to design the structure of a database, allowing for a clear depiction of entities, attributes, and relationships. This graphical representation helps database designers understand the inherent structure of the data and identify opportunities for normalization.
Database Management Systems (DBMS) also play a vital role in enforcing normalization principles. Modern DBMSs often come with built-in features and functions that guide the design process, ensuring that the database adheres to the desired normal form. These systems provide validation checks, constraint enforcement, and other mechanisms to prevent violations of normalization rules.
Moreover, specialized tools and libraries are available to assist with various aspects of normalization. These tools can automate some of the tasks involved in normalizing a database, such as identifying functional dependencies or suggesting table partitions. By leveraging these technologies, database designers can more efficiently create and maintain well-structured, normalized databases.
The utilization of these tools and technologies not only streamlines the normalization process but also helps ensure that the resulting database design is robust, maintainable, and aligned with best practices. They serve as essential aids in the complex task of organizing data optimally, contributing to the overall success of database management efforts.
Challenges and Common Mistakes
Database normalization is a nuanced and often complex process that requires careful planning and execution. One common challenge faced by database designers is over-normalization. While normalization aims to eliminate redundancy and increase integrity, taking it to an extreme can result in excessive complexity. Over-normalized databases can lead to a large number of tables with intricate relationships, making queries and maintenance more challenging.
Under-normalization, on the other hand, can lead to redundancy and inconsistency. If normalization principles are not adequately applied, the resulting design may contain duplicated data, leading to potential inconsistencies and increased storage requirements. Striking the right balance between over- and under-normalization is a delicate task that requires a deep understanding of the data and its intended use.
Another common mistake is neglecting to consider the specific needs of the application or system using the database. Normalization decisions should align with the anticipated query patterns and performance requirements. A design that is theoretically well-normalized but misaligned with the actual usage patterns can lead to suboptimal performance.
Additionally, the evolving nature of data and business requirements can introduce challenges in maintaining a normalized design over time. Continuous monitoring, periodic reviews, and adaptability are essential in ensuring that the database structure remains effective and aligned with current needs.
Awareness of these common challenges and mistakes, coupled with thoughtful planning and ongoing attention to the unique characteristics of the data and system, can guide a more effective and successful normalization process.
Impact on Modern Databases
The advent of modern database systems, including NoSQL databases, has brought new dimensions to the concept of normalization. While traditional relational databases rely heavily on normalization principles, NoSQL databases often approach data organization differently.
In NoSQL databases, the emphasis may be more on horizontal scalability and flexible schema design. Normalization principles that apply strictly in a relational context may not be directly transferable to NoSQL environments. For example, denormalization might be more commonly used in NoSQL databases to optimize read performance, even at the cost of some redundancy.
Furthermore, the diverse types of NoSQL databases, such as document-based, column-family, or graph databases, introduce different considerations for data organization. The principles of normalization may be applied differently or adapted to suit the specific characteristics of these database models.
Understanding the impact of modern database systems on normalization requires a broader perspective that considers the varying needs and characteristics of different data storage paradigms. It involves recognizing that the principles of normalization are not one-size-fits-all but must be interpreted and applied in the context of the specific database technology and the unique requirements of the application.
The interplay between traditional normalization principles and the evolving landscape of modern database technologies offers a rich and complex field of study. It reflects the ongoing evolution of data management practices and the need for database professionals to adapt and innovate in the face of changing technologies and demands.
Database normalization remains a vital strategy in contemporary database management. Whether you are a seasoned database administrator, a software engineer, or someone starting to explore the world of databases, understanding and leveraging database normalization can lead to a more efficient and scalable data management system. This comprehensive guide serves as a valuable resource for mastering this essential aspect of modern database management.
Share this:
Related news.

Understanding Data Pipelines: Design and Implementation

Building Scalable and Maintainable REST APIs for Data Services

Understanding Data Sharding

An Overview of Data Virtualization
Tutorial Playlist
Sql tutorial for beginners, the complete guide to know advanced sql, the finest guide to master sql with python, er diagrams in dbms: entity relationship diagram model.
What Is SQL Injection: How to Prevent SQL Injection
Learn PostgreSQL From Scratch
The ultimate guide to normalization in sql, triggers in sql: your ultimate guide to how they work and why they matter, what is normalization in sql 1nf, 2nf, 3nf and bcnf in dbms.
Lesson 6 of 7 By Ravikiran A S

Table of Contents
As an SQL Developer, you often work with enormous amounts of data stored in different tables that are present inside multiple databases . It often becomes strenuous to extract the data if it is not organized correctly. Using Normalization, you can solve the problem of data redundancy and organize the data using different forms. This tutorial will help you get to know the concept of Normalization in SQL.
In this tutorial, you will learn the following topics:
- What is Normalization in SQL?
- First Normal Form
- Second Normal Form
- Third Normal Form
- Boyce Codd Normal Form
Want a Top Software Development Job? Start Here!
What Is Normalization in SQL?
Normalization is the process to eliminate data redundancy and enhance data integrity in the table. Normalization also helps to organize the data in the database. It is a multi-step process that sets the data into tabular form and removes the duplicated data from the relational tables.
Normalization organizes the columns and tables of a database to ensure that database integrity constraints properly execute their dependencies. It is a systematic technique of decomposing tables to eliminate data redundancy (repetition) and undesirable characteristics like Insertion, Update, and Deletion anomalies.
Also Read: The Ultimate Guide on SQL Basics
In 1970 Edgar F. Codd defined the First Normal Form.
Now let's understand the types of Normal forms with the help of examples.

1st Normal Form (1NF)
- A table is referred to as being in its First Normal Form if atomicity of the table is 1.
- Here, atomicity states that a single cell cannot hold multiple values. It must hold only a single-valued attribute.
- The First normal form disallows the multi-valued attribute, composite attribute, and their combinations.
Now you will understand the First Normal Form with the help of an example.
Below is a students’ record table that has information about student roll number, student name, student course, and age of the student.

In the studentsrecord table, you can see that the course column has two values. Thus it does not follow the First Normal Form. Now, if you use the First Normal Form to the above table, you get the below table as a result.

By applying the First Normal Form, you achieve atomicity, and also every column has unique values.
Before proceeding with the Second Normal Form, get familiar with Candidate Key and Super Key.
Candidate Key
A candidate key is a set of one or more columns that can identify a record uniquely in a table, and YOU can use each candidate key as a Primary Key.
Now, let’s use an example to understand this better.

Super key is a set of over one key that can identify a record uniquely in a table, and the Primary Key is a subset of Super Key.
Let’s understand this with the help of an example.

Second Normal Form (2NF)
The first condition for the table to be in Second Normal Form is that the table has to be in First Normal Form. The table should not possess partial dependency. The partial dependency here means the proper subset of the candidate key should give a non-prime attribute.
Now understand the Second Normal Form with the help of an example.
Consider the table Location:

The Location table possesses a composite primary key cust_id, storeid. The non-key attribute is store_location. In this case, store_location only depends on storeid, which is a part of the primary key. Hence, this table does not fulfill the second normal form.
To bring the table to Second Normal Form, you need to split the table into two parts. This will give you the below tables:

As you have removed the partial functional dependency from the location table, the column store_location entirely depends on the primary key of that table, storeid.
Now that you understood the 1st and 2nd Normal forms, you will look at the next part of this Normalization in SQL tutorial.
Third Normal Form (3NF)
- The first condition for the table to be in Third Normal Form is that the table should be in the Second Normal Form.
- The second condition is that there should be no transitive dependency for non-prime attributes, which indicates that non-prime attributes (which are not a part of the candidate key) should not depend on other non-prime attributes in a table. Therefore, a transitive dependency is a functional dependency in which A → C (A determines C) indirectly, because of A → B and B → C (where it is not the case that B → A).
- The third Normal Form ensures the reduction of data duplication. It is also used to achieve data integrity.
Below is a student table that has student id, student name, subject id, subject name, and address of the student as its columns.

In the above student table, stu_id determines subid, and subid determines sub. Therefore, stu_id determines sub via subid. This implies that the table possesses a transitive functional dependency, and it does not fulfill the third normal form criteria.
Now to change the table to the third normal form, you need to divide the table as shown below:

As you can see in both the tables, all the non-key attributes are now fully functional, dependent only on the primary key. In the first table, columns name, subid, and addresses only depend on stu_id. In the second table, the sub only depends on subid.
Preparing Your Blockchain Career for 2024
Boyce CoddNormal Form (BCNF)
Boyce Codd Normal Form is also known as 3.5 NF. It is the superior version of 3NF and was developed by Raymond F. Boyce and Edgar F. Codd to tackle certain types of anomalies which were not resolved with 3NF.
The first condition for the table to be in Boyce Codd Normal Form is that the table should be in the third normal form. Secondly, every Right-Hand Side (RHS) attribute of the functional dependencies should depend on the super key of that particular table.
For example :
You have a functional dependency X → Y. In the particular functional dependency, X has to be the part of the super key of the provided table.
Consider the below subject table:

The subject table follows these conditions:
- Each student can enroll in multiple subjects.
- Multiple professors can teach a particular subject.
- For each subject, it assigns a professor to the student.
In the above table, student_id and subject together form the primary key because using student_id and subject; you can determine all the table columns.
Another important point to be noted here is that one professor teaches only one subject, but one subject may have two professors.
Which exhibit there is a dependency between subject and professor, i.e. subject depends on the professor's name.
The table is in 1st Normal form as all the column names are unique, all values are atomic, and all the values stored in a particular column are of the same domain.
The table also satisfies the 2nd Normal Form, as there is no Partial Dependency.
And, there is no Transitive Dependency; hence, the table also satisfies the 3rd Normal Form.
This table follows all the Normal forms except the Boyce Codd Normal Form.
As you can see stuid, and subject forms the primary key, which means the subject attribute is a prime attribute.
However, there exists yet another dependency - professor → subject.
BCNF does not follow in the table as a subject is a prime attribute, the professor is a non-prime attribute.
To transform the table into the BCNF, you will divide the table into two parts. One table will hold stuid which already exists and the second table will hold a newly created column profid.

And in the second table will have the columns profid, subject, and professor, which satisfies the BCNF.

With this, you have reached the conclusion of the ‘Normalization in SQL’ tutorial.
Start Your Journey to Data Mastery
In this tutorial, you have seen Normalization in SQL and understood the different Normal forms of Normalization. Now, you can organize the data in the database and remove the data redundancy and promote data integrity. This tutorial also helps beginners for their interview processes to understand the concept of Normalization in SQL.
If you have any questions or inputs for our editorial team regarding this “The Supreme Guide to Normalization in SQL” tutorial, do share them in the comments section below. Our team will review them and help solve them for you very soon!
If you are looking to enhance your skills further, we would highly recommend yo to check Simplilearn's Full Stack Java Developer Career Bootcamp . This course can help you hone the right skills and make you career-ready in no time.
Happy learning!
About the Author
Ravikiran A S works with Simplilearn as a Research Analyst. He an enthusiastic geek always in the hunt to learn the latest technologies. He is proficient with Java Programming Language, Big Data, and powerful Big Data Frameworks like Apache Hadoop and Apache Spark.
Recommended Resources
A Guide on How to Become a Site Reliability Engineer (SRE)
SQL UNION: The Best Way to Combine SQL Queries
Full Stack Java Development: A 2024 Blueprint for Recession-Proofing Your Career
Managing Data
- PMP, PMI, PMBOK, CAPM, PgMP, PfMP, ACP, PBA, RMP, SP, and OPM3 are registered marks of the Project Management Institute, Inc.
Software Testing Help
Database Normalization Tutorial: 1NF 2NF 3NF BCNF Examples

This Tutorial will Explain what is Database Normalization and various Normal Forms like 1NF 2NF 3NF and BCNF With SQL Code Examples:
Database Normalization is a well-known technique used for designing database schema.
The main purpose of applying the normalization technique is to reduce the redundancy and dependency of data. Normalization helps us to break down large tables into multiple small tables by defining a logical relationship between those tables.
=> Click here for the complete MySQL tutorial series

Table of Contents:
Advantages Of DBMS Normalization
Disadvantages of database normalization, types of normal forms, frequently asked questions and answers, was this helpful, recommended reading, what is database normalization.
Database normalization or SQL normalization helps us to group related data in one single table. Any attributive data or indirectly related data are put in different tables and these tables are connected with a logical relationship between parent and child tables.
In 1970, Edgar F. Codd came up with the concept of normalization. He shared a paper named “A Relational Model of Data for Large Shared Banks” in which he proposed “First Normal Form (1NF)”.
Database Normalization provides the following basic advantages:
- Normalization increases data consistency as it avoids the duplicity of data by storing the data in one place only.
- Normalization helps in grouping like or related data under the same schema, thereby resulting in the better grouping of data.
- Normalization improves searching faster as indexes can be created faster. Hence, the normalized database or table is used for OLTP (Online Transaction Processing).
DBMS Normalization has the following disadvantages:
- We cannot find the associated data for, say a product or employee in one place and we have to join more than one table. This causes a delay in retrieving the data.
- Thus, Normalization is not a good option in OLAP transactions (Online Analytical Processing).
Before we proceed further, let’s understand the following terms:
- Entity: Entity is a real-life object, where the data associated with such an object is stored in the table. The example of such objects are employees, departments, students, etc.
- Attributes: Attributes are the characteristics of the entity, that give some information about the Entity. For Example, if tables are entities, then the columns are their attributes.
#1) 1NF (First Normal Form)
By definition, an entity that does not have any repeating columns or data groups can be termed as the First Normal Form. In the First Normal Form, every column is unique.
Following is how our Employees and Department table would have looked if in first normal form (1NF):
| 1001 | Andrews | Jack | Accounts | New York | United States |
| 1002 | Schwatz | Mike | Technology | New York | United States |
| 1009 | Beker | Harry | HR | Berlin | Germany |
| 1007 | Harvey | Parker | Admin | London | United Kingdom |
| 1007 | Harvey | Parker | HR | London | United Kingdom |
Here, all the columns of both Employees and Department tables have been clubbed into one and there is no need of connecting columns, like deptNum, as all data is available in one place.
But a table like this with all the required columns in it, would not only be difficult to manage but also difficult to perform operations on and also inefficient from the storage point of view.
#2) 2NF (Second Normal Form)
By definition, an entity that is 1NF and one of its attributes is defined as the primary key and the remaining attributes are dependent on the primary key.
Following is an example of how the employees and department table would look like:
Employees Table:
| 1001 | Andrews | Jack |
| 1002 | Schwatz | Mike |
| 1009 | Beker | Harry |
| 1007 | Harvey | Parker |
| 1007 | Harvey | Parker |
Departments Table:
| 1 | Accounts | New York | United States |
| 2 | Technology | New York | United States |
| 3 | HR | Berlin | Germany |
| 4 | Admin | London | United Kingdom |
EmpDept Table:
| 1 | 1001 | 1 |
| 2 | 1002 | 2 |
| 3 | 1009 | 3 |
| 4 | 1007 | 4 |
| 5 | 1007 | 3 |
Here, we can observe that we have split the table in 1NF form into three different tables. the Employees table is an entity about all the employees of a company and its attributes describe the properties of each employee. The primary key for this table is empNum.
Similarly, the Departments table is an entity about all the departments in a company and its attributes describe the properties of each department. The primary key for this table is the deptNum.
In the third table, we have combined the primary keys of both the tables. The primary keys of the Employees and Departments tables are referred to as Foreign keys in this third table.
If the user wants an output similar to the one, we had in 1NF, then the user has to join all the three tables, using the primary keys.
A sample query would look as shown below:
#3) 3NF (Third Normal Form)
By definition, a table is considered in third normal if the table/entity is already in the second normal form and the columns of the table/entity are non-transitively dependent on the primary key.
Let’s understand non-transitive dependency, with the help of the following example.
Say a table named, Customer has the below columns:
CustomerID – Primary Key identifying a unique customer CustomerZIP – ZIP Code of the locality customer resides in CustomerCity – City the customer resides in
In the above case, the CustomerCity column is dependent on the CustomerZIP column and the CustomerZIP column is dependent on CustomerID.
The above scenario is called transitive dependency of the CustomerCity column on the CustomerID i.e. the primary key. After understanding transitive dependency, now let’s discuss the problem with this dependency.
There could be a possible scenario where an unwanted update is made to the table for updating the CustomerZIP to a zipcode of a different city without updating the CustomerCity, thereby leaving the database in an inconsistent state.
In order to fix this issue, we need to remove the transitive dependency that could be done by creating another table, say, CustZIP table that holds two columns i.e. CustomerZIP (as Primary Key) and CustomerCity.
The CustomerZIP column in the Customer table is a foreign key to the CustomerZIP in the CustZIP table. This relationship ensures that there is no anomaly in the updates wherein a CustomerZIP is updated without making changes to the CustomerCity.
#4) Boyce-Codd Normal Form (3.5 Normal Form)
By definition, the table is considered Boyce-Codd Normal Form, if it’s already in the Third Normal Form and for every functional dependency between A and B, A should be a super key.
This definition sounds a bit complicated. Let’s try to break it to understand it better.
- Functional Dependency: The attributes or columns of a table are said to be functionally dependent when an attribute or column of a table uniquely identifies another attribute(s) or column(s) of the same table. For Example, the empNum or Employee Number column uniquely identifies the other columns like Employee Name, Employee Salary, etc. in the Employee table.
- Super Key: A single key or group of multiple keys that could uniquely identify a single row in a table can be termed as Super Key. In general terms, we know such keys as Composite Keys.
Let’s consider the following scenario to understand when there is a problem with Third Normal Form and how does Boyce-Codd Normal Form comes to rescue.
| 1001 | Jack | New York | Accounts | Raymond |
| 1001 | Jack | New York | Technology | Donald |
| 1002 | Harry | Berlin | Accounts | Samara |
| 1007 | Parker | London | HR | Elizabeth |
| 1007 | Parker | London | Infrastructure | Tom |
In the above example, employees with empNum 1001 and 1007 work in two different departments. Each department has a department head. There can be multiple department heads for each department. Like for the Accounts department, Raymond and Samara are the two heads of departments.
In this case, empNum and deptName are super keys, which implies that deptName is a prime attribute. Based on these two columns, we can identify every single row uniquely.
Also, the deptName depends on deptHead, which implies that deptHead is a non-prime attribute. This criterion disqualifies the table from being part of BCNF.
To solve this we will break the table into three different tables as mentioned below:
| 1001 | Jack | New York | D1 |
| 1001 | Jack | New York | D2 |
| 1002 | Harry | Berlin | D1 |
| 1007 | Parker | London | D3 |
| 1007 | Parker | London | D4 |
Department Table:
| D1 | Accounts | Raymond |
| D2 | Technology | Donald |
| D1 | Accounts | Samara |
| D3 | HR | Elizabeth |
| D4 | Infrastructure | Tom |
#5) Fourth Normal Form (4 Normal Form)
By definition, a table is in Fourth Normal Form, if it does not have two or more, independent data describing the relevant entity.
#6) Fifth Normal Form (5 Normal Form)
A table can be considered in Fifth Normal Form only if it satisfies the conditions for Fourth Normal Form and can be broken down into multiple tables without loss of any data.
Q #1) What is Normalization in a Database?
Answer: Database Normalization is a design technique. Using this we can design or re-design schemas in the database to reduce redundant data and the dependency of data by breaking the data into smaller and more relevant tables.
Q #2) What are the different types of Normalization?
Answer: Following are the different types of normalization techniques that can be employed to design database schemas:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce-Codd Normal Form (3.5NF)
- Fourth Normal Form (4NF)
- Fifth Normal Form (5NF)
Q #3) What is the Purpose of Normalization?
Answer: The primary purpose of the normalization is to reduce the data redundancy i.e. the data should only be stored once. This is to avoid any data anomalies that could arise when we attempt to store the same data in two different tables, but changes are applied only to one and not to the other.
Q #4) What is Denormalization?
Answer: Denormalization is a technique to increase the performance of the database. This technique adds redundant data to the database, contrary to the normalized database that removes the redundancy of the data.
This is done in huge databases where executing a JOIN to get data from multiple tables is an expensive affair. Thus, redundant data are stored in multiple tables to avoid JOIN operations.
So far, we have all gone through three database normalization forms.
Theoretically, there are higher forms of database normalizations like Boyce-Codd Normal Form, 4NF, 5NF. However, 3NF is the widely used normalization form in the production databases.
- Database Testing With JMeter
- MongoDB Create Database Backup
- MongoDB Create Database Tutorial
- Top 10 Database Design Tools to Build Complex Data Models
- MongoDB Performance: Locking Performance, Page Faults and Database Profiling
- Altibase Open Source Relational Database Review
- MongoDB Database Profiler for Monitoring Queries and Performance
- How to Test Oracle Database
Leave a Comment Cancel reply
Let's Define DBMS
Database Normalization: Explain 1NF, 2NF, 3NF, BCNF With Examples
Database Normalization: Explain 1NF, 2NF, 3NF, BCNF With Examples + PDF : The purpose of normalization is to make the life of users easier and also to save space on computers while storing huge amounts of data. The added advantage of getting an organized package of data that helps in a performance boost is also a very notable use of normalization. This discussion is all about Database Normalization: Explain 1NF, 2NF, 3NF, BCNF With Examples. At the end of this article, you will be given a free pdf copy of all these Normalization forms. Normalization can be mainly classified into 4 types:
1) 1 st Normal Form.
2) 2 nd Normal Form.
3) 3 rd Normal Form.
4) 4 th Normal Form.
5) 5 th Normal Form, and
6) Boyce- Codd Normal Form.
Database Normalization: Explain 1NF, 2NF, 3NF, BCNF With Examples + PDF
The discussion here includes the 1 st , 2 nd , 3 rd and 4 th Normal Forms.
FIRST NORMAL FORM
It is a property of a relation in a relational database wherein only when the domain of each attribute has only atomic values (values that cannot be divided or simplified further) and the value of each attribute has only one value from the selected domain. Edgar Codd, an English Computer Scientist, stated that a relation is said to be in the first normal form when none of its domains have any sets as elements. This form is a very important relation in RDBMS . It enforces several criteria including: 1) Removing repeating groups in individual tables, 2) Creating separate tables for every set of related data and 3) Identifying related data using the primary key of a given set.
Also See: Seminar Topics
Consider a table containing the details of a company. The fields to be included are employee name, employee ID no, employee location and employee contact no. For better understanding, this will be displayed in a table form.

In the above table, we can see the employee details of a certain company. All rows have values as shown but we can see that the values in the first two rows under the column ‘EMPLOYEE CONTACT NO’ have multiple values. Employees AJAY and AMIT have multiple contact numbers which cannot be accepted in the first normal form. It brings ambiguity to the database and can generate anomalies. Hence the need arises to maintain the uniqueness of the field. In order to bring it to the first normal form, one of the values from the field of employee contact no should be removed (from both Ajay and Amit’s data). So the correct first normal form will be obtained upon editing in such a manner. The correct table will be:

The correct table complies with the first normal form criteria i.e., “each attribute of a table must have atomic values”. The extra contact numbers were removed to obtain the required form design.
WHAT IS ATOMICITY IN DATABASE?
A definition of first normal form makes reference to the concept of ‘atomicity’. It states that the domain should have values in the relation which are impossible to be broken down into smaller contents of data, with respect to DBMS. Codd defines an atomic value as one that “cannot be decomposed into smaller pieces.
SECOND NORMAL FORM (2NF)
An entity is said to be in the second normal form when it is already in 1NF and all the attributes contained within it are dependent solely on the unique identifier of the entity. In other words, it maintains two important criteria to be met in order to provide a normalized data with the second normal form tag.
1) It is in the first normal form
2) All non-key attributes are fully functional and dependent on the primary key.
To give more clarity to the statements said above, consider a table and two attributes within the table, A and B. Suppose attribute B is functionally dependent on A, but is not on a proper subset of A. Then B can be considered to be fully functional and dependent on A. Therefore in a 2NF table, all of the non-key attributes cannot be dependent on the primary key’s subset. A table that is in 1st normal form and contains only a single key as the primary key is automatically in 2nd normal form.
Consider a toy shop that has three branches in three different locations. A table is prepared indicating the customer IDs, store IDs and store location.

The above table is a composite one and has a composite primary key (CUSTOMER ID, STORE ID). The non-key attribute in this arrangement is STORE LOCATION. In the above case, the STORE LOCATION only depends on the STORE ID, which is the sole part of the primary key. Hence the table does not satisfy the second normal form.

To resolve this issue and to convert the entity into the 2NF, the table is split into two separate tables. By splitting the table, the partial functional dependency is removed and atomicity is achieved for both the tables (thus realizing 1NF in the process). Now, the column STORE LOCATION is completely dependent on the primary key, the STORE ID thereby achieving 2NF for the table under consideration.
THIRD NORMAL FORM
An entity is said to be in the third normal form when,
1) It satisfies the criteria to be in the second normal form.
2) There exists no transitive functional dependency. (Transitive functional dependency can be best explained with the relationship link between three tables. If table A is functionally dependent on B, and B is functionally dependent on C then C is transitively dependent on A and B). It can also be said that the transitive functional dependency of non-prime attribute on any super key is removed. (A super key is a combined column system that is used to uniquely identify a row within any RDBMS. A super key is reduced to a minimum no of columns required to uniquely identify each row.)
3NF states that every column reference in referenced data which are not dependent on the primary key should be removed or that only foreign key columns should be used to reference another table, and no other columns from the parent table should exist in the referenced table.
Consider a table that shows the database of a bookstore. The table consists of details on Book ID, Genre ID, Book Genre and Price. The database is maintained to keep a record of all the books that are available or will be available in the bookstore. The table of data is given below.

The data in the table provides us with an idea of the books offered in the store. Also, we can deduce that BOOK ID determines the GENRE ID and the GENRE ID determines the BOOK GENRE. Hence we can see that a transitive functional dependency has developed which makes certain that the table does not satisfy the third normal form.

TABLE_GENRE

After splitting the tables and regrouping the redundant content, we obtain two tables where all non-key attributes are fully functional dependent only on the primary key.
To further explain the advanced step of the normalization process, we are required to understand the Boyce-Codd Normal Form and its comparison with the third normal form.
THE BOYCE-CODD NORMAL FORM AND RELATION WITH 3NF
The Boyce-Codd Normal Form or BCNF or 3.5 NF is a normal form which is slightly stronger than the 3NF. It was developed in 1974 to address certain types of anomalies that were not dealt by 3NF. A relational scheme, once prepared in BCNF, will remove all sorts of functional dependency (though some other forms of redundancy can prevail). Coming to the relation between BCNF AND 3NF, in certain rare cases, the 3NF table fails to meet the requirements of the BCNF. A 3NF table sans multiple overlapping candidate keys is guaranteed to be in BCNF and depending on the functional dependencies of the entity, a 3NF table that possesses two or more overlapping candidate keys may/may not be capable of being in BCNF.
Here is an example of a 3NF table that does not meet the demands of the BCNF:
The table shows the details of the booking schedule for a swimming pool complex with the fields of POOL NO, START TIME, END TIME and TYPE OF MEMBERSHIP. The details are filled in the rows and columns of the table below:

In the above table, no non-prime attributes exist which means that all attributes belong to some candidate key. This justifies the table being of 2NF and 3NF.However,the table does not follow BCNF because of the dependency of the type of membership in which the determining attribute,type of membership on which pool no: depends is neither a candidate key nor a superset of a candidate key. The design needs to be modified in order to conform to the BCNF. The significance of explaining the BCNF comes when the step of normalization is to be explained. The ‘Fourth Normal Form’ or 4NF
4. FOURTH NORMAL FORM
A normal form that is used in database normalization. The 4NF came at a significant time period as the next level of normalization. It was introduced by Ronald Fagin in 1977, after the Boyce-Codd Normal Form. The 4NF is basically concerned with a more general type of dependency known as a multivalued dependency and is different from 2NF, 3NF and BCNF and their functional dependencies. A table can be considered to be in 4NF only if for every one of the non-trivial multivalued dependencies, X->Y, when X is a super key. (This means that X is either a candidate key or a superset ).
Consider the table given below:

Here COURSE ID and INSTRUCTOR are multivalued dependent attributes. They can be converted to 4NF by separating the single table into two tables which are as given below
COURSE-INST

COURSE-TEXT

At the higher levels of normalization, the teaching and use of database normalization slows down substantially mostly because most of the tables are in direct violation of the 4NF. A table that satisfies 4NF is hard to come by most of the business applications. A study proves that, as of now, over 20% of business processes contains tables that violates 4NF but successfully meets all lower forms of normalization.
At 4NF, the performance reduces considerably and a further 5NF procedure may not be feasible as it causes great chances of error and very few tables practically satisfy the criteria to be of 5NF. The 5NF is also called the project-join normal form and is the highest level of normalization designed to reduce redundancy in relational databases which is done by recording multi-valued facts by isolating semantically related multiple relationships.
As we said that we will provide you a free pdf file of Database Normalization and all its forms 1NF, 2NF, 3NF, BCNF With Examples, so link to download this pdf file is given below.
Database Normalization 1NF, 2NF, 3NF, 4NF PDF File
So it was all about Database Normalization: Explain 1NF, 2NF, 3NF, BCNF With Examples. If you have any doubt then please comment below.
1 Comment Already

In the first normal form, you can not just remove one of the values in any multi valued attribute. You can make another entry and take a composite primary key which will be removed in further normalization.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
This site uses Akismet to reduce spam. Learn how your comment data is processed .
- Interview Q
DBMS Tutorial
Data modeling, relational data model, normalization, transaction processing, concurrency control, file organization, indexing and b+ tree, sql introduction.
Interview Questions

| A large database defined as a single relation may result in data duplication. This repetition of data may result in: So to handle these problems, we should analyze and decompose the relations with redundant data into smaller, simpler, and well-structured relations that are satisfy desirable properties. Normalization is a process of decomposing the relations into relations with fewer attributes. Why do we need Normalization? The main reason for normalizing the relations is removing these anomalies. Failure to eliminate anomalies leads to data redundancy and can cause data integrity and other problems as the database grows. Normalization consists of a series of guidelines that helps to guide you in creating a good database structure. Insertion Anomaly refers to when one cannot insert a new tuple into a relationship due to lack of data. The delete anomaly refers to the situation where the deletion of data results in the unintended loss of some other important data. The update anomaly is when an update of a single data value requires multiple rows of data to be updated. Normalization works through a series of stages called Normal forms. The normal forms apply to individual relations. The relation is said to be in particular normal form if it satisfies constraints.
| Description |
|---|---|
| A relation is in 1NF if it contains an atomic value. | |
| A relation will be in 2NF if it is in 1NF and all non-key attributes are fully functional dependent on the primary key. | |
| A relation will be in 3NF if it is in 2NF and no transition dependency exists. | |
| BCNF | A stronger definition of 3NF is known as Boyce Codd's normal form. |
| A relation will be in 4NF if it is in Boyce Codd's normal form and has no multi-valued dependency. | |
| A relation is in 5NF. If it is in 4NF and does not contain any join dependency, joining should be lossless. |
Advantages of Normalization
- Normalization helps to minimize data redundancy.
- Greater overall database organization.
- Data consistency within the database.
- Much more flexible database design.
- Enforces the concept of relational integrity.
Disadvantages of Normalization
- You cannot start building the database before knowing what the user needs.
- The performance degrades when normalizing the relations to higher normal forms, i.e., 4NF, 5NF.
- It is very time-consuming and difficult to normalize relations of a higher degree.
- Careless decomposition may lead to a bad database design, leading to serious problems.

- Send your Feedback to [email protected]
Help Others, Please Share

Learn Latest Tutorials

Transact-SQL

Reinforcement Learning

R Programming

React Native

Python Design Patterns

Python Pillow

Python Turtle

Preparation

Verbal Ability
Company Questions
Trending Technologies

Artificial Intelligence

Cloud Computing

Data Science

Machine Learning

B.Tech / MCA

Data Structures

Operating System

Computer Network

Compiler Design

Computer Organization

Discrete Mathematics

Ethical Hacking

Computer Graphics

Software Engineering

Web Technology

Cyber Security

C Programming

Control System

Data Mining

Data Warehouse

Database Concept
- Overview of DBMS
- Components of DBMS
- Database Architecture
- Types of Database Model
DBMS - ER Model
- ER Model: Basic Concepts
- ER Model: Creating ER Diagram
- ER Model: Generalization and Specialization
DBMS - Relational Model
- Codd's 12 rule of RDBMS
- Basic Concepts of RDBMS
- Relational Algebra
- Relational Calculus
- ER Model to Relational Model
- Types of Database Key
- Database Normalization
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce-Codd Normal Form (BCNF)
- Fourth Normal Form (4NF)
- Fifth Normal Form (5NF)
SQL Concept
- SQL Introduction
DDL Command
- Create query
- Alter query
- Truncate, Drop and Rename query
DML Command
- INSERT command
- UPDATE command
- DELETE command
TCL Command
- All TCL Command
DCL Command
- All DCL Command
- SELECT query
- WHERE clause
- LIKE clause
- ORDER BY clause
- Group BY clause
- Having clause
- DISTINCT keyword
- AND & OR operator
Advance SQL
- SQL Constraints
- SQL function
- SQL SET operation
- SQL Sequences
Normalization in DBMS
Normalization in DBMS is a technique using which you can organize the data in the database tables so that:
There is less repetition of data,
A large set of data is structured into a bunch of smaller tables,
and the tables have a proper relationship between them.
DBMS Normalization is a systematic approach to decompose (break down) tables to eliminate data redundancy(repetition) and undesirable characteristics like Insertion anomaly in DBMS, Update anomaly in DBMS, and Delete anomaly in DBMS.
It is a multi-step process that puts data into tabular form, removes duplicate data, and set up the relationship between tables.
Why we need Normalization in DBMS?
Normalization is required for,
Eliminating redundant(useless) data, therefore handling data integrity , because if data is repeated it increases the chances of inconsistent data.
Normalization helps in keeping data consistent by storing the data in one table and referencing it everywhere else.
Storage optimization although that is not an issue these days because Database storage is cheap.
Breaking down large tables into smaller tables with relationships, so it makes the database structure more scalable and adaptable.
Ensuring data dependencies make sense i.e. data is logically stored.
This video will give you a good overview of Database Normalization. If you want you can skip the video, as the concept is covered in this tutorial as well - Normalization in DBMS (YouTube Video) .
Problems without Normalization in DBMS
If a table is not properly normalized and has data redundancy(repetition) then it will not only eat up extra memory space but will also make it difficult for you to handle and update the data in the database, without losing data.
Insertion, Updation, and Deletion Anomalies are very frequent if the database is not normalized.
To understand these anomalies let us take an example of a Student table.
| rollno | name | branch | hod | office_tel |
|---|---|---|---|---|
| 401 | Akon | CSE | Mr. X | 53337 |
| 402 | Bkon | CSE | Mr. X | 53337 |
| 403 | Ckon | CSE | Mr. X | 53337 |
| 404 | Dkon | CSE | Mr. X | 53337 |
In the table above, we have data for four Computer Sci. students .
As we can see, data for the fields branch , hod (Head of Department), and office_tel are repeated for the students who are in the same branch in the college, this is Data Redundancy .
1. Insertion Anomaly in DBMS
Suppose for a new admission, until and unless a student opts for a branch, data of the student cannot be inserted, or else we will have to set the branch information as NULL .
Also, if we have to insert data for 100 students of the same branch, then the branch information will be repeated for all those 100 students.
These scenarios are nothing but Insertion anomalies .
If you have to repeat the same data in every row of data, it's better to keep the data separately and reference that data in each row.
So in the above table, we can keep the branch information separately, and just use the branch_id in the student table, where branch_id can be used to get the branch information.
2. Updation Anomaly in DBMS
What if Mr. X leaves the college? or Mr. X is no longer the HOD of the computer science department? In that case, all the student records will have to be updated, and if by mistake we miss any record, it will lead to data inconsistency.
This is an Updation anomaly because you need to update all the records in your table just because one piece of information got changed.
3. Deletion Anomaly in DBMS
In our Student table, two different pieces of information are kept together, the Student information and the Branch information .
So if only a single student is enrolled in a branch, and that student leaves the college, or for some reason, the entry for the student is deleted, we will lose the branch information too.
So never in DBMS, we should keep two different entities together, which in the above example is Student and branch,
The solution for all the three anomalies described above is to keep the student information and the branch information in two different tables. And use the branch_id in the student table to reference the branch.
Primary Key and Non-key attributes
Before we move on to learn different Normal Forms in DBMS, let's first understand what is a primary key and what are non-key attributes.

As you can see in the table above, the student_id column is a primary key because using the student_id value we can uniquely identify each row of data, hence the remaining columns then become the non-key attributes .
Types of DBMS Normal forms
Normalization rules are divided into the following normal forms:
First Normal Form
Second Normal Form
Third Normal Form
Fourth Normal Form
Fifth Normal Form
Let's cover all the Database Normal forms one by one with some basic examples to help you understand the DBMS normal forms.
1. First Normal Form (1NF)
For a table to be in the First Normal Form, it should follow the following 4 rules:
It should only have single( atomic ) valued attributes/columns.
Values stored in a column should be of the same domain.
All the columns in a table should have unique names.
And the order in which data is stored should not matter.
Watch this YouTube video to understand First Normal Form (if you like videos) - DBMS First Normal Form 1NF with Example
Let's see an example.
If we have an Employee table in which we store the employee information along with the employee skillset , the table will look like this:
| emp_id | emp_name | emp_mobile | emp_skills |
|---|---|---|---|
| 1 | John Tick | 9999957773 | Python, JavaScript |
| 2 | Darth Trader | 8888853337 | HTML, CSS, JavaScript |
| 3 | Rony Shark | 7777720008 | Java, Linux, C++ |
The above table has 4 columns:
All the columns have different names.
All the columns hold values of the same type like emp_name has all the names, emp_mobile has all the contact numbers, etc.
The order in which we save data doesn't matter
But the emp_skills column holds multiple comma-separated values , while as per the First Normal form, each column should have a single value.
Hence the above table fails to pass the First Normal form.
So how do you fix the above table? There are two ways to do this:
Remove the emp_skills column from the Employee table and keep it in some other table.
Or add multiple rows for the employee and each row is linked with one skill.
1. Create Separate tables for Employee and Employee Skills
So the Employee table will look like this,
| emp_id | emp_name | emp_mobile |
|---|---|---|
| 1 | John Tick | 9999957773 |
| 2 | Darth Trader | 8888853337 |
| 3 | Rony Shark | 7777720008 |
And the new Employee_Skill table:
| emp_id | emp_skill |
|---|---|
| 1 | Python |
| 1 | JavaScript |
| 2 | HTML |
| 2 | CSS |
| 2 | JavaScript |
| 3 | Java |
| 3 | Linux |
| 3 | C++ |
2. Add Multiple rows for Multiple skills
You can also simply add multiple rows to add multiple skills. This will lead to repetition of the data, but that can be handled as you further Normalize your data using the Second Normal form and the Third Normal form.
| emp_id | emp_name | emp_mobile | emp_skill |
|---|---|---|---|
| 1 | John Tick | 9999957773 | Python |
| 1 | John Tick | 9999957773 | JavaScript |
| 2 | Darth Trader | 8888853337 | HTML |
| 2 | Darth Trader | 8888853337 | CSS |
| 2 | Darth Trader | 8888853337 | JavaScript |
| 3 | Rony Shark | 7777720008 | Java |
| 3 | Rony Shark | 7777720008 | Linux |
| 3 | Rony Shark | 7777720008 | C++ |
If you want to learn about the First Normal Form in detail, check out DBMS First Normal Form tutorial.
2. Second Normal Form (2NF)
For a table to be in the Second Normal Form,
It should be in the First Normal form.
And, it should not have Partial Dependency .
Watch this YouTube video to understand Second Normal Form (if you like videos) - DBMS Second Normal Form 2NF with Example
Let's take an example to understand Partial dependency and the Second Normal Form.
What is Partial Dependency?
When a table has a primary key that is made up of two or more columns, then all the columns(not included in the primary key) in that table should depend on the entire primary key and not on a part of it. If any column(which is not in the primary key) depends on a part of the primary key then we say we have Partial dependency in the table.
Confused? Let's take an example.
If we have two tables Students and Subjects, to store student information and information related to subjects.
Student table:
| student_id | student_name | branch |
|---|---|---|
| 1 | Akon | CSE |
| 2 | Bkon | Mechanical |
Subject Table:
| subject_id | subject_name |
|---|---|
| 1 | C Language |
| 2 | DSA |
| 3 | Operating System |
And we have another table Score to store the marks scored by students in any subject like this,
| student_id | subject_id | marks | teacher_name |
|---|---|---|---|
| 1 | 1 | 70 | Miss. C |
| 1 | 2 | 82 | Mr. D |
| 2 | 1 | 65 | Mr. Op |
Now in the above table, the primary key is student_id + subject_id , because both these information are required to select any row of data.
But in the Score table, we have a column teacher_name , which depends on the subject information or just the subject_id , so we should not keep that information in the Score table.
The column teacher_name should be in the Subjects table. And then the entire system will be Normalized as per the Second Normal Form.
Updated Subject table:
| subject_id | subject_name | teacher_name |
|---|---|---|
| 1 | C Language | Miss. C |
| 2 | DSA | Mr. D |
| 3 | Operating System | Mr. Op |
Updated Score table:
| student_id | subject_id | marks |
|---|---|---|
| 1 | 1 | 70 |
| 1 | 2 | 82 |
| 2 | 1 | 65 |
To understand what is Partial Dependency and how you can normalize a table to 2nd normal form, jump to the DBMS Second Normal Form tutorial.
3. Third Normal Form (3NF)
A table is said to be in the Third Normal Form when,
It satisfies the First Normal Form and the Second Normal form.
And, it doesn't have Transitive Dependency.
Watch this YouTube video to understand the Third Normal Form (if you like videos) - DBMS Third Normal Form 3NF with Example
What is Transitive Dependency?
In a table we have some column that acts as the primary key and other columns depends on this column. But what if a column that is not the primary key depends on another column that is also not a primary key or part of it? Then we have Transitive dependency in our table.
Let's take an example. We had the Score table in the Second Normal Form above. If we have to store some extra information in it, like,
total_marks
To store the type of exam and the total marks in the exam so that we can later calculate the percentage of marks scored by each student.
The Score table will look like this,
| student_id | subject_id | marks | exam_type | total_marks |
|---|---|---|---|---|
| 1 | 1 | 70 | Theory | 100 |
| 1 | 2 | 82 | Theory | 100 |
| 2 | 1 | 42 | Practical | 50 |
In the table above, the column exam_type depends on both student_id and subject_id , because,
a student can be in the CSE branch or the Mechanical branch,
and based on that they may have different exam types for different subjects.
The CSE students may have both Practical and Theory for Compiler Design,
whereas Mechanical branch students may only have Theory exams for Compiler Design.
But the column total_marks just depends on the exam_type column. And the exam_type column is not a part of the primary key. Because the primary key is student_id + subject_id , hence we have a Transitive dependency here.
How to Transitive Dependency?
You can create a separate table for ExamType and use it in the Score table.
New ExamType table,
| exam_type_id | exam_type | total_marks | duration |
|---|---|---|---|
| 1 | Practical | 50 | 45 |
| 2 | Theory | 100 | 180 |
| 3 | Workshop | 150 | 300 |
We have created a new table ExamType and we have added more related information in it like duration (duration of exam in mins.), and now we can use the exam_type_id in the Score table.
Here is the DBMS Third Normal Form tutorial. But we suggest you first study the second normal form and then head over to the third normal form.
4. Boyce-Codd Normal Form (BCNF)
Boyce and Codd Normal Form is a higher version of the Third Normal Form.
This form deals with a certain type of anomaly that is not handled by 3NF.
A 3NF table that does not have multiple overlapping candidate keys is said to be in BCNF.
For a table to be in BCNF, the following conditions must be satisfied:
R must be in the 3rd Normal Form
and, for each functional dependency ( X → Y ), X should be a Super Key.
You can also watch our YouTube video to learn about BCNF - DBMS BCNF with Example
To learn about BCNF in detail with a very easy-to-understand example, head to the Boye-Codd Normal Form tutorial.
5. Fourth Normal Form (4NF)
A table is said to be in the Fourth Normal Form when,
It is in the Boyce-Codd Normal Form.
And, it doesn't have Multi-Valued Dependency.
You can also watch our YouTube video to learn about Fourth Normal Form - DBMS Fourth Normal Form 4NF with Example
Here is the Fourth Normal Form tutorial. But we suggest you understand other normal forms before you head over to the fourth normal form.
5. Fifth Normal Form (5NF)
The fifth normal form is also called the PJNF - Project-Join Normal Form
It is the most advanced level of Database Normalization.
Using Fifth Normal Form you can fix Join dependency and reduce data redundancy.
It also helps in fixing Update anomalies in DBMS design.
We have an amazing video to showcase the Fifth Normal Form with the help of Examples and to explain when it occurs and how you can fix it, check out the video on YouTube - Fifth Normal Form in DBMS
Here are some frequently asked questions related to the normalization in DBMS.
Q. Why do we need Normalization in DBMS?
Database Normalization helps you design and structure your table properly so that you have proper relationships between tables. It helps you with the following:
Data Integrity
Data consistency
Better relationship between tables
More scalable design for tables.
No large tables, small tables with a proper relationship.
Removing dependencies, like Partial Dependency, Transitive Dependency, Join Dependency, etc.
Q. What are the different Normal Forms in DBMS?
Following are the different Database Normal Forms:
First Normal Form also known as 1NF
Second Normal Form or 2NF
Third Normal Form or 3NF
Boyce-Codd Normal Form or BCNF
Fourth Normal Form or 4NF
Fifth Normal Form or 5NF or PJNF (Project-Join Normal Form)
Q. What is a Primary Key in DBMS?
A Primary key is a column that can be used to uniquely identify each row in a table. It can be a single column, or it can be multiple columns together. Yes, a primary key can have two columns or even more than two columns in it.
Q. What are non-key attribute in a Table?
All the columns that are not a primary key or not a part of the primary key are called as non-Key columns in a Table.
For example, if we have a table Students with columns student_id , student_name , student_address , and student_id is the primary key in this table, then student_name and student_address will be the non-Key attributes .
Q. What is the fullform of BCNF?
BCNF stands for Boyce-Codd Normal Form. BCNF is a higher version of the Third Normal Form.
Q. Is BCNF and Third Normal Form the same?
No. BCNF is a higher version of the Third Normal Form. The purpose of the Third Normal Form or 3NF is to remove Transitive dependency whereas BCNF is more strict than 3NF, and it focuses on removing all non-trivial functional dependencies.
Q. What is PJNF?
PJNF stands for Project-Join Normal Form. This is a name given to the Fifth Normal Form because the Fifth Normal Form or 5NF is used to fix Join dependency in tables.
Q. Which Normal Form is called PJNF?
The Fifth Normal Form is also known as PJNF or Project-Join Normal Form. The fifth normal form fixes the Join dependency in tables hence it is called PJNF. This is an advanced Normal form that helps in reducing Data redundancy and Updation anomaly.
- ← Prev
- Next →
DBMS MCQ Tests
practice sql queries.
- Engineering Mathematics
- Discrete Mathematics
- Operating System
- Computer Networks
- Digital Logic and Design
- C Programming
- Data Structures
- Theory of Computation
- Compiler Design
- Computer Org and Architecture
- System Design Tutorial
- System Design Interview Bootcamp - A Complete Guide
What is System Design
- What is Systems Design - Learn System Design
- System Design Life Cycle | SDLC (Design)
- What are the components of System Design?
- Goals and Objectives of System Design
- Why is it important to learn System Design?
- Important Key Concepts and Terminologies – Learn System Design
- Advantages of System Design
System Design Fundamentals
- Analysis of Monolithic and Distributed Systems - Learn System Design
- Structured Analysis and Structured Design (SA/SD)
- System Design Strategy - Software Engineering
- Database Sharding | System Design
- Horizontal and Vertical Scaling | System Design
- Load Balancer - System Design Interview Question
- Routing requests through Load Balancer
- Caching - System Design Concept
- Object-Oriented Analysis and Design(OOAD)
- 6 Steps To Approach Object-Oriented Design Questions in Interview
- Difference between Structured and Object-Oriented Analysis
- Communication Protocols In System Design
- Web Server, Proxies and their role in Designing Systems
Scalability in System Design
- What is Scalability and How to achieve it?
- Which Scalability approach is right for our Application? | System Design
- Primary Bottlenecks that Hurt the Scalability of an Application | System Design
Databases in Designing Systems
- Complete Reference to Databases in Designing Systems - Learn System Design
- SQL vs NoSQL: Which Database to Choose in System Design?
- File and Database Storage Systems in System Design
- Block, Object, and File Storage in Cloud with Difference
Normalization Process in DBMS
- Denormalization in Databases
High Level Design(HLD)
- What is High Level Design – Learn System Design
- Availability in System Design
- Consistency Model in Distributed System
- Reliability in System Design
- The CAP Theorem in DBMS
- Difference between Process and Thread
- Difference between Concurrency and Parallelism
- Activity Diagrams | Unified Modeling Language (UML)
Low Level Design(LLD)
- What is Low Level Design or LLD - Learn System Design
- Difference between Authentication and Authorization
- What is Data Encryption?
- Code Optimization in Compiler Design
- Unit Testing - Software Testing
- Integration Testing - Software Engineering
- CI/CD: Continuous Integration and Continuous Delivery
- Introduction to Modularity and Interfaces In System Design
- Unified Modeling Language (UML) Diagrams
- Data Partitioning Techniques in System Design
Testing and Quality Assurance
- Types of Software Testing
- Software Quality Assurance - Software Engineering
- Essential Security Measures in System Design
Interview Guide for System Design
- How to Crack System Design Interview Round
- Grokking Modern System Design Interview Guide
- System Design Interview Questions and Answers
- Most Commonly Asked System Design Interview Problems/Questions
- 5 Common System Design Concepts for Interview Preparation
- 5 Tips to Crack Low-Level System Design Interviews
System Design Interview Questions & Answers
- Design Dropbox - A System Design Interview Question
- Designing Twitter - A System Design Interview Question
- System Design Netflix | A Complete Architecture
- System Design of Uber App | Uber System Architecture
- Design BookMyShow - A System Design Interview Question
- Designing Facebook Messenger | System Design Interview
- Software Design Patterns Tutorial
- Complete Roadmap to Learn System Design for Beginners
Pre-Requisite: Introduction to Database Normalization
Database Normalization is a stepwise formal process that allows us to decompose database tables in such a way that both data dependency and update anomalies are minimized. It makes use of functional dependency that exists in the table and the primary key or candidate key in analyzing the tables. Normal forms were initially proposed called
- First Normal Form (INF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
Subsequently, R, Boyce, and E. F. Codd introduced a stronger definition of 3NF called Boyce-Codd Normal Form . With the exception of 1NF, all these normal forms are based on functional dependency among the attributes of a table. Higher normal forms that go beyond BCNF were introduced later such as Fourth Normal Form (4NF) and Fifth Normal Form (5NF) . However, these later normal forms deal with situations that are very rare.

Now, we are going to describe the process of Normalization by considering an Example. Let us look into that.
Normalization Process Example
In this example, we will look into that how we can normalize the database with the help of different Normal Forms. We will look into each of the Normal Forms separately in this example.
Consider the table 1 shown below:
| Naveen Kumar | IIT Delhi | DBMS, OS | Pass |
| Utkarsh Tiwari | IIT Bombay | CN. COA | Fail |
| Utkarsh Tiwari | IIT Kanpur | OS | Fail |
Now, we are re-structuring the table according to the 1st Normal Form .
Rules of 1st Normal Form
- Each table should contain a single value.
- Each record needs to be unique.
Table 1 after applying 1st Normal Form:
| Naveen Kumar | IIT Delhi | DBMS | Pass |
| Naveen Kumar | IIT Delhi | OS | Pass |
| Utkarsh Tiwari | IIT Bombay | CN | Fail |
| Utkarsh Tiwari | IIT Bombay | COA | Fail |
| Utkarsh Tiwari | IIT Kanpur | OS | Fail |
Consider the table 2 shown below,
| Utkarsh Tiwari | IIT Bombay | COA | Fail |
| Utkarsh Tiwari | IIT Kanpur | OS | Fail |
Here, People having the same name are from different institutes. So, we require Full Name and Institute to Identify a Row of the database. For this, we have to remove Partial Dependency .
Let’s look at the 2nd Normal Form.
Rules of 2nd Normal Form
- The table should be in 1NF.
- Primary Key does not functionally dependent on any subset of Candidate Key.
Table 1
| 1 | Naveen Kumar | IIT Delhi | Pass |
| 2 | Utkarsh Tiwari | IIT Bombay | Fail |
| 3 | Utkarsh Tiwari | IIT Kanpur | Fail |
Table 2
| 1 | DBMS |
| 1 | OS |
| 2 | CN |
| 2 | COA |
| 3 | OS |
Here, the Id in Table 2 is Foreign Key to the Id in Table 1 . Now, we have to remove Transitive Functional Dependency from our Table to Normalize our Database. A Transitive Functional Dependency basically tells us that there is an indirect relationship between functional dependency.
Now, let us look at the 3rd Normal Form .
Rules of 3rd Normal Form
- The tables should be in 2NF.
- There will be no Transitive Dependency.
Table 1
| 1 | Naveen Kumar | IIT Delhi | 1 |
| 2 | Utkarsh Tiwari | IIT Bombay | 2 |
| 3 | Utkarsh Tiwari | IIT Kanpur | 2 |
| 1 | Pass |
| 2 | Fail |
| 3 | On Hold |
Finally, Our Database is Normalized. From the above-mentioned example, we have reached our level of Normalization. In fact, there are also some higher forms or next levels of Normalization. Now, we are going to discuss them one by one.
Other Normal Forms
Boyce-codd normal form (bcnf).
Sometimes, when the database is in the 3rd Normal Form, there exist some anomalies in DBMS, like when more than one Candidate Keys is present in the Database. This has to be removed under BCNF . BCNF is also called 3.5NF.
4th Normal Form
Whenever a Database contains multivalued and independent data in two or more tables, then the database is to be considered in the 4th Normal Form.
5th Normal Form
Whenever a Database Table is not in 4NF, and we cannot divide it into smaller tables keeping our data safe with us, then our Database is in 5th Normal Form.
Summary of Normalization in a Nutshell
| Normal Form | Test | Remedy (Normalization) |
|---|---|---|
| 1NF | The relation should have no non-atomic attributes or nested relations. | Form a name relation for each non-atomic attribute or nested relation. |
| 2NF | For relations where the contains multiple attributes, no non-key attributes should be functionally dependent on a part of the primary key. | Decompose and set up a new relation for each partial key with its dependent attributes. Make sure to keep a relationship with the original primary key and any attributes that are fully functionally dependent on it. |
| 3NF | The relation should not have a non-key attribute functionally determined by another non-key attribute (or by a set of non-key attributes) i.e., there should be no transitive dependency of a non-key attribute of the primary key. | Decompose and set up a relation that includes the non-key attribute(s) that functionally determine(s) another non-key attribute (s). |
| BCNF | The relation should not have any attribute in Functional Dependency which is non-prime, the attribute that doesn’t occur in any candidate key. | Make sure that the left side of every functional dependency is a candidate key. |
| 4NF | The relation should not have a multi-value dependency means it occurs when two attributes of a table are independent of each other but both depend on a third attribute. | Decompose the table into two subtables. |
| 5NF | The relation should not have join dependency means if a table can be recreated by joining multiple tables and each of the tables has a subset of the attributes of the table, then the table is in Join Dependency | Decompose all the tables into as many as possible numbers in order to avoid dependency. |

Please Login to comment...
Similar reads.
- DBMS-Normalization
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
Build fully managed real-time data pipelines in minutes.

Connect&GO improves productivity 4x with Estuary.
True Platform discovered seamless, scalable data movement.
Soli & Company trusts Estuary’s approachable pricing and quick setup.

Data Normalization Explained: Types, Examples, & Methods
Discover the power of data normalization with our guide and learn about the different types of normalization and explore their examples..

Data quality is the key to success for any organization. If you don't have good data, you're essentially flying blind. Before you know it, productivity takes a hit, systems fail, and costs start to soar. IBM uncovered that poor data quality carries an annual price tag of $3.1 trillion for the U.S. economy. To combat these issues and boost your data quality, one of the most effective strategies is data normalization.
Data normalization is a versatile process aimed at minimizing errors and inconsistencies in data that can significantly undermine the efficiency and accuracy of data systems. It reduces redundancy and standardizes data to promote integrity and consistency across various fields, from database management to data analysis and machine learning.
In this guide, we'll break down the complex concept of data normalization and explore its types and applications to help you handle your data more effectively. But first, let's begin by discussing data anomalies.
- What Are Data Anomalies?
Data anomalies refer to inconsistencies or errors that occur when you deal with stored data. These anomalies can compromise the integrity of the data and cause inaccuracies that do not reflect the real-world scenario the data is meant to represent.
In databases, anomalies are typically because of redundancy or poor table construction. In data analysis and machine learning, anomalies can arise from missing values, incorrect data types, or unrealistic values.
Regardless of the context, anomalies can significantly impact the consistency and integrity of data. They can cause inaccurate analyses, misleading results, and poor decision-making . Therefore, identifying and addressing data anomalies is a crucial step in any data-driven process.
Exploring Data Anomalies: A Focus on Databases, Data Analysis & Machine Learning
Data anomalies can originate from a range of sources and their impact can vary, often causing substantial complications if not addressed properly. Let’s talk about 2 broad categories where these anomalies are most prevalent and can cause major issues.
Anomalies In Databases

Image Source
When it comes to databases, 3 primary types of data anomalies result from update, insertion, and deletion operations.
- Insertion anomalies: These occur when the addition of new data to the database is hindered because of the absence of other necessary data. This situation often arises in systems where specific dependencies between data elements exist.
- Update anomalies: This type of anomalies happen when modifications to the data end up causing inconsistencies. This usually occurs when the same piece of data is stored in multiple locations and changes aren't reflected uniformly across all instances.
- Deletion anomalies: You encounter these anomalies when you unintentionally lose other valuable information while removing certain data. This typically happens when multiple pieces of information are stored together and the deletion of one affects the others.
While the above anomalies are mainly related to the operations in databases and their design flaws, understand that anomalies are not limited to these aspects alone. They can very well be present in the data itself and can be a source of misleading analysis and interpretations. Let’s discuss these next.
Anomalies In Data Analysis & Machine Learning
In data analysis and machine learning, data anomalies can manifest as discrepancies in the values, types, or completeness of data which can significantly impact the outcome of analyses or predictive models. Let's examine some of the key anomalies that occur in this context:
- Missing values: These happen when data is not available for certain observations or variables.
- Incorrect data types: These anomalies occur when the data type of a variable does not match the expected data type. For example, a numeric variable might be recorded as a string.
- Unrealistic values: This type of anomaly arises when variables contain values that are not physically possible or realistic. For example, a variable representing human age might contain a value of 200.
Now, let's look at the basics of data normalization and its significance in handling data anomalies. This vital aspect of data management and analysis ensures a more efficient process by standardizing data, eliminating redundancies, and addressing undesirable input errors. By mitigating the impact of anomalies, data normalization plays an important role in achieving reliable results.
- Data Normalization: Understanding The Basics
Data normalization is an important aspect of data management and analysis that plays a crucial role in both data storage and data analysis. It is a systematic approach to decompose data tables to eliminate redundant data and undesirable characteristics.
The primary goal of data normalization is to add, delete, and modify data without causing data inconsistencies. It ensures that each data item is stored in only one place which reduces the overall disk space requirement and improves the consistency and reliability of the system.
In databases, it organizes fields and tables and in data analysis and machine learning, normalization is used to preprocess data before being used in any analysis.
Who Needs Data Normalization?
Data normalization has applications in a wide array of fields and professions. Its ability to streamline data storage, reduce data input error, and ensure consistency makes it an invaluable asset for anyone dealing with large datasets. Let’s discuss some of its use cases.
Data Normalization In Machine Learning
Data normalization is a standard preprocessing step in machine learning. ML engineers use it to standardize and scale their data which is very important to ensure that every feature has an equal impact on the prediction.
Data Normalization In Research
Researchers, particularly those in the field of science and engineering, often use data normalization in their work. Whether they're dealing with experimental data or large datasets, normalization helps to simplify their data , making it easier to analyze and interpret. They use it to eliminate potential distortions caused by differing scales or units and ensure that their findings are accurate and reliable.
Data Normalization In Business
In the business world, data normalization is often used in business intelligence and decision-making . Business analysts use normalization to prepare data for analysis , helping them to identify trends, make comparisons, and draw meaningful conclusions.
This helps in more informed business decisions and strategies to drive growth and success. Normalization also improves data consistency which results in better collaboration between different teams within the company.
- 4 Types Of Data Normalization In Databases

Data normalization in databases is a multi-stage process that involves the application of a series of rules known as 'normal forms'. Each normal form represents a level of normalization and comes with its own set of conditions that a database should meet.
These normal forms give a set of rules that a database should adhere to for achieving a certain level of normalization. The process starts with the first normal form (1NF) and can go up to the fifth normal form (5NF), each level addressing a specific type of data redundancy or anomaly. Let’s take a look at each one of them.
1. First Normal Form (1NF)
The first normal form (1NF) is the initial stage of data normalization. A database is in 1NF if it contains atomic values. This means that each cell in the database holds a single value and each record is unique . This stage eliminates duplicate data and ensures that each entry in the database has a unique identifier, enhancing data consistency.
2. Second Normal Form (2NF)
A database reaches the second normal form (2NF) if it is already in 1NF and all non-key attributes are fully functionally dependent on the primary key . In other words, there should be no partial dependencies in the database. This stage further reduces redundancy and ensures that each piece of data in the database is associated with the primary key which uniquely identifies each record.
3. Third Normal Form (3NF)
The third normal form (3NF) is achieved if a database is in 2NF and there are no transitive dependencies. This means that no non-primary key attribute should depend on another non-primary key attribute . This stage ensures that each non-key attribute of a table is directly dependent on the primary key and not on other non-key attributes.
4. Beyond 3NF
While most databases are considered normalized after reaching 3NF, there are further stages of normalization, including the fourth normal form (4NF) and fifth normal form (5NF). These stages deal with more complex types of data dependencies and are used when dealing with more complex datasets. In most cases, however, ensuring data integrity and efficiency at the 3NF level is already sufficient.
3 Examples Of Data Normalization In Databases
To better understand these concepts, let's look into some practical examples of data normalization in databases.
A. First Normal Form (1NF) Example
Consider an employee table where employees are associated with multiple departments. The table is not in 1NF because it contains non-atomic values, i.e., cells with more than one value.
Employee Table

To achieve 1NF, we must split the data in the 'Department' column into 2 records , one for each department, so that each record in the table contains a single value.
Employee Table in 1NF

B. Second Normal Form (2NF) Example
Consider a Products table where the 'product' and 'brand' attributes are not fully dependent on the composite primary key 'productID' and 'brandID'.
Products Table

To bring the table to 2NF, we split the table into 3, where each non-key attribute is fully functionally dependent on the primary key.
Products Category Table

Brand Table

Products Brand Table

In the 'Product-Brand Link' table, each row represents a product-brand pair from the original table. This table effectively links the 'Products Category' table and the 'Brand' table, ensuring that the relationship between products and brands is maintained . Here’s the schema:

C. Third Normal Form (3NF) Example
Consider an Employee table where 'Salary' is dependent on 'Salary Slip No', which is not a primary key. This is a transitive dependency that is not allowed in 3NF.

To bring the table to 3NF, we split the table into 2 wherein each separate table, no non-primary key attribute depends on another non-primary key attribute.
Employee Table in 3NF

Salary Table

Data Normalization In Data Analysis & Machine Learning

In data analysis and machine learning workflows, data normalization is a pre-processing step. It adjusts the scale of data and ensures that all variables in a dataset are on a similar scale. This uniformity is important as it prevents any single variable from overshadowing others .
For machine learning algorithms that rely on distance or gradient-based methods, normalized data is especially key. It helps these algorithms to function optimally and leads to the creation of models that are accurate, reliable, and unbiased. This ultimately enhances the quality of insights derived from the data.
3 Normalization Techniques & Formulas
Data analysis and machine learning use several techniques for normalizing data. Let’s discuss the 3 most commonly used methods.
Min-Max Normalization
This technique performs a linear transformation on the original data . Each value is replaced according to a formula that considers the minimum and maximum values of the data. The goal is to scale the data to a specific range, such as [0.0, 1.0]. The formula for min-max normalization is:

Z-Score Normalization
Also known as Zero mean normalization or standardization, this technique normalizes values based on the mean and standard deviation of the data . Each value is replaced by a score that indicates how many standard deviations it is from the mean. You can apply Z-score normalization using the following formula:

Decimal Scaling Normalization
This technique normalizes by moving the decimal point of values of the data . Each value of the data is divided by the maximum absolute value of the data, resulting in values typically in the range of -1 to 1. The formula for this simple normalization technique is:

3 Examples Of Data Normalization In Data Analysis & Machine Learning
Let’s apply the normalization techniques discussed above to real-world data. This can help us uncover the tangible effects they have on data transformation . We will use the Iris dataset which is a popular dataset in the field of machine learning. This dataset consists of 150 samples from 3 species of Iris flowers.
Here’s how you can import the data in Python:
Here’s a sample of the dataset:

Min-Max Normalization Example
Min-Max normalization is a simple yet effective method to rescale features to a specific range , typically 0 to 1. Here is how you can perform Min-Max normalization using Python and Scikit-learn:
When we apply Min-Max normalization to the Iris dataset, we get:

Z-score Normalization Example
Z-score normalization, or standardization, centers the data with a mean of 0 and a standard deviation of 1 . Here's an example of how to perform Z-score normalization:
Z-score normalization of the Iris dataset gives:

Decimal Scaling Normalization Example
Decimal scaling normalization is particularly useful when the maximum absolute value of a feature is known . Here's a simple Python example of decimal scaling normalization:
The decimal scaling normalization code above first checks the order of the largest value in the dataset and then divides the entire dataset by it. Here’s the result:

The scales of the features in each of the 3 normalized datasets are much closer to each other than in the original dataset. This helps to ensure that all features contribute equally to the final result.
- How Estuary Can Help With Data Normalization

Estuary Flow is a real-time data pipeline platform designed to facilitate the seamless ingestion, integration, and transformation of data in real time. It provides a robust infrastructure that lets users build and manage data pipelines with ease, ensuring that data is always up-to-date and readily available for analysis.
Flow is built on a foundation of open-source technologies and offers a unique approach to data management that combines the best aspects of traditional databases and modern streaming systems. Flow's architecture is designed to handle both batch and real-time data , making it a versatile tool for a wide range of applications.
One of the key ingredients of Flow is its use of collections , which are essentially real-time data lakes of JSON documents stored in cloud storage. These collections can either be captured from an external system or derived as a transformation of one or more other collections. This provides a flexible and efficient way to manage and normalize data.
Here are some of the key features of Flow that can support data normalization:
- Default annotations: It uses default annotations to prevent null values from being materialized to your endpoint system, ensuring data consistency.
- Real-time transformations: Flow supports SQL and Typescript for data manipulation, including functions like AVG(), MIN(), MAX(), and STDDEV() that can be used for data normalization.
- Projections: It uses projections to translate between the documents of a collection and a table representation. This feature is particularly useful when dealing with systems that model flat tables of rows and columns.
- Logical partitions: It allows you to logically partition a collection, isolating the storage of documents by their differing values for partitioned fields. This can help improve the efficiency of data storage and retrieval.
- Real-time data processing: It processes data in real-time which ensures that your normalized data is always up-to-date. This is particularly useful for applications that require immediate insights from the data.
- Reductions: Flow can merge multiple documents with a common key into a single document using customizable reduction strategies.
- Schema management: It uses JSON Schema to define your data’s structure, representation, and constraints. This allows for robust data validation and ensures that your data is clean and valid before it's stored or processed.
- Flexible data ingestion: Flow allows for the ingestion of data from a wide array of sources, including databases, cloud storage, and message queues. This flexibility makes it easier to bring in data from various sources for normalization.
Data normalization is a critical process in data management and analysis that ensures the integrity and reliability of data. However, the process can be complex and time-consuming, especially when dealing with large datasets and various types of anomalies.
This is where Estuary Flow comes in. It facilitates seamless real-time data operations and ensures that your data is always up-to-date and ready for analysis. With features like schema management and support for data manipulation functions, Flow can streamline the data normalization process.
So, if you're looking for a platform to simplify your data normalization process, you can explore Estuary Flow for free by signing up here or reaching out to our team to discuss your specific needs.
Start streaming your data for free
In this article
- Data Normalization In Data Analysis & Machine Learning
Popular Articles

ChatGPT for Sales Conversations: Building a Smart Dashboard

Why You Should Reconsider Debezium: Challenges and Alternatives

Don't Use Kafka as a Data Lake. Do This Instead.
Streaming pipelines., simple to deploy., simply priced..

Snapsolve any problem by taking a picture. Try it in the Numerade app?
Database Systems - A Pract Appr to Design, Impl, Mgmt
T. connolly, c. begg, normalization - all with video answers.
Chapter Questions
Describe the purpose of normalizing data.
Discuss the alternative ways that normalization can be used to support database design.
Describe the types of update anomaly that may occur on a relation that has redundant data.
Describe the concept of functional dependency.
What are the main characteristics of functional dependencies that are used for normalization?
Describe how a database designer typically identifies the set of functional dependencies associated with a relation.
Describe the characteristics of a table in Unnormalized Form (UNF) and describe how such a table is converted to a First Normal Form (1NF) relation.
What is the minimal normal form that a relation must satisfy? Provide a definition for this normal form.
Describe the two approaches to converting an Unnormalized Form (UNF) table to First Normal Form (1NF) relation(s).
Describe the concept of full functional dependency and describe how this concept relates to $2 \mathrm{NF}$. Provide an example to illustrate your answer.
Describe the concept of transitive dependency and describe how this concept relates to $3 \mathrm{NF}$. Provide an example to illustrate your answer.
Discuss how the definitions of 2NF and 3NF based on primary keys differ from the general definitions of $2 \mathrm{NF}$ and $3 \mathrm{NF}$. Provide an example to illustrate your answer.
Continue the process of normalizing the Client and PropertyRentalOwner 1NF relations shown in Figure 13.13 to $3 \mathrm{NF}$ relations. At the end of this process check that the resultant $3 \mathrm{NF}$ relations are the same as those produced from the alternative ClientRental 1NF relation shown in Figure 13.16.
Examine the Patient Medication Form for the Wellmeadows Hospital case study shown in Figure 13.18. (a) Identify the functional dependencies represented by the attributes shown in the form in Figure 13.18. State any assumptions you make about the data and the attributes shown in this form. (b) Describe and illustrate the process of normalizing the attributes shown in Figure 13.18 to produce a set of well-designed $3 \mathrm{NF}$ relations. (c) Identify the primary, alternate, and foreign keys in your $3 \mathrm{NF}$ relations.
The table shown in Figure 13.19 lists sample dentist/patient appointment data. A patient is given an appointment at a specific time and date with a dentist located at a particular surgery. On each day of patient appointments, a dentist is allocated to a specific surgery for that day. (a) The table shown in Figure 13.19 is susceptible to update anomalies. Provide examples of insertion, deletion, and update anomalies. (b) Identify the functional dependencies represented by the attributes shown in the table of Figure 13.19. State any assumptions you make about the data and the attributes shown in this table. (c) Describe and illustrate the process of normalizing the table shown in Figure 13.19 to $3 \mathrm{NF}$ relations. Identify the primary, alternate, and foreign keys in your $3 \mathrm{NF}$ relations.
An agency called Instant Cover supplies part-time/temporary staff to hotels within Scotland. The table shown in Figure 13.20 displays sample data, which lists the time spent by agency staff working at various hotels. The National Insurance Number (NIN) is unique for every member of staff. (a) The table shown in Figure 13.20 is susceptible to update anomalies. Provide examples of insertion, deletion, and update anomalies. (b) Identify the functional dependencies represented by the attributes shown in the table of Figure 13.20. State any assumptions you make about the data and the attributes shown in this table. (c) Describe and illustrate the process of normalizing the table shown in Figure 13.20 to 3NF. Identify primary, alternate and foreign keys in your relations.
IMAGES
VIDEO
COMMENTS
To understand (DBMS)normalization with example tables, let's assume that we are storing the details of courses and instructors in a university. Here is what a sample database could look like: Course code. Course venue. Instructor Name. Instructor's phone number. CS101. Lecture Hall 20. Prof. George.
This means that normalization in a DBMS (Database Management System) can be done in Oracle, Microsoft SQL Server, MySQL, PostgreSQL and any other type of database. To perform the normalization process, you start with a rough idea of the data you want to store, and apply certain rules to it in order to get it to a more efficient form.
Types of Normal Forms in DBMS. Here is a list of Normal Forms in SQL: 1NF (First Normal Form): Ensures that the database table is organized such that each column contains atomic (indivisible) values, and each record is unique. This eliminates repeating groups, thereby structuring data into tables and columns. 2NF (Second Normal Form): Builds on ...
There are several stages of the normalization process. The three main stages are: First normal form. Second normal form. Third normal form. A database is said to be normalized if it meets the rules specified in "third normal form", which is the third stage of the DBMS normalization process.
Conclusion. Database normalization is a critical process in database design, aimed at optimizing data storage, improving data integrity, and reducing data anomalies. By organizing data into normalized tables, you can enhance the efficiency and maintainability of your database system. Remember that achieving higher normal forms, such as BCNF and ...
Database normalization is the process of organizing a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by Edgar F. Codd. "Normal Forms" (NF) are the different stages of Normalization in DBMS:
1NF, 2NF, and 3NF are the first three types of database normalization. They stand for first normal form, second normal form, and third normal form, respectively. There are also 4NF (fourth normal form) and 5NF (fifth normal form). There's even 6NF (sixth normal form), but the commonest normal form you'll see out there is 3NF (third normal ...
About this article. In this article, we use one of the entities from our case study and perform a database normalization example. We start with the products table, unnormalized, and progress through the first, second, and third normal forms.Finally, we show the results of applying the same techniques to the entire Entity Relationship Diagram for our online store.
Database normalization is like the art of organizing a library. It's a systematic approach to reducing data redundancy and improving data integrity. By following a set of rules (normal forms ...
According to the definition in Wikipedia -. " Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce ...
Normalization is the branch of relational theory that provides design insights. It is the process of determining how much redundancy exists in a table. The goals of normalization are to: Normalization theory draws heavily on the theory of functional dependencies. Normalization theory defines six normal forms (NF).
Database normalization is the process of organizing data in a database to reduce data redundancy and improve data integrity. This practical guide covers the basics of normalization, including the different normal forms such as 1NF, 2NF, and 3NF, and provides examples of unnormalized and normalized databases. It also explains how normalization ...
Normalization is the process to eliminate data redundancy and enhance data integrity in the table. Normalization also helps to organize the data in the database. It is a multi-step process that sets the data into tabular form and removes the duplicated data from the relational tables. Normalization organizes the columns and tables of a database ...
Updated March 7, 2024. This Tutorial will Explain what is Database Normalization and various Normal Forms like 1NF 2NF 3NF and BCNF With SQL Code Examples: Database Normalization is a well-known technique used for designing database schema. The main purpose of applying the normalization technique is to reduce the redundancy and dependency of data.
This discussion is all about Database Normalization: Explain 1NF, 2NF, 3NF, BCNF With Examples. At the end of this article, you will be given a free pdf copy of all these Normalization forms. Normalization can be mainly classified into 4 types: 1) 1st Normal Form. 2) 2nd Normal Form. 3) 3rd Normal Form. 4) 4th Normal Form. 5) 5th Normal Form, and.
Following are the various types of Normal forms: Normal Form. Description. 1NF. A relation is in 1NF if it contains an atomic value. 2NF. A relation will be in 2NF if it is in 1NF and all non-key attributes are fully functional dependent on the primary key. 3NF. A relation will be in 3NF if it is in 2NF and no transition dependency exists.
DBMS Normalization is a systematic approach to decompose (break down) tables to eliminate data redundancy (repetition) and undesirable characteristics like Insertion anomaly in DBMS, Update anomaly in DBMS, and Delete anomaly in DBMS. It is a multi-step process that puts data into tabular form, removes duplicate data, and set up the ...
In database management systems (DBMS), normal forms are a series of guidelines that help to ensure that the design of a database is efficient, organized, and free from data anomalies. There are several levels of normalization, each with its own set of guidelines, known as normal forms. Important Points Regarding Normal Forms in DBMS.
Normalization: Normalization is the method used in a database to reduce the data redundancy and data inconsistency from the table. It is the technique in which Non-redundancy and consistency data are stored in the set schema. By using normalization the number of tables is increased instead of decreased. Denormalization: Denormalization is also the
Data Normalization: Understanding The Basics. Data normalization is an important aspect of data management and analysis that plays a crucial role in both data storage and data analysis. It is a systematic approach to decompose data tables to eliminate redundant data and undesirable characteristics.
The table shown in Figure 13.20 displays sample data, which lists the time spent by agency staff working at various hotels. The National Insurance Number (NIN) is unique for every member of staff. (a) The table shown in Figure 13.20 is susceptible to update anomalies. Provide examples of insertion, deletion, and update anomalies.
Chapter-9 Normalization. Mar 16, 2021 • Download as PPTX, PDF •. 0 likes • 182 views. Kunal Anand. Follow. This chapter deals with the importance of normalization in database management systems. We learn about the necessary criterion needed for normalization. We discuss different types of normal forms along with some sample examples.
1 DO NOT INCLUDE the calculated attributes/fields ( Line Total , Subtotal , Sales Tax and Total ) in your normalization diagrams or. queries. Page 2 of 3. To transform unnormalized relations into first normal form, we can create a relation that uses a composite key, then enter new invoice data for each customer into a new row.